iMotion-LLM: Motion Prediction Instruction Tuning
2406.06211
0
0

Abstract
We introduce iMotion-LLM: a Multimodal Large Language Models (LLMs) with trajectory prediction, tailored to guide interactive multi-agent scenarios. Different from conventional motion prediction approaches, iMotion-LLM capitalizes on textual instructions as key inputs for generating contextually relevant trajectories. By enriching the real-world driving scenarios in the Waymo Open Dataset with textual motion instructions, we created InstructWaymo. Leveraging this dataset, iMotion-LLM integrates a pretrained LLM, fine-tuned with LoRA, to translate scene features into the LLM input space. iMotion-LLM offers significant advantages over conventional motion prediction models. First, it can generate trajectories that align with the provided instructions if it is a feasible direction. Second, when given an infeasible direction, it can reject the instruction, thereby enhancing safety. These findings act as milestones in empowering autonomous navigation systems to interpret and predict the dynamics of multi-agent environments, laying the groundwork for future advancements in this field.
Create account to get full access
Overview
- The paper introduces "iMotion-LLM," a motion prediction system that uses large language models (LLMs) to enhance motion prediction tasks.
- The core idea is to "tune" LLMs with instruction-based learning to improve their performance on motion prediction.
- The paper also presents "InstructWaymo," a dataset that augments the Waymo Open Dataset with natural language instructions to support this instruction-tuning approach.
Plain English Explanation
The researchers behind this work recognized that while large language models (LLMs) like GPT-3 have shown impressive capabilities across many tasks, they haven't been widely used for motion prediction - the ability to forecast how people and objects will move in the future. The team wanted to explore whether they could leverage the power of LLMs to enhance motion prediction performance.
Their key insight was that by "tuning" or fine-tuning an LLM with instruction-based learning, they could teach the model to better understand and reason about motion. The idea is that providing the model with natural language instructions about how to predict motion would help it learn the relevant concepts and skills more effectively.
To support this approach, the researchers also created a new dataset called "InstructWaymo" which builds on the existing Waymo Open Dataset of motion data. InstructWaymo adds natural language instructions that describe the motion events in the dataset, giving the LLM more context to learn from.
By combining this instruction-based training approach with the capabilities of large language models, the researchers hope to advance the state-of-the-art in motion prediction, with potential applications in areas like autonomous vehicles, robotics, and animation.
Technical Explanation
The core of the iMotion-LLM system is the process of "instruction tuning" - fine-tuning a pre-trained LLM like GPT-3 on a dataset of motion prediction tasks paired with natural language instructions. This allows the model to learn the relevant concepts and skills for motion prediction more effectively than just training on motion data alone.
The researchers created the InstructWaymo dataset to support this approach. InstructWaymo augments the existing Waymo Open Dataset of motion trajectories with natural language instructions that describe the motion events. For example, an instruction might say "Predict the future trajectory of the pedestrian as they walk across the crosswalk."
By training the LLM on this instruction-augmented dataset, the model learns to associate the natural language instructions with the corresponding motion prediction tasks. This teaches the LLM to understand the underlying principles of motion and how to apply that knowledge to make accurate predictions.
The researchers evaluated iMotion-LLM on standard motion prediction benchmarks and found that it outperformed previous state-of-the-art models. They attribute this improved performance to the instruction tuning process, which enables the LLM to better grasp the semantics and physics of motion.
Critical Analysis
The authors acknowledge several limitations of their work. First, the instruction-tuning approach relies on having a high-quality dataset of motion events paired with natural language descriptions, which can be labor-intensive to create. The performance of iMotion-LLM is also likely dependent on the quality and coverage of the InstructWaymo dataset.
Additionally, the paper does not delve into the interpretability or explainability of the iMotion-LLM system. As a large language model, it may be difficult to understand the internal reasoning behind its motion predictions, which could be a barrier to real-world deployment in safety-critical applications.
Further research could explore ways to make the instruction-tuning process more scalable, as well as investigate techniques to improve the transparency and accountability of the motion prediction model. Evaluating iMotion-LLM on more diverse motion scenarios beyond the Waymo dataset would also help validate its generalization capabilities.
Conclusion
The iMotion-LLM paper presents a novel approach to leveraging large language models for the task of motion prediction. By "tuning" the LLM with instruction-based learning, the researchers were able to significantly improve its performance on standard motion prediction benchmarks.
This work demonstrates the potential of combining the power of LLMs with domain-specific knowledge, in this case, the principles of motion and kinematics. If further developed, iMotion-LLM and similar instruction-tuning techniques could lead to more robust and capable motion prediction systems, with applications in areas like autonomous vehicles, robotics, and animation.
The creation of the InstructWaymo dataset is also a valuable contribution, as it provides a new resource for researchers to explore instruction-based learning for motion-related tasks. Overall, this paper offers an intriguing glimpse into the future of how large language models can be adapted and applied to solve complex real-world problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MotionLLM: Multimodal Motion-Language Learning with Large Language Models
Qi Wu, Yubo Zhao, Yifan Wang, Yu-Wing Tai, Chi-Keung Tang
0
0
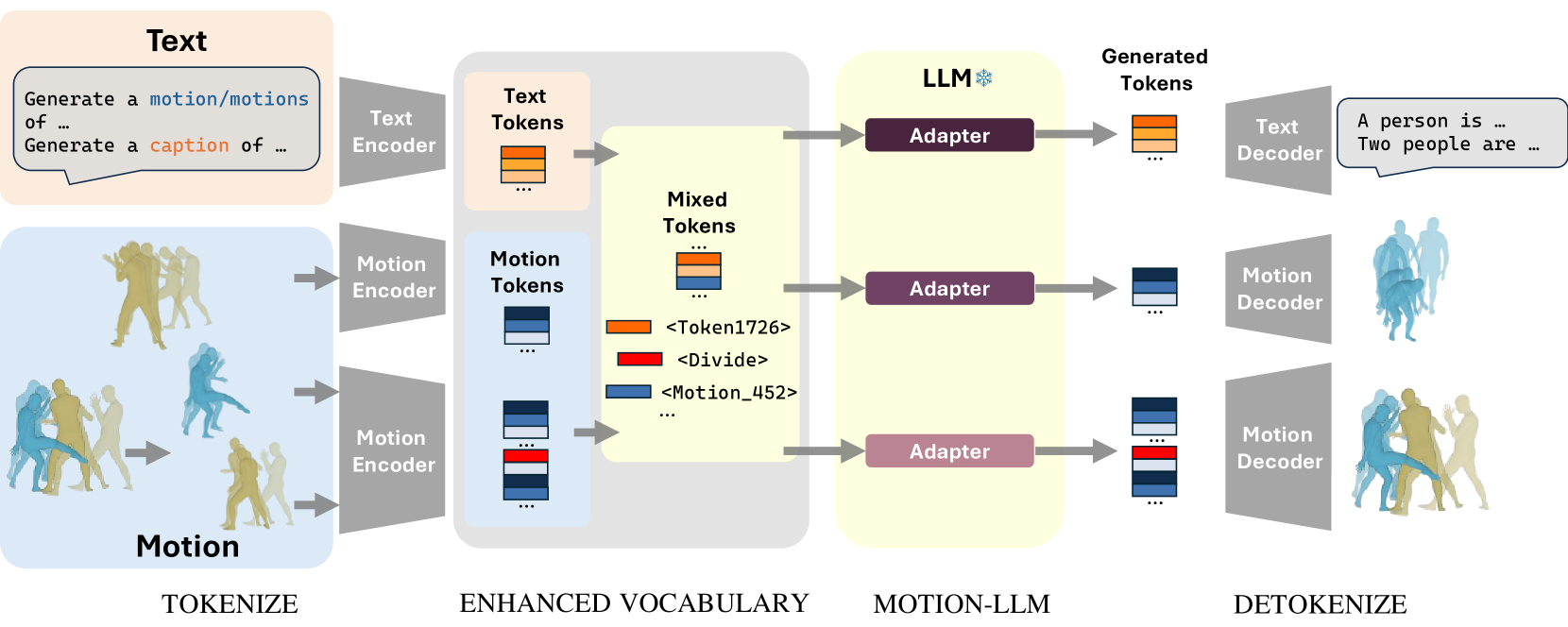
Recent advancements in Multimodal Large Language Models (MM-LLMs) have demonstrated promising potential in terms of generalization and robustness when applied to different modalities. While previous works have already achieved 3D human motion generation using various approaches including language modeling, they mostly % are mostly carefully designed use specialized architecture and are restricted to single-human motion generation. Inspired by the success of MM-LLMs, we propose MotionLLM, a simple and general framework that can achieve single-human, multi-human motion generation, and motion captioning by fine-tuning pre-trained LLMs. Specifically, we encode and quantize motions into discrete LLM-understandable tokens, which results in a unified vocabulary consisting of both motion and text tokens. With only 1--3% parameters of the LLMs trained by using adapters, our single-human motion generation achieves comparable results to those diffusion models and other trained-from-scratch transformer-based models. Additionally, we show that our approach is scalable and flexible, allowing easy extension to multi-human motion generation through autoregressive generation of single-human motions. Project page: https://knoxzhao.github.io/MotionLLM
5/29/2024
🔮
Traj-LLM: A New Exploration for Empowering Trajectory Prediction with Pre-trained Large Language Models
Zhengxing Lan, Hongbo Li, Lingshan Liu, Bo Fan, Yisheng Lv, Yilong Ren, Zhiyong Cui
0
0
Predicting the future trajectories of dynamic traffic actors is a cornerstone task in autonomous driving. Though existing notable efforts have resulted in impressive performance improvements, a gap persists in scene cognitive and understanding of the complex traffic semantics. This paper proposes Traj-LLM, the first to investigate the potential of using Large Language Models (LLMs) without explicit prompt engineering to generate future motion from agents' past/observed trajectories and scene semantics. Traj-LLM starts with sparse context joint coding to dissect the agent and scene features into a form that LLMs understand. On this basis, we innovatively explore LLMs' powerful comprehension abilities to capture a spectrum of high-level scene knowledge and interactive information. Emulating the human-like lane focus cognitive function and enhancing Traj-LLM's scene comprehension, we introduce lane-aware probabilistic learning powered by the pioneering Mamba module. Finally, a multi-modal Laplace decoder is designed to achieve scene-compliant multi-modal predictions. Extensive experiments manifest that Traj-LLM, fortified by LLMs' strong prior knowledge and understanding prowess, together with lane-aware probability learning, outstrips state-of-the-art methods across evaluation metrics. Moreover, the few-shot analysis further substantiates Traj-LLM's performance, wherein with just 50% of the dataset, it outperforms the majority of benchmarks relying on complete data utilization. This study explores equipping the trajectory prediction task with advanced capabilities inherent in LLMs, furnishing a more universal and adaptable solution for forecasting agent motion in a new way.
5/9/2024

MotionLLM: Understanding Human Behaviors from Human Motions and Videos
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, Lei Zhang
0
0
This study delves into the realm of multi-modality (i.e., video and motion modalities) human behavior understanding by leveraging the powerful capabilities of Large Language Models (LLMs). Diverging from recent LLMs designed for video-only or motion-only understanding, we argue that understanding human behavior necessitates joint modeling from both videos and motion sequences (e.g., SMPL sequences) to capture nuanced body part dynamics and semantics effectively. In light of this, we present MotionLLM, a straightforward yet effective framework for human motion understanding, captioning, and reasoning. Specifically, MotionLLM adopts a unified video-motion training strategy that leverages the complementary advantages of existing coarse video-text data and fine-grained motion-text data to glean rich spatial-temporal insights. Furthermore, we collect a substantial dataset, MoVid, comprising diverse videos, motions, captions, and instructions. Additionally, we propose the MoVid-Bench, with carefully manual annotations, for better evaluation of human behavior understanding on video and motion. Extensive experiments show the superiority of MotionLLM in the caption, spatial-temporal comprehension, and reasoning ability.
5/31/2024
Instruct Large Language Models to Drive like Humans
Ruijun Zhang, Xianda Guo, Wenzhao Zheng, Chenming Zhang, Kurt Keutzer, Long Chen
0
0
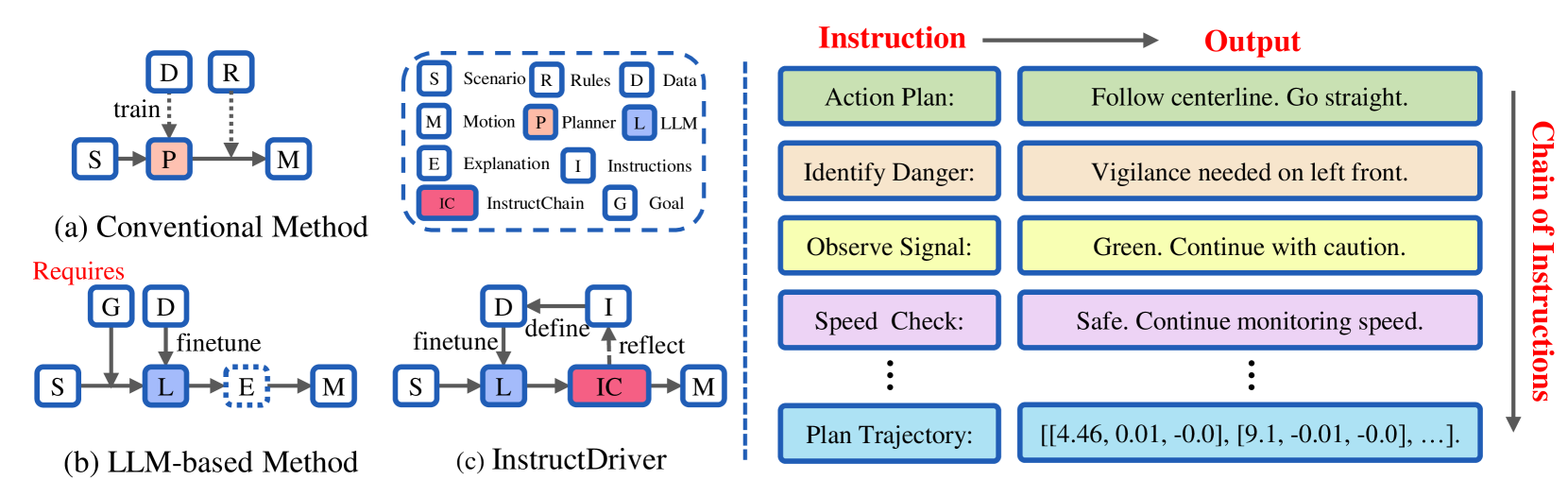
Motion planning in complex scenarios is the core challenge in autonomous driving. Conventional methods apply predefined rules or learn from driving data to plan the future trajectory. Recent methods seek the knowledge preserved in large language models (LLMs) and apply them in the driving scenarios. Despite the promising results, it is still unclear whether the LLM learns the underlying human logic to drive. In this paper, we propose an InstructDriver method to transform LLM into a motion planner with explicit instruction tuning to align its behavior with humans. We derive driving instruction data based on human logic (e.g., do not cause collisions) and traffic rules (e.g., proceed only when green lights). We then employ an interpretable InstructChain module to further reason the final planning reflecting the instructions. Our InstructDriver allows the injection of human rules and learning from driving data, enabling both interpretability and data scalability. Different from existing methods that experimented on closed-loop or simulated settings, we adopt the real-world closed-loop motion planning nuPlan benchmark for better evaluation. InstructDriver demonstrates the effectiveness of the LLM planner in a real-world closed-loop setting. Our code is publicly available at https://github.com/bonbon-rj/InstructDriver.
6/12/2024