RepoMasterEval: Evaluating Code Completion via Real-World Repositories

0
Sign in to get full access
Overview
- This paper presents RepoMasterEval, a new benchmark for evaluating code completion models using real-world code repositories.
- The authors argue that existing benchmarks do not adequately capture the complexity and diversity of real-world coding tasks.
- RepoMasterEval aims to provide a more realistic assessment of code completion models by testing them on a large, diverse set of code samples from popular GitHub repositories.
Plain English Explanation
The paper focuses on a new way to evaluate code completion models, which are AI systems that can suggest or generate code snippets to help developers write software. The authors believe that existing benchmarks for these models don't accurately reflect the real-world challenges developers face, such as working with large, complex codebases from different domains.
To address this, the researchers created RepoMasterEval, a new benchmark that tests code completion models on a diverse set of code samples taken directly from popular open-source projects on GitHub. This allows the models to be evaluated on a wider range of coding tasks and styles, providing a more realistic assessment of their capabilities.
The goal is to help developers and researchers better understand how well these AI-powered code assistants would perform in real-world software development scenarios, rather than just on simplified, academic-style coding problems. This could lead to the creation of more practical and effective code completion tools in the future.
Technical Explanation
The key aspects of the RepoMasterEval benchmark are:
-
Dataset: The authors collected code samples from a large number of GitHub repositories across various programming languages and domains, resulting in a diverse dataset for evaluating code completion models.
-
Evaluation Metrics: In addition to standard metrics like perplexity and top-k accuracy, the authors introduced new repository-level metrics to assess how well the models perform on complete, real-world codebases, rather than just individual code snippets.
-
Benchmark Design: RepoMasterEval includes a range of different tasks, such as completing partially written functions, generating entire functions from docstrings, and predicting the next line of code. This aims to capture the diverse ways developers interact with code completion tools.
-
Baseline Models: The authors evaluated several state-of-the-art code completion models on the RepoMasterEval benchmark, including GPT-2, GPT-3, and CodeGen. The results showed that these models struggled to match the performance of human developers, particularly on more complex, repository-level tasks.
Critical Analysis
The RepoMasterEval benchmark represents an important step forward in evaluating the capabilities of code completion models in real-world settings. By using a diverse dataset of code from popular GitHub repositories, the authors have created a more challenging and realistic benchmark than previous alternatives.
However, the paper also acknowledges several limitations of the RepoMasterEval approach:
-
Scope: The dataset, while large, may still not capture the full breadth of coding tasks and styles encountered in industry. Expanding the benchmark to include an even wider range of repositories and programming languages could further improve its representativeness.
-
Task Design: The specific tasks included in the benchmark may not fully reflect the way developers actually use code completion tools in practice. Incorporating more user-centric evaluations, such as having developers provide feedback on the helpfulness of the model's suggestions, could provide additional insights.
-
Model Limitations: The relatively poor performance of the baseline models on the RepoMasterEval benchmark highlights the challenges of developing code completion systems that can match human-level capabilities. Further research is needed to address the limitations of existing language models in this domain.
Conclusion
The RepoMasterEval benchmark represents an important contribution to the field of code completion research. By providing a more realistic and comprehensive evaluation platform, the authors have created a valuable tool for assessing the capabilities of AI-powered code assistants in real-world software development scenarios.
The insights gained from this work could help drive the development of more practical and effective code completion tools, ultimately enhancing the productivity and creativity of software developers. As the field of AI-assisted coding continues to evolve, benchmarks like RepoMasterEval will play a crucial role in ensuring that these technologies live up to their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
RepoMasterEval: Evaluating Code Completion via Real-World Repositories
Qinyun Wu, Chao Peng, Pengfei Gao, Ruida Hu, Haoyu Gan, Bo Jiang, Jinhe Tang, Zhiwen Deng, Zhanming Guan, Cuiyun Gao, Xia Liu, Ping Yang
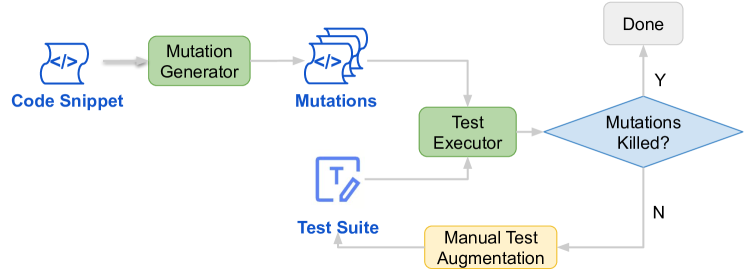
With the growing reliance on automated code completion tools in software development, the need for robust evaluation benchmarks has become critical. However, existing benchmarks focus more on code generation tasks in function and class level and provide rich text description to prompt the model. By contrast, such descriptive prompt is commonly unavailable in real development and code completion can occur in wider range of situations such as in the middle of a function or a code block. These limitations makes the evaluation poorly align with the practical scenarios of code completion tools. In this paper, we propose RepoMasterEval, a novel benchmark for evaluating code completion models constructed from real-world Python and TypeScript repositories. Each benchmark datum is generated by masking a code snippet (ground truth) from one source code file with existing test suites. To improve test accuracy of model generated code, we employ mutation testing to measure the effectiveness of the test cases and we manually crafted new test cases for those test suites with low mutation score. Our empirical evaluation on 6 state-of-the-art models shows that test argumentation is critical in improving the accuracy of the benchmark and RepoMasterEval is able to report difference in model performance in real-world scenarios. The deployment of RepoMasterEval in a collaborated company for one month also revealed that the benchmark is useful to give accurate feedback during model training and the score is in high correlation with the model's performance in practice. Based on our findings, we call for the software engineering community to build more LLM benchmarks tailored for code generation tools taking the practical and complex development environment into consideration.
Read more8/9/2024

0
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, Yongbin Li
How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
Read more5/31/2024

0
R2C2-Coder: Enhancing and Benchmarking Real-world Repository-level Code Completion Abilities of Code Large Language Models
Ken Deng, Jiaheng Liu, He Zhu, Congnan Liu, Jingxin Li, Jiakai Wang, Peng Zhao, Chenchen Zhang, Yanan Wu, Xueqiao Yin, Yuanxing Zhang, Wenbo Su, Bangyu Xiang, Tiezheng Ge, Bo Zheng
Code completion models have made significant progress in recent years. Recently, repository-level code completion has drawn more attention in modern software development, and several baseline methods and benchmarks have been proposed. However, existing repository-level code completion methods often fall short of fully using the extensive context of a project repository, such as the intricacies of relevant files and class hierarchies. Besides, the existing benchmarks usually focus on limited code completion scenarios, which cannot reflect the repository-level code completion abilities well of existing methods. To address these limitations, we propose the R2C2-Coder to enhance and benchmark the real-world repository-level code completion abilities of code Large Language Models, where the R2C2-Coder includes a code prompt construction method R2C2-Enhance and a well-designed benchmark R2C2-Bench. Specifically, first, in R2C2-Enhance, we first construct the candidate retrieval pool and then assemble the completion prompt by retrieving from the retrieval pool for each completion cursor position. Second, based on R2C2 -Enhance, we can construct a more challenging and diverse R2C2-Bench with training, validation and test splits, where a context perturbation strategy is proposed to simulate the real-world repository-level code completion well. Extensive results on multiple benchmarks demonstrate the effectiveness of our R2C2-Coder.
Read more6/5/2024

0
REPOEXEC: Evaluate Code Generation with a Repository-Level Executable Benchmark
Nam Le Hai, Dung Manh Nguyen, Nghi D. Q. Bui
CodeLLMs have gained widespread adoption for code generation tasks, yet their capacity to handle repository-level code generation with complex contextual dependencies remains underexplored. Our work underscores the critical importance of leveraging repository-level contexts to generate executable and functionally correct code. We present textbf{methodnamews}, a novel benchmark designed to evaluate repository-level code generation, with a focus on three key aspects: executability, functional correctness through comprehensive test case generation, and accurate utilization of cross-file contexts. Our study examines a controlled scenario where developers specify essential code dependencies (contexts), challenging models to integrate them effectively. Additionally, we introduce an instruction-tuned dataset that enhances CodeLLMs' ability to leverage dependencies, along with a new metric, textit{Dependency Invocation Rate (DIR)}, to quantify context utilization. Experimental results reveal that while pretrained LLMs demonstrate superior performance in terms of correctness, instruction-tuned models excel in context utilization and debugging capabilities. methodnamews offers a comprehensive evaluation framework for assessing code functionality and alignment with developer intent, thereby advancing the development of more reliable CodeLLMs for real-world applications. The dataset and source code are available at~url{https://github.com/FSoft-AI4Code/RepoExec}.
Read more9/4/2024