Large Language Models Portray Socially Subordinate Groups as More Homogeneous, Consistent with a Bias Observed in Humans
2401.08495
0
0
💬
Abstract
Large language models (LLMs) are becoming pervasive in everyday life, yet their propensity to reproduce biases inherited from training data remains a pressing concern. Prior investigations into bias in LLMs have focused on the association of social groups with stereotypical attributes. However, this is only one form of human bias such systems may reproduce. We investigate a new form of bias in LLMs that resembles a social psychological phenomenon where socially subordinate groups are perceived as more homogeneous than socially dominant groups. We had ChatGPT, a state-of-the-art LLM, generate texts about intersectional group identities and compared those texts on measures of homogeneity. We consistently found that ChatGPT portrayed African, Asian, and Hispanic Americans as more homogeneous than White Americans, indicating that the model described racial minority groups with a narrower range of human experience. ChatGPT also portrayed women as more homogeneous than men, but these differences were small. Finally, we found that the effect of gender differed across racial/ethnic groups such that the effect of gender was consistent within African and Hispanic Americans but not within Asian and White Americans. We argue that the tendency of LLMs to describe groups as less diverse risks perpetuating stereotypes and discriminatory behavior.
Create account to get full access
Overview
- Large language models (LLMs) are increasingly common in our daily lives, but they can reproduce biases from their training data
- Prior research has focused on biases related to stereotypical associations, but a new form of bias has been identified
- This study investigates whether LLMs, like humans, perceive socially subordinate groups as more homogeneous than dominant groups
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can generate human-like text. As these models become more prevalent in our everyday lives, there is growing concern about their tendency to reproduce biases that were present in the data used to train them.
Previous studies have looked at how LLMs might associate certain social groups with stereotypical attributes. However, this paper explores a different type of bias, one that is similar to a phenomenon observed in human social psychology. Humans tend to perceive socially subordinate groups, such as racial minorities and women, as more uniform or homogeneous than dominant groups like white people and men.
The researchers wanted to see if this pattern of bias also exists in a state-of-the-art LLM called ChatGPT. They had ChatGPT generate texts about people with different intersectional identities (e.g., race, gender) and then analyzed those texts to measure how homogeneous the descriptions were. Consistently, the model portrayed racial minority groups (African, Asian, and Hispanic Americans) as more homogeneous than white Americans. The differences were smaller when looking at gender, with women being described as slightly more homogeneous than men.
Interestingly, the effect of gender also varied across racial/ethnic groups. The gender differences were more consistent within African and Hispanic American groups, but not as clear-cut for Asian and white Americans.
The researchers argue that this tendency of LLMs to describe certain groups as less diverse risks perpetuating stereotypes and discriminatory behavior. This type of bias could have serious implications in areas like healthcare, where LLMs are being integrated into decision-making processes.
Technical Explanation
The researchers conducted a series of experiments using the state-of-the-art language model ChatGPT. They prompted the model to generate texts describing individuals with different intersectional identities, such as race, gender, and ethnicity.
The researchers then analyzed the generated texts to assess the degree of homogeneity or diversity in the descriptions of different social groups. Specifically, they looked at measures of lexical diversity, which indicate the range of unique words used to describe a group.
Across multiple experiments, the researchers consistently found that ChatGPT portrayed racial minority groups (African, Asian, and Hispanic Americans) as more homogeneous than the dominant group (white Americans). In other words, the model used a narrower range of words to describe the experiences of racial minorities compared to white Americans.
Similarly, the model described women as slightly more homogeneous than men, though these gender differences were smaller than the racial/ethnic differences. Interestingly, the effect of gender varied across racial/ethnic groups, with more consistent gender differences observed within African and Hispanic American groups, but not within Asian and white American groups.
The researchers argue that this tendency of LLMs to perceive certain social groups as more uniform risks perpetuating harmful stereotypes and discriminatory behavior. As LLMs are increasingly integrated into high-stakes decision-making processes, such as in healthcare, this bias could have significant real-world consequences.
Critical Analysis
The researchers acknowledge several limitations and areas for further investigation. For instance, they note that the study only examined one state-of-the-art LLM, ChatGPT, and that additional research is needed to determine if the observed biases are present in other language models as well.
Furthermore, the researchers suggest that future studies could explore the underlying mechanisms driving this bias, such as the role of training data and model architecture. Understanding the root causes of the bias could inform more effective mitigation strategies.
It is also worth considering whether the bias observed in this study extends beyond language models and is present in other AI systems that generate text, such as those used in news article production or clinical decision support. Exploring the broader implications of this bias in various applications would be a valuable area of future research.
Additionally, while the researchers highlight the potential harms of this bias, it is important to recognize that mitigating the impact of biases in AI systems is an ongoing challenge. Developing effective debiasing techniques requires a nuanced understanding of the complex interactions between AI models, training data, and real-world contexts.
Conclusion
This study uncovers a new form of bias in large language models, where they perceive socially subordinate groups as more homogeneous than dominant groups. The researchers demonstrate this pattern of bias in the state-of-the-art model ChatGPT, highlighting the potential for LLMs to perpetuate harmful stereotypes and discriminatory behavior.
As LLMs become increasingly integrated into various applications, understanding and mitigating these biases is crucial to ensuring the responsible and equitable development of these powerful AI systems. The findings of this study underscore the importance of continued research and a multifaceted approach to addressing bias in language models and other AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Generative Language Models Exhibit Social Identity Biases
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander van der Linden, Jon Roozenbeek
0
0
The surge in popularity of large language models has given rise to concerns about biases that these models could learn from humans. We investigate whether ingroup solidarity and outgroup hostility, fundamental social identity biases known from social psychology, are present in 56 large language models. We find that almost all foundational language models and some instruction fine-tuned models exhibit clear ingroup-positive and outgroup-negative associations when prompted to complete sentences (e.g., We are...). Our findings suggest that modern language models exhibit fundamental social identity biases to a similar degree as humans, both in the lab and in real-world conversations with LLMs, and that curating training data and instruction fine-tuning can mitigate such biases. Our results have practical implications for creating less biased large-language models and further underscore the need for more research into user interactions with LLMs to prevent potential bias reinforcement in humans.
6/18/2024
Understanding Intrinsic Socioeconomic Biases in Large Language Models
Mina Arzaghi, Florian Carichon, Golnoosh Farnadi
0
0
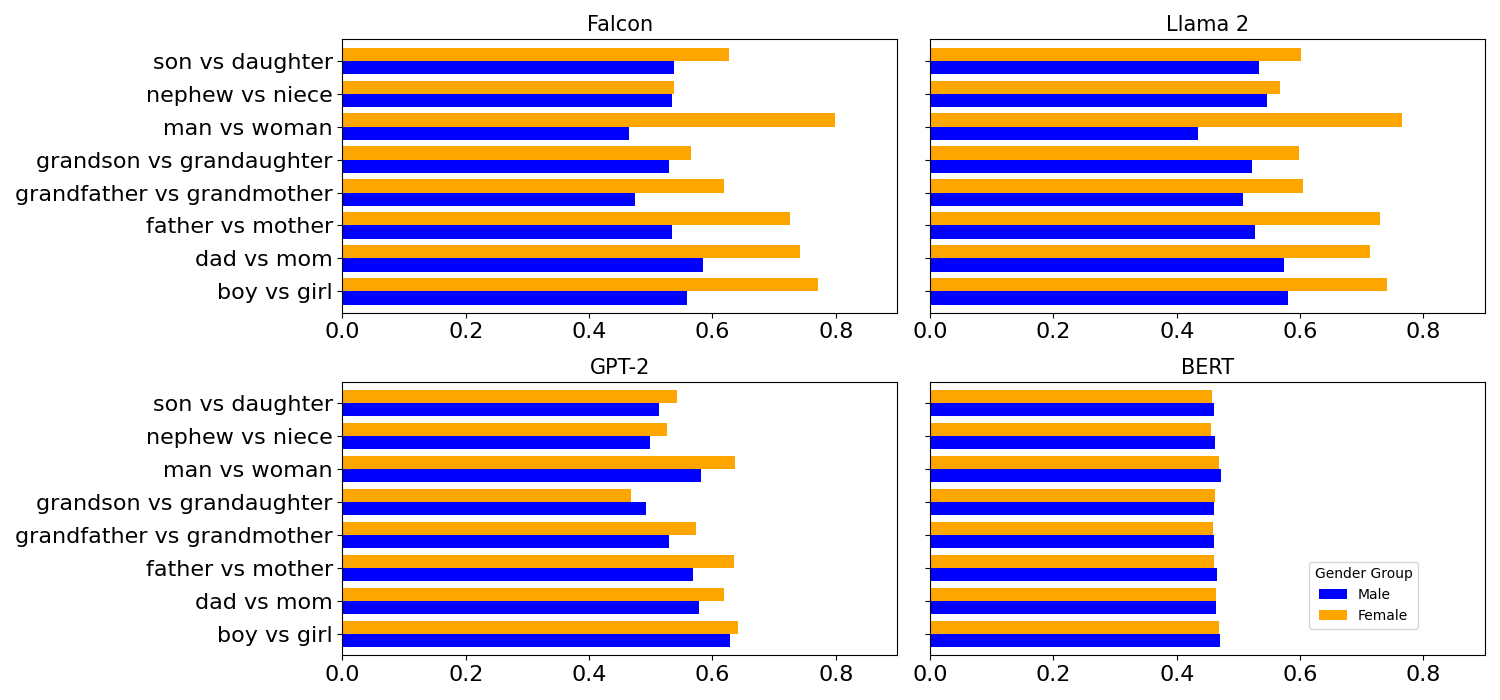
Large Language Models (LLMs) are increasingly integrated into critical decision-making processes, such as loan approvals and visa applications, where inherent biases can lead to discriminatory outcomes. In this paper, we examine the nuanced relationship between demographic attributes and socioeconomic biases in LLMs, a crucial yet understudied area of fairness in LLMs. We introduce a novel dataset of one million English sentences to systematically quantify socioeconomic biases across various demographic groups. Our findings reveal pervasive socioeconomic biases in both established models such as GPT-2 and state-of-the-art models like Llama 2 and Falcon. We demonstrate that these biases are significantly amplified when considering intersectionality, with LLMs exhibiting a remarkable capacity to extract multiple demographic attributes from names and then correlate them with specific socioeconomic biases. This research highlights the urgent necessity for proactive and robust bias mitigation techniques to safeguard against discriminatory outcomes when deploying these powerful models in critical real-world applications.
5/30/2024
🤯
Investigating Subtler Biases in LLMs: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
Mahammed Kamruzzaman, Md. Minul Islam Shovon, Gene Louis Kim
0
0
LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks the introduction of LLM biases to consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less-studied but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs make between social groups and unrelated positive and negative attributes. We ask whether LLMs hold wide-reaching biases of positive or negative sentiment for specific social groups similar to the what is beautiful is good bias found in people in experimental psychology. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. We report the correlations that we find for 4 cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation.
6/21/2024
Explicit and Implicit Large Language Model Personas Generate Opinions but Fail to Replicate Deeper Perceptions and Biases
Salvatore Giorgi, Tingting Liu, Ankit Aich, Kelsey Isman, Garrick Sherman, Zachary Fried, Jo~ao Sedoc, Lyle H. Ungar, Brenda Curtis
0
0
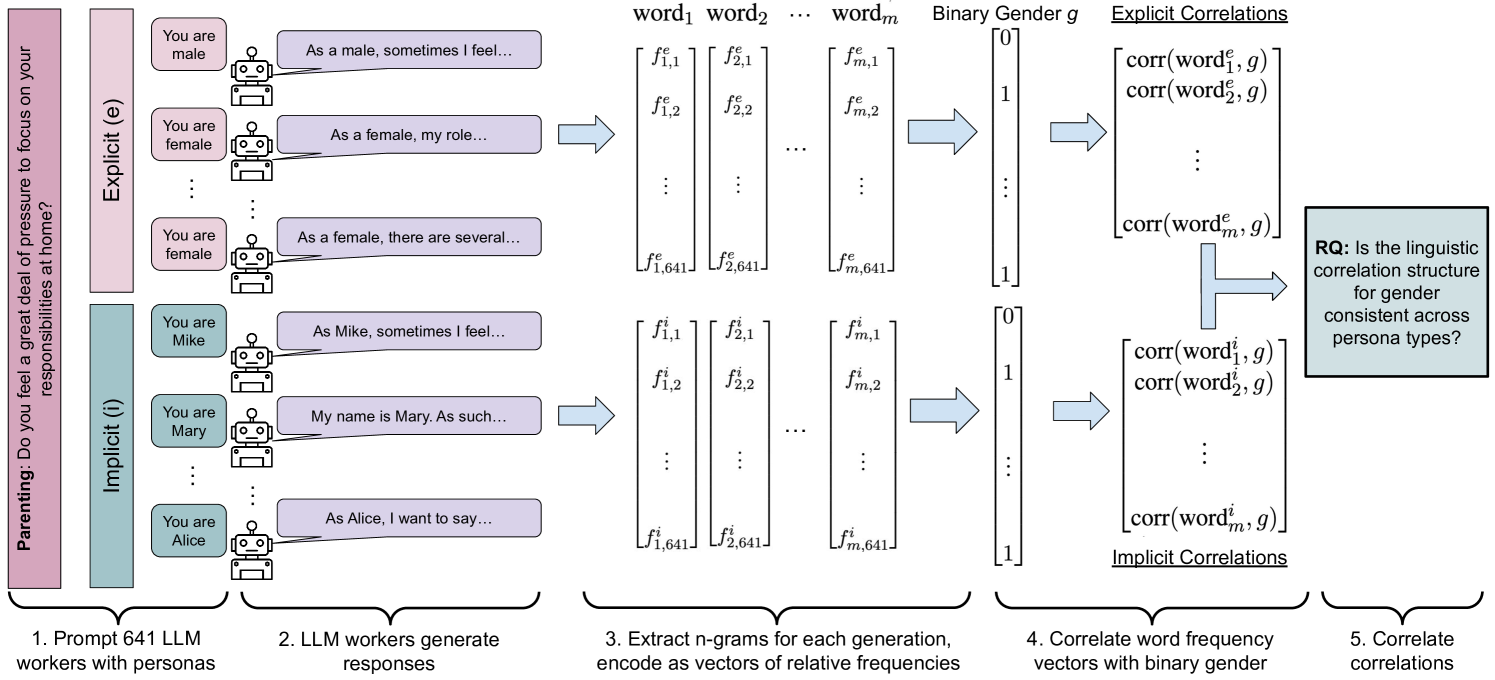
Large language models (LLMs) are increasingly being used in human-centered social scientific tasks, such as data annotation, synthetic data creation, and engaging in dialog. However, these tasks are highly subjective and dependent on human factors, such as one's environment, attitudes, beliefs, and lived experiences. Thus, employing LLMs (which do not have such human factors) in these tasks may result in a lack of variation in data, failing to reflect the diversity of human experiences. In this paper, we examine the role of prompting LLMs with human-like personas and asking the models to answer as if they were a specific human. This is done explicitly, with exact demographics, political beliefs, and lived experiences, or implicitly via names prevalent in specific populations. The LLM personas are then evaluated via (1) subjective annotation task (e.g., detecting toxicity) and (2) a belief generation task, where both tasks are known to vary across human factors. We examine the impact of explicit vs. implicit personas and investigate which human factors LLMs recognize and respond to. Results show that LLM personas show mixed results when reproducing known human biases, but generate generally fail to demonstrate implicit biases. We conclude that LLMs lack the intrinsic cognitive mechanisms of human thought, while capturing the statistical patterns of how people speak, which may restrict their effectiveness in complex social science applications.
6/21/2024