Instances Need More Care: Rewriting Prompts for Instances with LLMs in the Loop Yields Better Zero-Shot Performance
2310.02107
0
0

Abstract
Large language models (LLMs) have revolutionized zero-shot task performance, mitigating the need for task-specific annotations while enhancing task generalizability. Despite its advancements, current methods using trigger phrases such as Let's think step by step remain limited. This study introduces PRomPTed, an approach that optimizes the zero-shot prompts for individual task instances following an innovative manner of LLMs in the loop. Our comprehensive evaluation across 13 datasets and 10 task types based on GPT-4 reveals that PRomPTed significantly outperforms both the naive zero-shot approaches and a strong baseline (i.e., Output Refinement) which refines the task output instead of the input prompt. Our experimental results also confirmed the generalization of this advantage to the relatively weaker GPT-3.5. Even more intriguingly, we found that leveraging GPT-3.5 to rewrite prompts for the stronger GPT-4 not only matches but occasionally exceeds the efficacy of using GPT-4 as the prompt rewriter. Our research thus presents a huge value in not only enhancing zero-shot LLM performance but also potentially enabling supervising LLMs with their weaker counterparts, a capability attracting much interest recently. Finally, our additional experiments confirm the generalization of the advantages to open-source LLMs such as Mistral 7B and Mixtral 8x7B.
Create account to get full access
Overview
- This paper explores how rewriting prompts for individual problem instances can improve the zero-shot performance of large language models (LLMs).
- The authors propose a prompt rewriting approach that tailors prompts to specific instances, rather than using a single generic prompt for all instances.
- They demonstrate that this instance-level prompt rewriting leads to significant performance gains on a variety of tasks compared to using a single generic prompt.
Plain English Explanation
The paper focuses on a common issue with using large language models (LLMs) for tasks in a "zero-shot" setting, where the model is asked to perform a task without any fine-tuning or specialized training. In these zero-shot scenarios, the performance of LLMs can sometimes be disappointing.
The key insight of this paper is that the way you phrase the instructions or "prompt" given to the LLM can have a big impact on its performance. Rather than using a single generic prompt for all problem instances, the authors show that rewriting the prompt to be more tailored to each specific instance can lead to much better results.
Imagine you're using an LLM to answer questions about a complex topic like astrophysics. If you give the model a vague, generic prompt, it may struggle to provide high-quality answers. But if you rephrase the prompt to be more specific to the particular question being asked, the model is much more likely to succeed.
The authors demonstrate this effect across a variety of tasks, showing that instance-level prompt rewriting consistently outperforms using a single generic prompt. This suggests that the way we communicate with and instruct these powerful language models is just as important as the models themselves.
Technical Explanation
The paper begins by providing background on the challenge of using LLMs in zero-shot settings, where the model is asked to perform a task without any fine-tuning or specialized training. The authors note that despite the impressive capabilities of LLMs, their performance can sometimes be suboptimal in these zero-shot scenarios.
To address this, the authors propose a prompt rewriting approach that tailors the instructions or "prompt" given to the LLM for each individual problem instance, rather than using a single generic prompt for all instances. The key steps of their method are:
- Defining a base prompt that captures the overall task.
- Automatically rewriting this base prompt to be more specific to each individual instance, using techniques like paraphrasing and expanding on key details.
- Feeding the rewritten instance-specific prompt to the LLM to generate the final output.
Through extensive experiments across a range of benchmark tasks, the authors demonstrate that this instance-level prompt rewriting approach consistently outperforms using a single generic prompt. They attribute this performance boost to the LLM being able to better understand and reason about the specific problem at hand when provided with a more tailored prompt.
The authors also analyze the types of prompt rewrites that are most effective, finding that techniques like adding more context, rephrasing the instructions, and expanding on key details tend to be especially helpful.
Critical Analysis
The paper makes a compelling case for the importance of prompt engineering when working with LLMs in zero-shot settings. The authors provide a clear and rigorous experimental setup, thoroughly evaluating their approach across a diverse set of tasks.
One potential limitation is that the prompt rewriting process is currently done manually, which may limit its scalability. The authors acknowledge this and suggest that developing automated prompt rewriting techniques could be an interesting area for future research.
Additionally, while the paper demonstrates the effectiveness of instance-level prompt rewriting, it does not explore the underlying reasons for this phenomenon in depth. Further investigation into the cognitive and architectural factors that make LLMs responsive to prompt changes could lead to additional insights.
Overall, this paper makes an important contribution by highlighting the crucial role of prompts in leveraging the capabilities of LLMs. The findings suggest that investing time and effort into prompt engineering may be a highly effective way to improve the performance of these models, especially in zero-shot scenarios.
Conclusion
This paper presents a novel approach for improving the zero-shot performance of large language models (LLMs) by rewriting prompts at the instance level. The key insight is that tailoring the instructions or "prompt" given to the LLM for each specific problem instance can lead to much better results than using a single generic prompt.
The authors demonstrate the effectiveness of their instance-level prompt rewriting approach across a variety of benchmark tasks, consistently outperforming the use of a single generic prompt. This work highlights the importance of prompt engineering when working with powerful language models, and suggests that investing time and effort into crafting high-quality prompts may be a highly impactful way to unlock the full potential of these models.
The findings of this paper have broader implications for the field of AI, underscoring the need to carefully consider the way we communicate with and instruct these language models. As LLMs become increasingly ubiquitous, developing techniques like instance-level prompt rewriting may be crucial for ensuring they can be reliably and effectively deployed in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
Shuoqi Sun, Shengyao Zhuang, Shuai Wang, Guido Zuccon
0
0
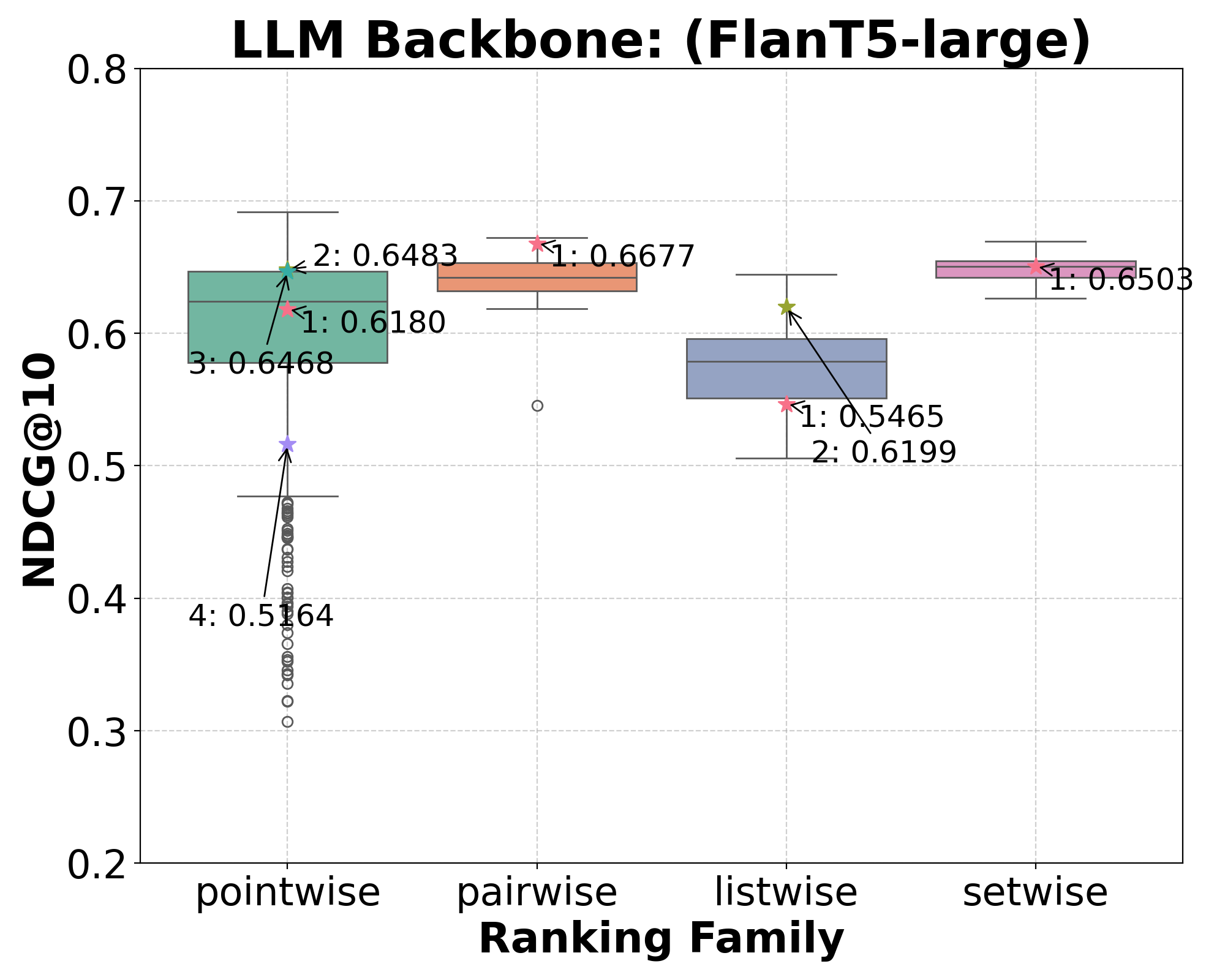
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
6/21/2024
🏅
PRewrite: Prompt Rewriting with Reinforcement Learning
Weize Kong, Spurthi Amba Hombaiah, Mingyang Zhang, Qiaozhu Mei, Michael Bendersky
0
0
Prompt engineering is critical for the development of LLM-based applications. However, it is usually done manually in a trial and error fashion that can be time consuming, ineffective, and sub-optimal. Even for the prompts which seemingly work well, there is always a lingering question: can the prompts be made better with further modifications? To address these problems, we investigate automated prompt engineering in this paper. Specifically, we propose PRewrite, an automated method to rewrite an under-optimized prompt to a more effective prompt. We instantiate the prompt rewriter using a LLM. The rewriter LLM is trained using reinforcement learning to optimize the performance on a given downstream task. We conduct experiments on diverse benchmark datasets, which demonstrates the effectiveness of PRewrite.
6/11/2024

RePrompt: Planning by Automatic Prompt Engineering for Large Language Models Agents
Weizhe Chen, Sven Koenig, Bistra Dilkina
0
0
In this past year, large language models (LLMs) have had remarkable success in domains outside the traditional natural language processing, and people are starting to explore the usage of LLMs in more general and close to application domains like code generation, travel planning, and robot controls. Connecting these LLMs with great capacity and external tools, people are building the so-called LLM agents, which are supposed to help people do all kinds of work in everyday life. In all these domains, the prompt to the LLMs has been shown to make a big difference in what the LLM would generate and thus affect the performance of the LLM agents. Therefore, automatic prompt engineering has become an important question for many researchers and users of LLMs. In this paper, we propose a novel method, textsc{RePrompt}, which does gradient descent to optimize the step-by-step instructions in the prompt of the LLM agents based on the chat history obtained from interactions with LLM agents. By optimizing the prompt, the LLM will learn how to plan in specific domains. We have used experiments in PDDL generation and travel planning to show that our method could generally improve the performance for different reasoning tasks when using the updated prompt as the initial prompt.
6/18/2024
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
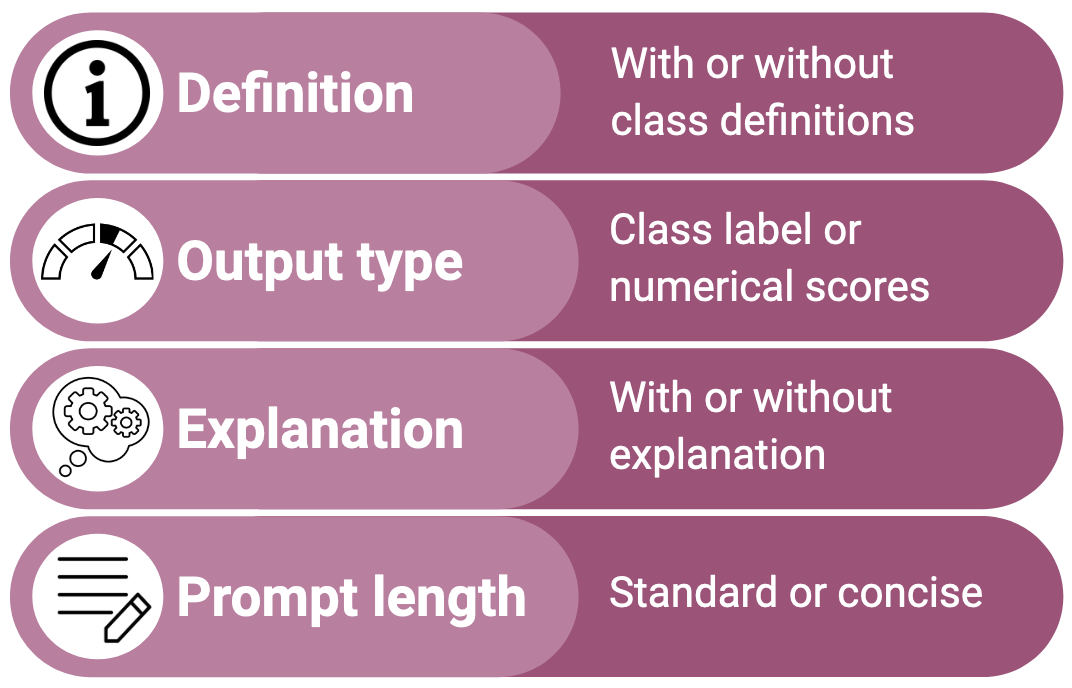
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024