Importance Weighting Can Help Large Language Models Self-Improve

0

Sign in to get full access
Overview
- Large language models (LLMs) can self-improve through importance weighting techniques
- This can help LLMs learn more efficiently and overcome biases in their training data
- The paper explores this concept and provides experimental results to demonstrate its effectiveness
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes exhibit biases or lack certain knowledge due to the nature of their training data. <a href="https://aimodels.fyi/papers/arxiv/self-training-large-language-models-through-knowledge">Self-improvement techniques</a> can help LLMs learn more effectively and overcome these limitations.
One promising approach is importance weighting, where the model assigns greater weight to certain training examples that are more valuable or representative. This can help the model focus on the most informative parts of the data, leading to more efficient and accurate learning. By <a href="https://aimodels.fyi/papers/arxiv/take-essence-discard-dross-rethinking-data-selection">selectively prioritizing</a> the most relevant information, the model can better understand the underlying patterns and relationships in the data, ultimately improving its performance and reducing biases.
The paper explores how importance weighting can be used to help LLMs self-improve, enabling them to continuously refine their knowledge and capabilities over time. This could have significant implications for the development of more robust and adaptive AI systems that can better serve the needs of users and society.
Technical Explanation
The paper proposes a framework for importance weighting in the context of large language models (LLMs). The key idea is to assign higher weights to training examples that are more valuable or representative for the model's learning process.
The authors develop a method called Self-Supervised Importance Weighting (SSIW), which learns to predict the importance of each training example in an unsupervised manner. This is achieved by training a separate module within the LLM architecture to estimate the importance of each example, based on factors such as its uniqueness, difficulty, and relevance to the model's overall learning objectives.
During training, the LLM then uses these importance weights to prioritize the most informative examples, leading to more efficient and targeted learning. The authors demonstrate the effectiveness of this approach through experiments on various language modeling tasks, showing that SSIW can help LLMs achieve <a href="https://aimodels.fyi/papers/arxiv/aligning-large-language-models-self-generated-preference">better performance</a> and overcome biases present in the original training data.
Critical Analysis
The paper presents a compelling approach to help large language models continuously improve themselves through importance weighting. By focusing on the most valuable training examples, the model can learn more efficiently and overcome biases that may be present in the initial dataset.
However, the authors acknowledge that there are some potential limitations to this approach. For instance, the importance weighting mechanism itself could introduce new biases or distortions if not carefully designed and validated. There is also a risk of <a href="https://aimodels.fyi/papers/arxiv/pride-prejudice-llm-amplifies-self-bias-self">amplifying existing biases</a> if the model's self-assessment of importance is not well-aligned with the true informative value of the training examples.
Further research is needed to explore the long-term implications of this approach and how it can be seamlessly integrated into the overall training and deployment of large language models. Additionally, the authors suggest that investigating the interpretability and transparency of the importance weighting mechanism could be a valuable area for future work.
Conclusion
This paper presents an innovative approach to help large language models self-improve through the use of importance weighting techniques. By prioritizing the most valuable training examples, the model can learn more efficiently and overcome biases present in the original dataset.
The proposed Self-Supervised Importance Weighting (SSIW) framework demonstrates the potential of this approach, with experimental results showing improvements in language modeling performance and the ability to address certain biases. While there are some potential limitations and areas for further research, this work represents an important step towards the development of more robust and adaptive AI systems that can better serve the needs of users and society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Importance Weighting Can Help Large Language Models Self-Improve
Chunyang Jiang, Chi-min Chan, Wei Xue, Qifeng Liu, Yike Guo
Large language models (LLMs) have shown remarkable capability in numerous tasks and applications. However, fine-tuning LLMs using high-quality datasets under external supervision remains prohibitively expensive. In response, LLM self-improvement approaches have been vibrantly developed recently. The typical paradigm of LLM self-improvement involves training LLM on self-generated data, part of which may be detrimental and should be filtered out due to the unstable data quality. While current works primarily employs filtering strategies based on answer correctness, in this paper, we demonstrate that filtering out correct but with high distribution shift extent (DSE) samples could also benefit the results of self-improvement. Given that the actual sample distribution is usually inaccessible, we propose a new metric called DS weight to approximate DSE, inspired by the Importance Weighting methods. Consequently, we integrate DS weight with self-consistency to comprehensively filter the self-generated samples and fine-tune the language model. Experiments show that with only a tiny valid set (up to 5% size of the training set) to compute DS weight, our approach can notably promote the reasoning ability of current LLM self-improvement methods. The resulting performance is on par with methods that rely on external supervision from pre-trained reward models.
Read more8/20/2024
0
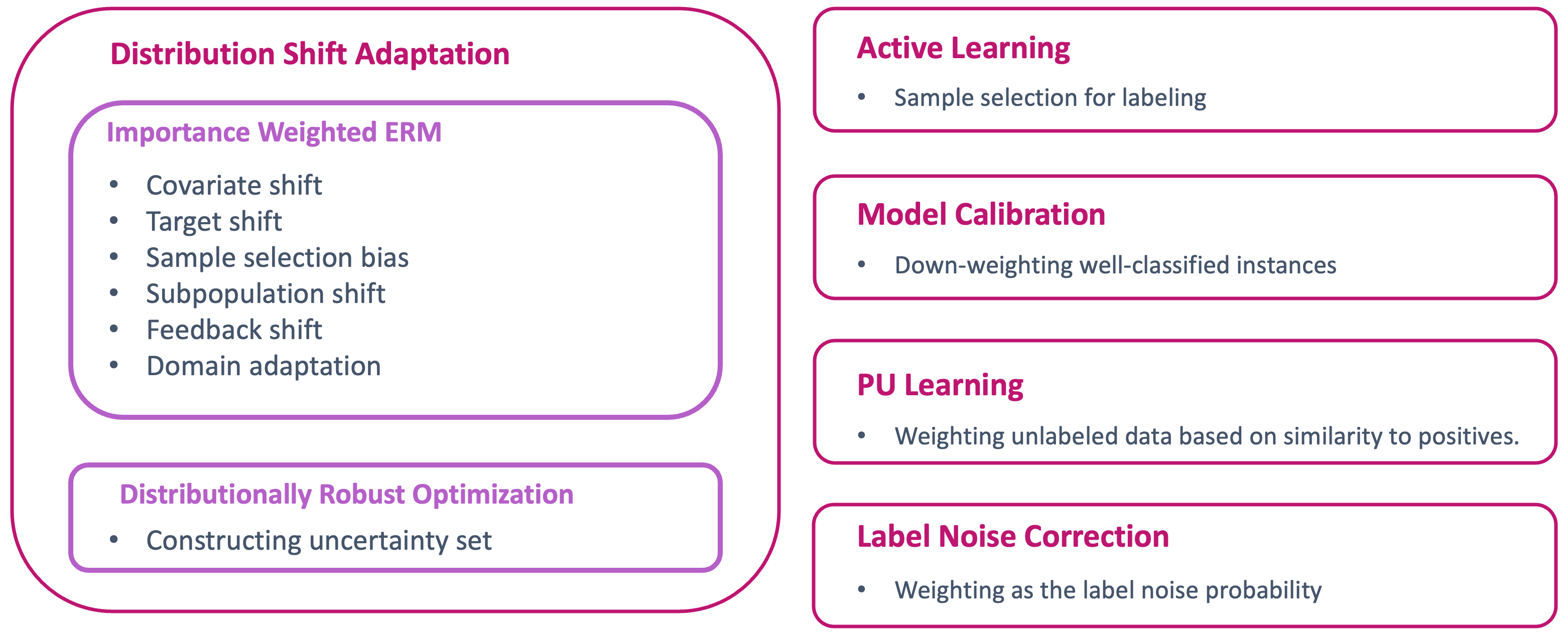
A Short Survey on Importance Weighting for Machine Learning
Masanari Kimura, Hideitsu Hino
Importance weighting is a fundamental procedure in statistics and machine learning that weights the objective function or probability distribution based on the importance of the instance in some sense. The simplicity and usefulness of the idea has led to many applications of importance weighting. For example, it is known that supervised learning under an assumption about the difference between the training and test distributions, called distribution shift, can guarantee statistically desirable properties through importance weighting by their density ratio. This survey summarizes the broad applications of importance weighting in machine learning and related research.
Read more5/15/2024
0
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
Read more6/18/2024

0
Towards Building a Robust Knowledge Intensive Question Answering Model with Large Language Models
Xingyun Hong, Yan Shao, Zhilin Wang, Manni Duan, Jin Xiongnan
The development of LLMs has greatly enhanced the intelligence and fluency of question answering, while the emergence of retrieval enhancement has enabled models to better utilize external information. However, the presence of noise and errors in retrieved information poses challenges to the robustness of LLMs. In this work, to evaluate the model's performance under multiple interferences, we first construct a dataset based on machine reading comprehension datasets simulating various scenarios, including critical information absence, noise, and conflicts. To address the issue of model accuracy decline caused by noisy external information, we propose a data augmentation-based fine-tuning method to enhance LLM's robustness against noise. Additionally, contrastive learning approach is utilized to preserve the model's discrimination capability of external information. We have conducted experiments on both existing LLMs and our approach, the results are evaluated by GPT-4, which indicates that our proposed methods improve model robustness while strengthening the model's discrimination capability.
Read more9/19/2024