The Impact of Prompts on Zero-Shot Detection of AI-Generated Text
2403.20127
0
0

Abstract
In recent years, there have been significant advancements in the development of Large Language Models (LLMs). While their practical applications are now widespread, their potential for misuse, such as generating fake news and committing plagiarism, has posed significant concerns. To address this issue, detectors have been developed to evaluate whether a given text is human-generated or AI-generated. Among others, zero-shot detectors stand out as effective approaches that do not require additional training data and are often likelihood-based. In chat-based applications, users commonly input prompts and utilize the AI-generated texts. However, zero-shot detectors typically analyze these texts in isolation, neglecting the impact of the original prompts. It is conceivable that this approach may lead to a discrepancy in likelihood assessments between the text generation phase and the detection phase. So far, there remains an unverified gap concerning how the presence or absence of prompts impacts detection accuracy for zero-shot detectors. In this paper, we introduce an evaluative framework to empirically analyze the impact of prompts on the detection accuracy of AI-generated text. We assess various zero-shot detectors using both white-box detection, which leverages the prompt, and black-box detection, which operates without prompt information. Our experiments reveal the significant influence of prompts on detection accuracy. Remarkably, compared with black-box detection without prompts, the white-box methods using prompts demonstrate an increase in AUC of at least $0.1$ across all zero-shot detectors tested. Code is available: url{https://github.com/kaito25atugich/Detector}.
Create account to get full access
Overview
- This paper explores how the wording of prompts can impact the ability of AI-based text detection models to identify if a given text was generated by AI.
- The researchers conducted experiments to understand how different prompts affect the performance of zero-shot AI text detection, where the model is not fine-tuned on specific datasets.
- The findings suggest that the choice of prompts can significantly influence the accuracy of AI text detection, highlighting the importance of prompt design in this emerging field.
Plain English Explanation
The paper examines how the way a question or instruction (known as a "prompt") is phrased can affect the ability of AI systems to detect if a piece of text was generated by another AI, rather than written by a human. This is an important capability, as AI-generated text is becoming more common and can potentially be used to spread misinformation or automate content creation.
The researchers tested different prompts with AI-based text detection models to see how the wording impacts the models' accuracy in identifying AI-generated text. For example, a prompt like "Determine if this text was written by a human or an AI" may produce different results than a prompt like "Evaluate if this passage exhibits signs of AI-generated content."
The key insight is that the choice of prompt matters a lot - certain phrasings can make it much easier or harder for the AI detection models to correctly classify the text. This highlights the importance of carefully designing prompts when using these AI systems in real-world applications, such as content moderation or verifying the authenticity of online information.
Technical Explanation
The paper examines the impact of prompts on zero-shot detection of AI-generated text. Zero-shot detection refers to the ability of AI models to identify AI-generated text without being fine-tuned on specific datasets. The researchers conducted experiments using the InstructGPT language model as the text classifier and a variety of prompts to evaluate their impact on detection performance.
The prompts tested varied in their wording, framing, and level of specificity. For example, some prompts directly asked the model to determine if the text was human or AI-generated, while others used more indirect framings like assessing the text for "signs of AI generation." The results showed that the choice of prompt had a significant effect on the model's accuracy, with some phrasings leading to substantially higher or lower detection rates.
The authors hypothesize that this is due to the language model's sensitivity to prompt wording, which can influence factors like the information the model focuses on, its reasoning process, and overall confidence in the classification. They provide analysis and discussion of the mechanisms by which prompts impact zero-shot detection performance.
The findings highlight the importance of prompt design in AI-based text detection systems, as the accuracy and reliability of these models can be heavily influenced by the way queries are framed. The research suggests that future work should explore systematic methods for optimizing prompts to enhance the robustness and generalization of AI text detection capabilities.
Critical Analysis
The paper provides valuable insights into an important practical challenge in the deployment of AI-based text detection systems. The experimental setup and analysis are rigorous, and the findings clearly demonstrate the significant impact that prompt wording can have on model performance.
One limitation noted by the authors is that the study focuses on a single language model (InstructGPT) and a limited set of prompts. While the principles identified likely apply more broadly, further research is needed to validate the generalizability of the results across different model architectures and prompt formulations.
Additionally, the paper does not explore the potential reasons why certain prompts may be more effective than others in eliciting accurate AI text detection. A deeper investigation into the cognitive and linguistic factors underlying prompt sensitivity could lead to more systematic approaches for designing optimal prompts.
Another area for future work is to understand how prompt-sensitivity may vary across different text generation tasks and datasets. The impact of prompts on zero-shot detection may differ depending on factors like the complexity of the generated content, the diversity of the training data, and the specific capabilities of the language model.
Overall, this research highlights an important practical challenge that must be addressed to ensure the reliable and responsible deployment of AI-based text detection systems. The findings provide a strong foundation for further investigations into prompt engineering and its implications for the field of AI-generated content analysis.
Conclusion
This paper makes a significant contribution to understanding the impact of prompts on the zero-shot detection of AI-generated text. The experimental results demonstrate that the wording and framing of prompts can have a substantial influence on the accuracy of AI text classification models, even when those models are not fine-tuned on specific datasets.
The findings underscore the critical importance of prompt design in the development and deployment of AI-based content moderation and authentication systems. As language models become more advanced and AI-generated content becomes more prevalent, the ability to reliably identify machine-generated text will be essential for maintaining the integrity of online information and combating the spread of misinformation.
This research provides valuable insights that can guide future work on optimizing prompt formulations to enhance the robustness and generalization of AI text detection capabilities. Continued exploration of prompt engineering, coupled with advancements in model architectures and training approaches, will be crucial for addressing the challenges posed by the growing prevalence of AI-generated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Uncovering Hidden Intentions: Exploring Prompt Recovery for Deeper Insights into Generated Texts
Louis Give, Timo Zaoral, Maria Antonietta Bruno
0
0
Today, the detection of AI-generated content is receiving more and more attention. Our idea is to go beyond detection and try to recover the prompt used to generate a text. This paper, to the best of our knowledge, introduces the first investigation in this particular domain without a closed set of tasks. Our goal is to study if this approach is promising. We experiment with zero-shot and few-shot in-context learning but also with LoRA fine-tuning. After that, we evaluate the benefits of using a semi-synthetic dataset. For this first study, we limit ourselves to text generated by a single model. The results show that it is possible to recover the original prompt with a reasonable degree of accuracy.
6/26/2024

Instances Need More Care: Rewriting Prompts for Instances with LLMs in the Loop Yields Better Zero-Shot Performance
Saurabh Srivastava, Chengyue Huang, Weiguo Fan, Ziyu Yao
0
0
Large language models (LLMs) have revolutionized zero-shot task performance, mitigating the need for task-specific annotations while enhancing task generalizability. Despite its advancements, current methods using trigger phrases such as Let's think step by step remain limited. This study introduces PRomPTed, an approach that optimizes the zero-shot prompts for individual task instances following an innovative manner of LLMs in the loop. Our comprehensive evaluation across 13 datasets and 10 task types based on GPT-4 reveals that PRomPTed significantly outperforms both the naive zero-shot approaches and a strong baseline (i.e., Output Refinement) which refines the task output instead of the input prompt. Our experimental results also confirmed the generalization of this advantage to the relatively weaker GPT-3.5. Even more intriguingly, we found that leveraging GPT-3.5 to rewrite prompts for the stronger GPT-4 not only matches but occasionally exceeds the efficacy of using GPT-4 as the prompt rewriter. Our research thus presents a huge value in not only enhancing zero-shot LLM performance but also potentially enabling supervising LLMs with their weaker counterparts, a capability attracting much interest recently. Finally, our additional experiments confirm the generalization of the advantages to open-source LLMs such as Mistral 7B and Mixtral 8x7B.
6/13/2024
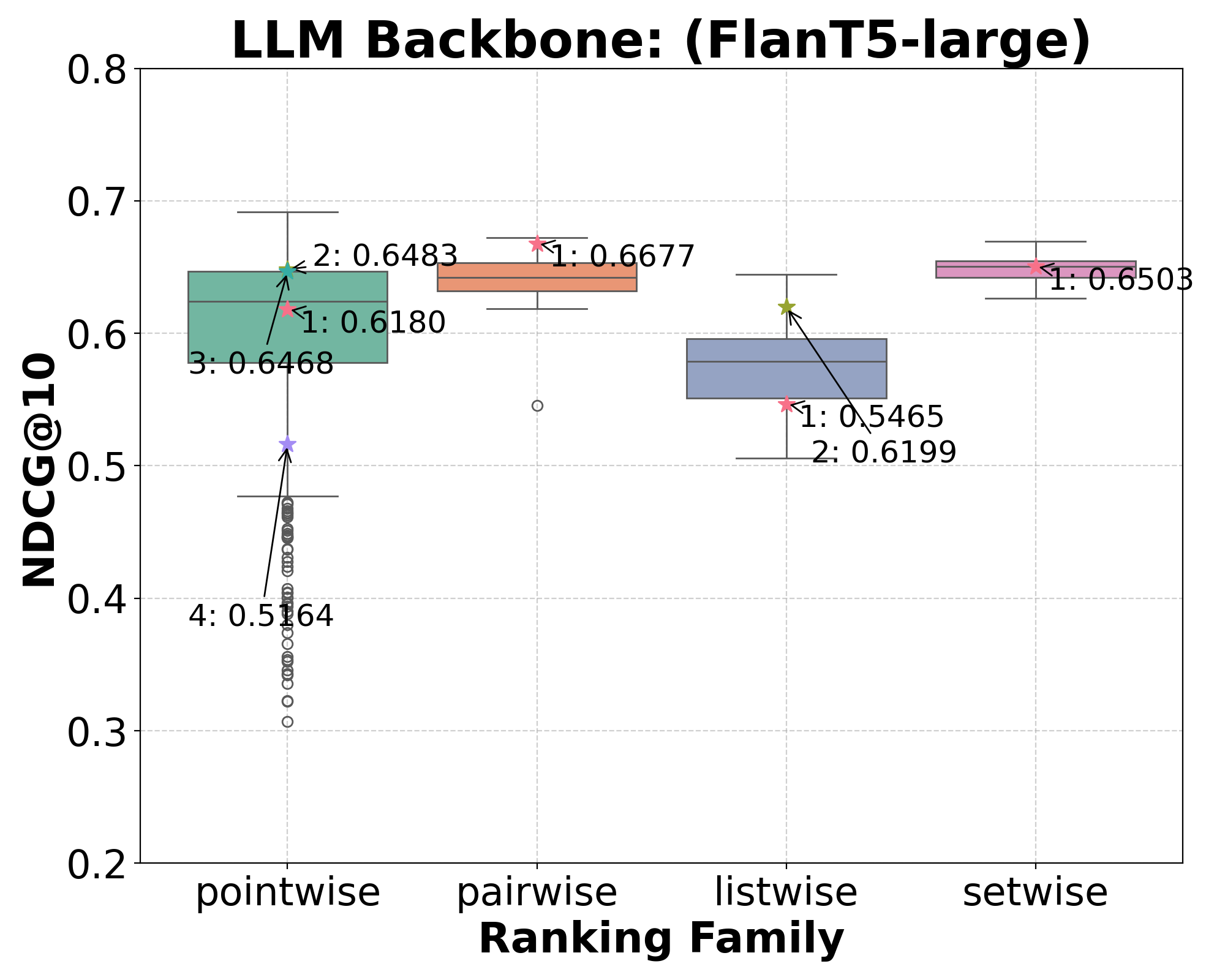
An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
Shuoqi Sun, Shengyao Zhuang, Shuai Wang, Guido Zuccon
0
0
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
6/21/2024
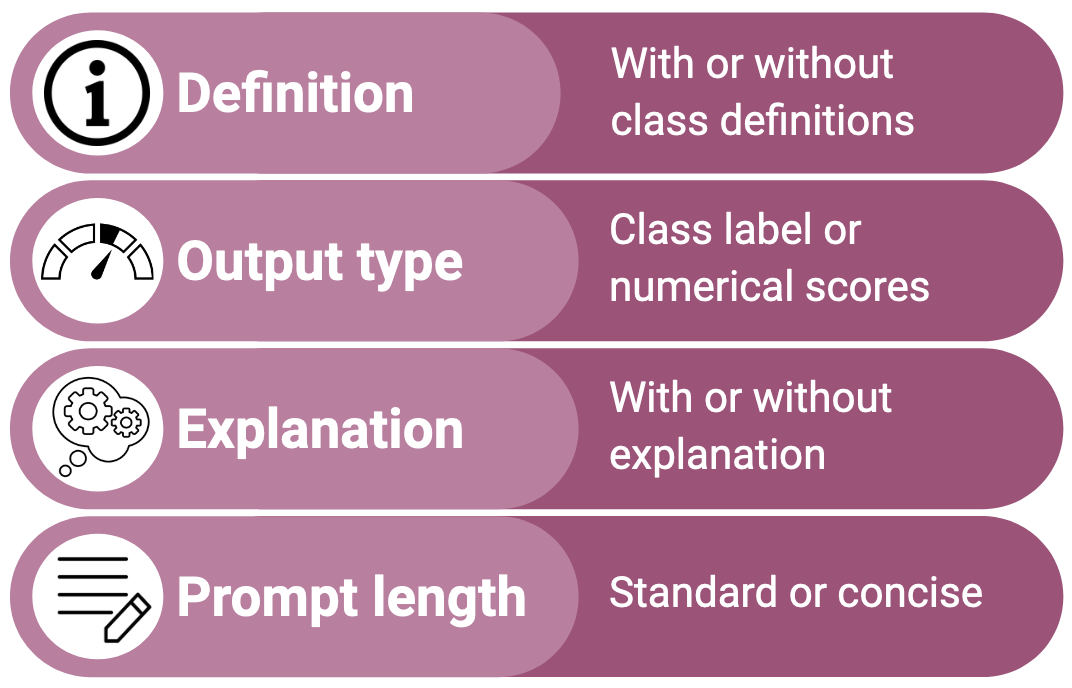
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024