An Investigation of Prompt Variations for Zero-shot LLM-based Rankers
2406.14117
0
0
Abstract
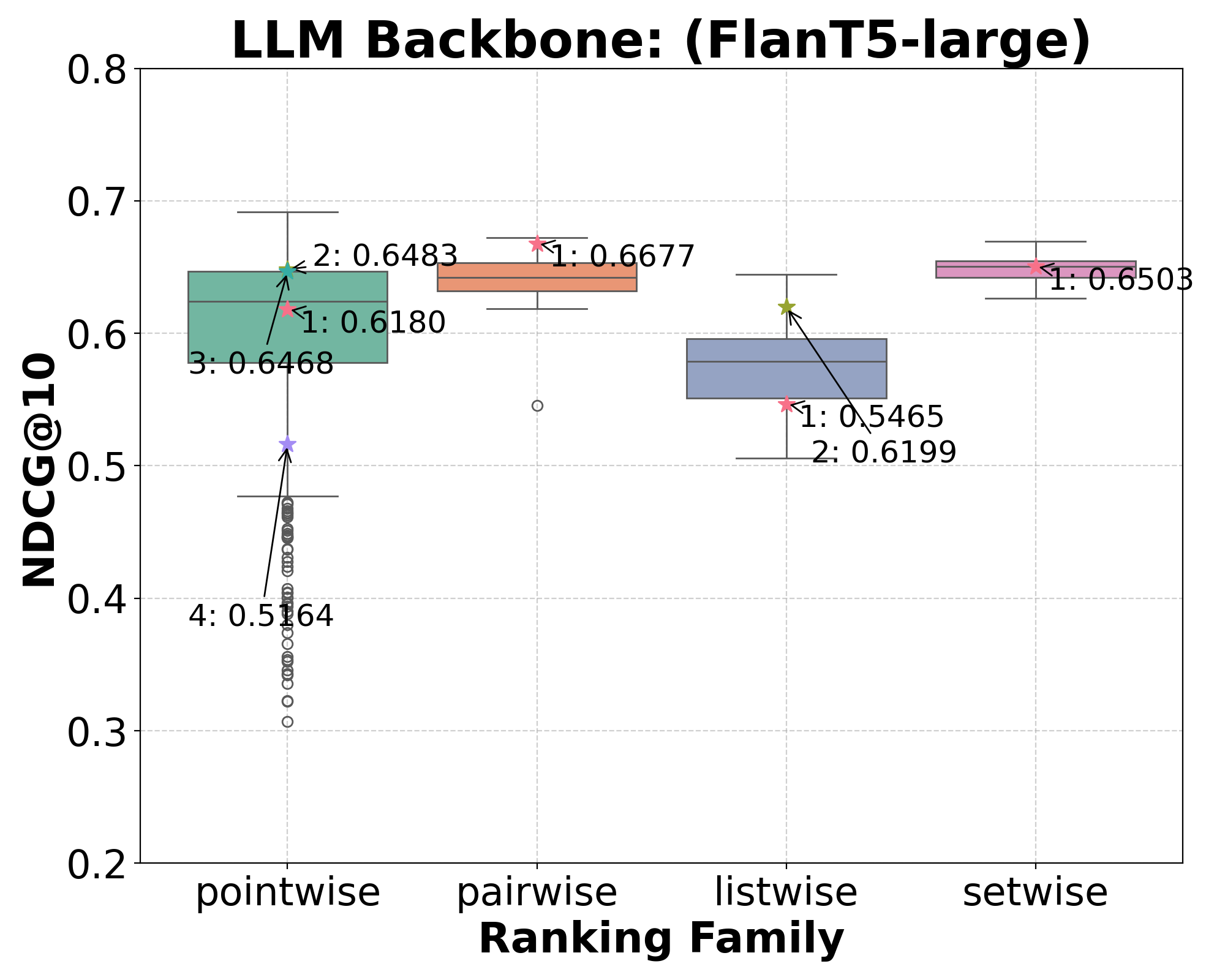
We provide a systematic understanding of the impact of specific components and wordings used in prompts on the effectiveness of rankers based on zero-shot Large Language Models (LLMs). Several zero-shot ranking methods based on LLMs have recently been proposed. Among many aspects, methods differ across (1) the ranking algorithm they implement, e.g., pointwise vs. listwise, (2) the backbone LLMs used, e.g., GPT3.5 vs. FLAN-T5, (3) the components and wording used in prompts, e.g., the use or not of role-definition (role-playing) and the actual words used to express this. It is currently unclear whether performance differences are due to the underlying ranking algorithm, or because of spurious factors such as better choice of words used in prompts. This confusion risks to undermine future research. Through our large-scale experimentation and analysis, we find that ranking algorithms do contribute to differences between methods for zero-shot LLM ranking. However, so do the LLM backbones -- but even more importantly, the choice of prompt components and wordings affect the ranking. In fact, in our experiments, we find that, at times, these latter elements have more impact on the ranker's effectiveness than the actual ranking algorithms, and that differences among ranking methods become more blurred when prompt variations are considered.
Create account to get full access
Overview
• This paper investigates the impact of different prompting approaches on the performance of zero-shot language model-based rankers, which are AI systems that can rank and order items without being explicitly trained on that specific task.
• The researchers explore how variations in the wording and structure of the prompts used to guide these language models can affect their ability to effectively rank and sort items.
• The findings provide insights into the importance of prompt design for leveraging large language models in tasks like information retrieval, where high-quality rankings are crucial.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities to perform a wide variety of tasks by simply being prompted with the right instructions. In the case of information retrieval, these models can be used as "zero-shot rankers" - meaning they can rank and order items without being explicitly trained on that specific task.
However, the wording and structure of the prompts used to guide these LLMs can have a significant impact on their performance. This paper explores how different prompt variations affect the ranking abilities of zero-shot LLM-based rankers.
The researchers found that factors like the specificity of the prompts, the inclusion of related context information, and the overall prompt format can all influence how well the LLMs are able to sort and rank items. This suggests that careful prompt design is crucial for getting the best performance out of these powerful language models when using them for information retrieval and similar zero-shot tasks.
Technical Explanation
The paper describes a series of experiments that evaluate the impact of different prompt variations on the ranking performance of zero-shot LLM-based rankers. The researchers used a GPT-3-based model as their core language model and tested it on standard information retrieval benchmarks.
They explored several prompt design factors, including:
- The level of specificity in the prompt instructions
- The inclusion of additional context information related to the ranking task
- The overall format and structure of the prompt
The experiments showed that more specific prompts, as well as those that included relevant contextual details, tended to result in better ranking performance from the LLM. The researchers also found that organizing the prompts in a structured, multi-step format could further improve the model's ability to effectively rank the given items.
Through these findings, the paper provides insights into the importance of prompt engineering for leveraging large language models in zero-shot information retrieval and similar tasks. The results suggest that investing effort into crafting high-quality prompts is crucial for getting the best performance out of these powerful AI systems.
Critical Analysis
The paper offers a valuable contribution by systematically investigating the effect of prompt variations on zero-shot LLM-based rankers. The researchers acknowledge that prompt design is a critical factor in the performance of these systems, and their experiments provide empirical evidence to support this claim.
However, the paper does not extensively explore the underlying reasons for why certain prompt variations lead to better ranking results. While the authors provide some hypotheses, a deeper analysis of the linguistic and cognitive mechanisms at play could further strengthen the insights from this work.
Additionally, the paper focuses on a specific LLM (GPT-3) and information retrieval tasks. Expanding the research to include a wider range of language models and application domains could help validate the generalizability of the findings and uncover any potential model-specific biases or limitations.
Future research could also investigate the interactive effects of different prompt design elements, as well as the potential for automated prompt optimization techniques to further improve the performance of zero-shot LLM-based rankers. Exploring these avenues could lead to a more comprehensive understanding of the role of prompt engineering in leveraging large language models for real-world tasks.
Conclusion
This paper highlights the importance of prompt design for the effective use of large language models in zero-shot ranking and information retrieval tasks. The researchers found that factors like prompt specificity, inclusion of relevant context, and overall prompt structure can all significantly impact the performance of these AI systems.
The insights from this work suggest that investing time and effort into crafting high-quality prompts is crucial for getting the best results when leveraging powerful language models for tasks like document ranking and sorting. As large language models continue to advance, the ability to engineer prompts that elicit their full potential will become an increasingly important skill for researchers and practitioners alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, Guido Zuccon
0
0
We propose a novel zero-shot document ranking approach based on Large Language Models (LLMs): the Setwise prompting approach. Our approach complements existing prompting approaches for LLM-based zero-shot ranking: Pointwise, Pairwise, and Listwise. Through the first-of-its-kind comparative evaluation within a consistent experimental framework and considering factors like model size, token consumption, latency, among others, we show that existing approaches are inherently characterised by trade-offs between effectiveness and efficiency. We find that while Pointwise approaches score high on efficiency, they suffer from poor effectiveness. Conversely, Pairwise approaches demonstrate superior effectiveness but incur high computational overhead. Our Setwise approach, instead, reduces the number of LLM inferences and the amount of prompt token consumption during the ranking procedure, compared to previous methods. This significantly improves the efficiency of LLM-based zero-shot ranking, while also retaining high zero-shot ranking effectiveness. We make our code and results publicly available at url{https://github.com/ielab/llm-rankers}.
5/31/2024
💬
PromptReps: Prompting Large Language Models to Generate Dense and Sparse Representations for Zero-Shot Document Retrieval
Shengyao Zhuang, Xueguang Ma, Bevan Koopman, Jimmy Lin, Guido Zuccon
0
0
Utilizing large language models (LLMs) for zero-shot document ranking is done in one of two ways: 1) prompt-based re-ranking methods, which require no further training but are only feasible for re-ranking a handful of candidate documents due to computational costs; and 2) unsupervised contrastive trained dense retrieval methods, which can retrieve relevant documents from the entire corpus but require a large amount of paired text data for contrastive training. In this paper, we propose PromptReps, which combines the advantages of both categories: no need for training and the ability to retrieve from the whole corpus. Our method only requires prompts to guide an LLM to generate query and document representations for effective document retrieval. Specifically, we prompt the LLMs to represent a given text using a single word, and then use the last token's hidden states and the corresponding logits associated with the prediction of the next token to construct a hybrid document retrieval system. The retrieval system harnesses both dense text embedding and sparse bag-of-words representations given by the LLM. We further explore variations of this core idea that consider the generation of multiple words, and representations that rely on multiple embeddings and sparse distributions. Our experimental evaluation on the MSMARCO, TREC deep learning and BEIR zero-shot document retrieval datasets illustrates that this simple prompt-based LLM retrieval method can achieve a similar or higher retrieval effectiveness than state-of-the-art LLM embedding methods that are trained with large amounts of unsupervised data, especially when using a larger LLM.
6/18/2024

Instances Need More Care: Rewriting Prompts for Instances with LLMs in the Loop Yields Better Zero-Shot Performance
Saurabh Srivastava, Chengyue Huang, Weiguo Fan, Ziyu Yao
0
0
Large language models (LLMs) have revolutionized zero-shot task performance, mitigating the need for task-specific annotations while enhancing task generalizability. Despite its advancements, current methods using trigger phrases such as Let's think step by step remain limited. This study introduces PRomPTed, an approach that optimizes the zero-shot prompts for individual task instances following an innovative manner of LLMs in the loop. Our comprehensive evaluation across 13 datasets and 10 task types based on GPT-4 reveals that PRomPTed significantly outperforms both the naive zero-shot approaches and a strong baseline (i.e., Output Refinement) which refines the task output instead of the input prompt. Our experimental results also confirmed the generalization of this advantage to the relatively weaker GPT-3.5. Even more intriguingly, we found that leveraging GPT-3.5 to rewrite prompts for the stronger GPT-4 not only matches but occasionally exceeds the efficacy of using GPT-4 as the prompt rewriter. Our research thus presents a huge value in not only enhancing zero-shot LLM performance but also potentially enabling supervising LLMs with their weaker counterparts, a capability attracting much interest recently. Finally, our additional experiments confirm the generalization of the advantages to open-source LLMs such as Mistral 7B and Mixtral 8x7B.
6/13/2024
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
0
0
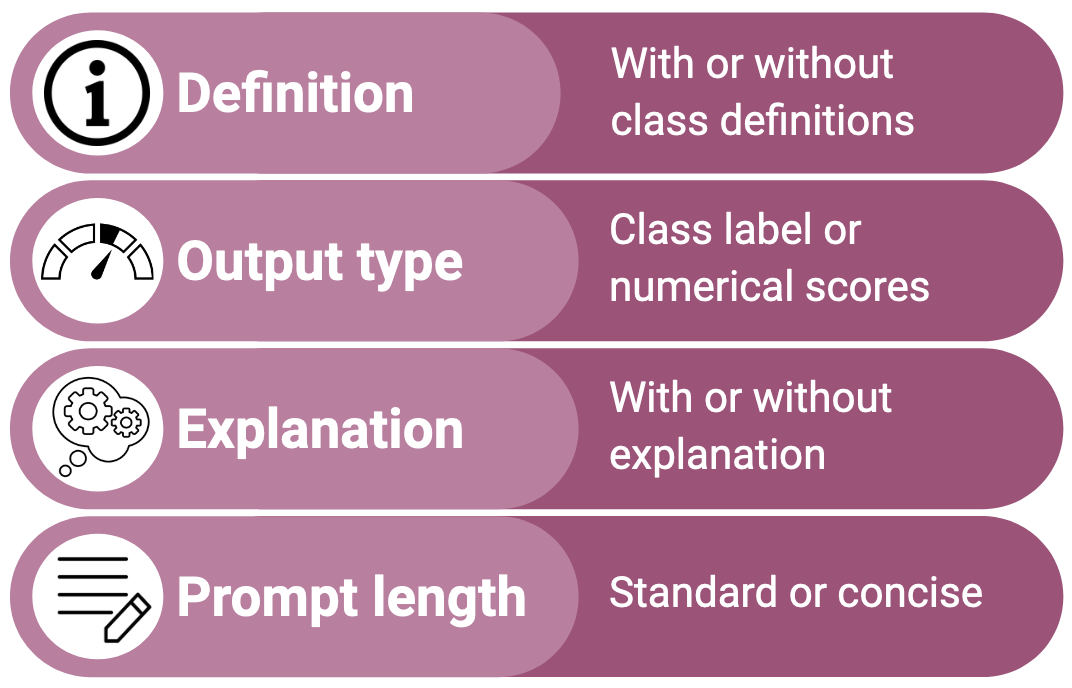
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
6/19/2024