REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark

0

Sign in to get full access
Overview
- This paper introduces a new benchmark called RepoExec for evaluating code generation models at the repository level rather than just the class or function level.
- RepoExec aims to better mimic real-world software development by assessing a model's ability to generate complete, executable code repositories that can be integrated into a codebase.
- The paper compares the performance of several state-of-the-art code generation models on the RepoExec benchmark and provides insights into their strengths and limitations.
Plain English Explanation
The paper introduces a new way to evaluate code generation models, which are AI systems that can produce computer programs from natural language descriptions. Existing benchmarks for these models usually focus on generating individual functions or classes of code, but the authors argue this doesn't capture the full complexity of real-world software development.
To address this, they created the RepoExec benchmark, which assesses a model's ability to generate complete, executable code repositories that can be integrated into a larger codebase. This is more representative of the challenges developers face when incorporating AI-generated code into their projects.
The paper then compares the performance of several state-of-the-art code generation models on the RepoExec benchmark. By analyzing the results, the authors gain insights into the strengths and limitations of these models when it comes to producing usable, production-ready code. This information can help guide future research and development efforts in this rapidly advancing field.
Technical Explanation
The paper introduces the RepoExec benchmark, which aims to evaluate code generation models at the repository level rather than just the class or function level. This is an important distinction, as existing benchmarks like ClassLevelCodeGen and DevEval don't fully capture the complexities of integrating AI-generated code into a real-world software project.
The RepoExec benchmark consists of a set of natural language prompts that describe the functionality of a complete code repository. The models are tasked with generating the full repository, including all necessary files, classes, and dependencies, that can be executed and integrated into a larger codebase. This provides a more comprehensive assessment of a model's abilities compared to generating individual code elements.
The paper evaluates the performance of several state-of-the-art code generation models, including Codex and InstructGPT, on the RepoExec benchmark. The results reveal insights into the strengths and limitations of these models, such as their ability to generate complete, executable code repositories versus just individual functions or classes.
Critical Analysis
The RepoExec benchmark represents an important step forward in evaluating code generation models, as it more closely reflects the real-world challenges faced by software developers. However, the paper acknowledges that the benchmark is still limited in scope and may not capture all the nuances of integrating AI-generated code into a complex, production-ready codebase.
Additionally, the paper focuses primarily on evaluating the current state-of-the-art models, but does not delve into the underlying architectural differences or training approaches that may contribute to their performance on the RepoExec benchmark. A more in-depth analysis of these factors could provide valuable insights for future model development.
Furthermore, the paper does not address potential ethical concerns or societal implications of deploying code generation models in real-world software development. As these technologies continue to advance, it will be important to consider issues such as algorithmic bias, security vulnerabilities, and the impact on software engineering job markets.
Conclusion
The RepoExec benchmark introduced in this paper represents a significant advancement in the evaluation of code generation models. By assessing a model's ability to generate complete, executable code repositories, RepoExec provides a more realistic and comprehensive assessment of their capabilities compared to existing benchmarks.
The insights gained from applying RepoExec to several state-of-the-art models can help guide future research and development efforts in this rapidly evolving field. As code generation models continue to improve, the ability to reliably integrate their output into production codebases will be a crucial factor in their real-world adoption and impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark
Nam Le Hai, Dung Manh Nguyen, Nghi D. Q. Bui
CodeLLMs have gained widespread adoption for code generation tasks, yet their capacity to handle repository-level code generation with complex contextual dependencies remains underexplored. Our work underscores the critical importance of leveraging repository-level contexts to generate executable and functionally correct code. We present textbf{methodnamews}, a novel benchmark designed to evaluate repository-level code generation, with a focus on three key aspects: executability, functional correctness through comprehensive test case generation, and accurate utilization of cross-file contexts. Our study examines a controlled scenario where developers specify essential code dependencies (contexts), challenging models to integrate them effectively. Additionally, we introduce an instruction-tuned dataset that enhances CodeLLMs' ability to leverage dependencies, along with a new metric, textit{Dependency Invocation Rate (DIR)}, to quantify context utilization. Experimental results reveal that while pretrained LLMs demonstrate superior performance in terms of correctness, instruction-tuned models excel in context utilization and debugging capabilities. methodnamews offers a comprehensive evaluation framework for assessing code functionality and alignment with developer intent, thereby advancing the development of more reliable CodeLLMs for real-world applications. The dataset and source code are available at~url{https://github.com/FSoft-AI4Code/RepoExec}.
Read more9/4/2024
🛸
0
Class-Level Code Generation from Natural Language Using Iterative, Tool-Enhanced Reasoning over Repository
Ajinkya Deshpande, Anmol Agarwal, Shashank Shet, Arun Iyer, Aditya Kanade, Ramakrishna Bairi, Suresh Parthasarathy
LLMs have demonstrated significant potential in code generation tasks, achieving promising results at the function or statement level across various benchmarks. However, the complexities associated with creating code artifacts like classes, particularly within the context of real-world software repositories, remain underexplored. Prior research treats class-level generation as an isolated task, neglecting the intricate dependencies & interactions that characterize real-world software environments. To address this gap, we introduce RepoClassBench, a comprehensive benchmark designed to rigorously evaluate LLMs in generating complex, class-level code within real-world repositories. RepoClassBench includes Natural Language to Class generation tasks across Java, Python & C# from a selection of repositories. We ensure that each class in our dataset not only has cross-file dependencies within the repository but also includes corresponding test cases to verify its functionality. We find that current models struggle with the realistic challenges posed by our benchmark, primarily due to their limited exposure to relevant repository contexts. To address this shortcoming, we introduce Retrieve-Repotools-Reflect (RRR), a novel approach that equips LLMs with static analysis tools to iteratively navigate & reason about repository-level context in an agent-based framework. Our experiments demonstrate that RRR significantly outperforms existing baselines on RepoClassBench, showcasing its effectiveness across programming languages & under various settings. Our findings emphasize the critical need for code-generation benchmarks to incorporate repo-level dependencies to more accurately reflect the complexities of software development. Our work shows the benefits of leveraging specialized tools to enhance LLMs' understanding of repository context. We plan to make our dataset & evaluation harness public.
Read more6/6/2024

0
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, Yongbin Li
How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
Read more5/31/2024
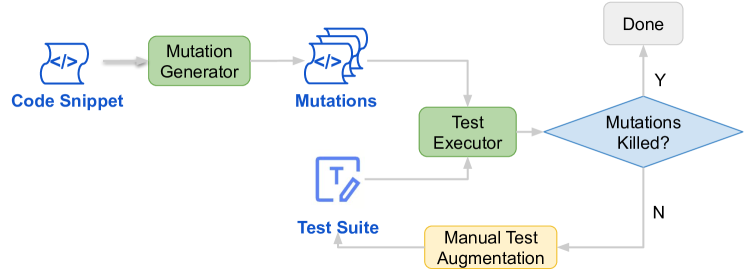
0
RepoMasterEval: Evaluating Code Completion via Real-World Repositories
Qinyun Wu, Chao Peng, Pengfei Gao, Ruida Hu, Haoyu Gan, Bo Jiang, Jinhe Tang, Zhiwen Deng, Zhanming Guan, Cuiyun Gao, Xia Liu, Ping Yang
With the growing reliance on automated code completion tools in software development, the need for robust evaluation benchmarks has become critical. However, existing benchmarks focus more on code generation tasks in function and class level and provide rich text description to prompt the model. By contrast, such descriptive prompt is commonly unavailable in real development and code completion can occur in wider range of situations such as in the middle of a function or a code block. These limitations makes the evaluation poorly align with the practical scenarios of code completion tools. In this paper, we propose RepoMasterEval, a novel benchmark for evaluating code completion models constructed from real-world Python and TypeScript repositories. Each benchmark datum is generated by masking a code snippet (ground truth) from one source code file with existing test suites. To improve test accuracy of model generated code, we employ mutation testing to measure the effectiveness of the test cases and we manually crafted new test cases for those test suites with low mutation score. Our empirical evaluation on 6 state-of-the-art models shows that test argumentation is critical in improving the accuracy of the benchmark and RepoMasterEval is able to report difference in model performance in real-world scenarios. The deployment of RepoMasterEval in a collaborated company for one month also revealed that the benchmark is useful to give accurate feedback during model training and the score is in high correlation with the model's performance in practice. Based on our findings, we call for the software engineering community to build more LLM benchmarks tailored for code generation tools taking the practical and complex development environment into consideration.
Read more8/9/2024