A Short Survey on Importance Weighting for Machine Learning

0
Sign in to get full access
Overview
- This paper provides a short survey on the importance of weighting techniques in machine learning.
- It covers key concepts related to distribution shift adaptation, which is the process of adjusting machine learning models to account for differences between the training and deployment data distributions.
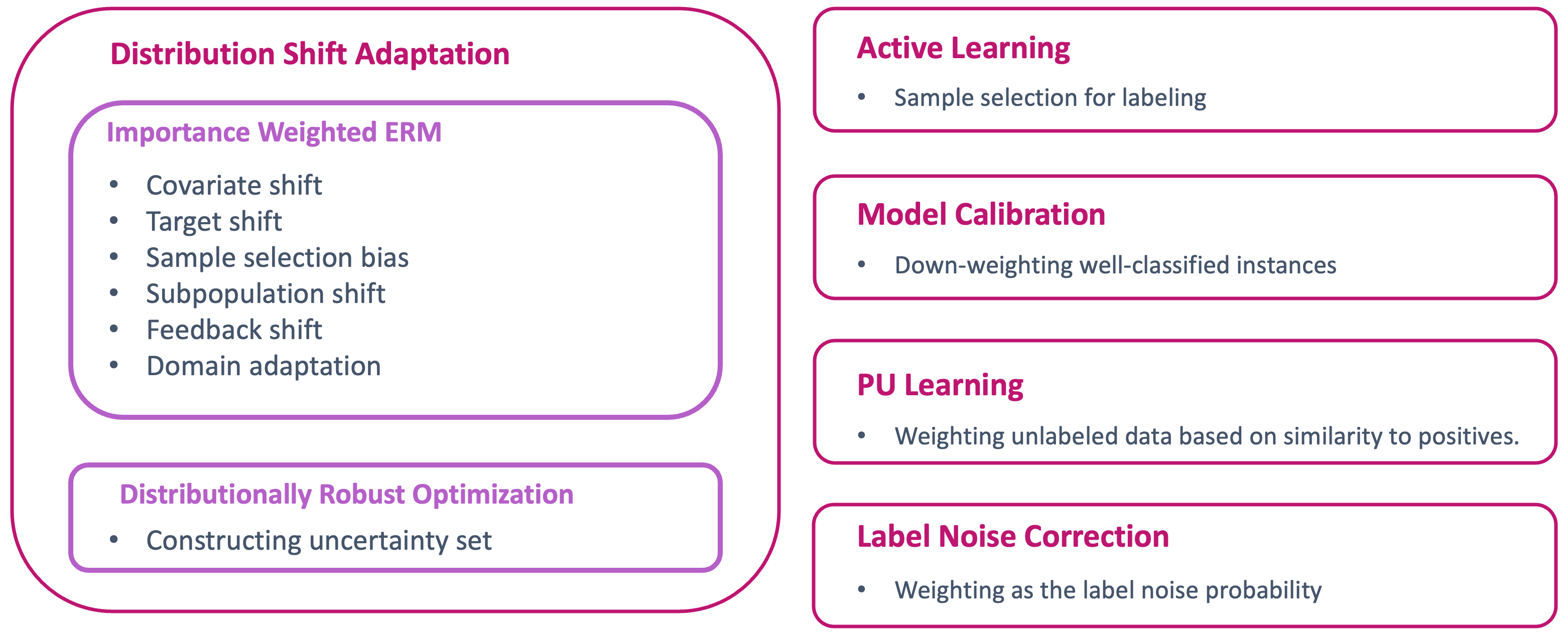
- The paper discusses various importance weighting methods and their applications, including Confident Feature Ranking, Guide to Feature Importance Methods for Scientific Inference, Hyperparameter Importance Analysis for Multi-Objective AutoML, Low Variance Off-Policy Evaluation in the State-Based, and Rashomon Importance: Getting Rid of Unstable Single.
Plain English Explanation
Machine learning models are often trained on data that doesn't perfectly match the real-world scenarios they'll be used in. This can lead to performance issues when the model is deployed. Importance weighting is a technique that adjusts the model to account for these differences, known as "distribution shift."
The paper discusses various methods for determining the importance of different features in a dataset. This can help identify which parts of the data are most critical for the model's performance. Some of the specific techniques covered include Confident Feature Ranking, which assesses how confident the model is in its feature importance estimates, and Rashomon Importance, which looks at the stability of feature importance across multiple models.
By understanding the relative importance of different features, machine learning practitioners can make more informed decisions about model design, data collection, and deployment. This can lead to improved model performance and better alignment with real-world needs.
Technical Explanation
The paper begins by introducing the concept of distribution shift, which occurs when the data used to train a machine learning model differs from the data the model will encounter in the real world. This can lead to significant performance degradation when the model is deployed.
The authors then discuss various importance weighting methods that can be used to adapt models to distribution shift. These include:
- Confident Feature Ranking: This technique assesses the confidence of a model's feature importance estimates, allowing practitioners to identify the most reliable and stable features.
- Guide to Feature Importance Methods for Scientific Inference: This framework provides guidance on selecting appropriate feature importance methods based on the goals of the analysis, such as predictive performance or scientific understanding.
- Hyperparameter Importance Analysis for Multi-Objective AutoML: This approach quantifies the relative importance of hyperparameters in the context of multi-objective optimization, helping to identify the most impactful hyperparameters.
- Low Variance Off-Policy Evaluation in the State-Based: This method for evaluating the performance of reinforcement learning policies in the face of distribution shift, reducing the variance of the estimates.
- Rashomon Importance: Getting Rid of Unstable Single: This technique examines the stability of feature importance across multiple models, providing a more robust measure of feature importance.
The paper also covers the mathematical formulations and intuitions behind these various importance weighting methods, as well as their applications and limitations.
Critical Analysis
The paper provides a comprehensive overview of the importance of weighting techniques in machine learning, particularly in the context of distribution shift. The authors do a commendable job of covering a wide range of relevant methods and their underlying principles.
One potential limitation of the survey is that it does not delve deeply into the empirical performance of these techniques or provide a comparative analysis. While the authors mention the applications and limitations of the different methods, a more thorough evaluation of their relative strengths and weaknesses would have been helpful.
Additionally, the paper does not address potential biases or ethical concerns that may arise from the use of importance weighting methods. As these techniques can have significant impacts on model performance and decision-making, it would be valuable to consider their societal implications and how to mitigate any adverse effects.
Further research could explore the integration of importance weighting with other model adaptation techniques, such as domain adaptation or transfer learning, to develop more holistic solutions for addressing distribution shift. Additionally, investigating the robustness of these methods to noisy or incomplete data would be a valuable area of study.
Conclusion
This paper provides a concise and informative survey of the importance of weighting techniques in machine learning, with a particular focus on distribution shift adaptation. The authors highlight several key methods and their underlying principles, demonstrating the value of understanding feature importance in improving model performance and alignment with real-world needs.
While the paper could benefit from a more in-depth empirical analysis and consideration of ethical implications, it serves as a valuable resource for machine learning practitioners and researchers interested in enhancing the reliability and robustness of their models in the face of distribution shift.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Short Survey on Importance Weighting for Machine Learning
Masanari Kimura, Hideitsu Hino
Importance weighting is a fundamental procedure in statistics and machine learning that weights the objective function or probability distribution based on the importance of the instance in some sense. The simplicity and usefulness of the idea has led to many applications of importance weighting. For example, it is known that supervised learning under an assumption about the difference between the training and test distributions, called distribution shift, can guarantee statistically desirable properties through importance weighting by their density ratio. This survey summarizes the broad applications of importance weighting in machine learning and related research.
Read more5/15/2024

0
Importance Weighting Can Help Large Language Models Self-Improve
Chunyang Jiang, Chi-min Chan, Wei Xue, Qifeng Liu, Yike Guo
Large language models (LLMs) have shown remarkable capability in numerous tasks and applications. However, fine-tuning LLMs using high-quality datasets under external supervision remains prohibitively expensive. In response, LLM self-improvement approaches have been vibrantly developed recently. The typical paradigm of LLM self-improvement involves training LLM on self-generated data, part of which may be detrimental and should be filtered out due to the unstable data quality. While current works primarily employs filtering strategies based on answer correctness, in this paper, we demonstrate that filtering out correct but with high distribution shift extent (DSE) samples could also benefit the results of self-improvement. Given that the actual sample distribution is usually inaccessible, we propose a new metric called DS weight to approximate DSE, inspired by the Importance Weighting methods. Consequently, we integrate DS weight with self-consistency to comprehensively filter the self-generated samples and fine-tune the language model. Experiments show that with only a tiny valid set (up to 5% size of the training set) to compute DS weight, our approach can notably promote the reasoning ability of current LLM self-improvement methods. The resulting performance is on par with methods that rely on external supervision from pre-trained reward models.
Read more8/20/2024
✨
0
Confident Feature Ranking
Bitya Neuhof, Yuval Benjamini
Machine learning models are widely applied in various fields. Stakeholders often use post-hoc feature importance methods to better understand the input features' contribution to the models' predictions. The interpretation of the importance values provided by these methods is frequently based on the relative order of the features (their ranking) rather than the importance values themselves. Since the order may be unstable, we present a framework for quantifying the uncertainty in global importance values. We propose a novel method for the post-hoc interpretation of feature importance values that is based on the framework and pairwise comparisons of the feature importance values. This method produces simultaneous confidence intervals for the features' ranks, which include the ``true'' (infinite sample) ranks with high probability, and enables the selection of the set of the top-k important features.
Read more4/19/2024
🎯
0
IW-GAE: Importance Weighted Group Accuracy Estimation for Improved Calibration and Model Selection in Unsupervised Domain Adaptation
Taejong Joo, Diego Klabjan
Distribution shifts pose significant challenges for model calibration and model selection tasks in the unsupervised domain adaptation problem -- a scenario where the goal is to perform well in a distribution shifted domain without labels. In this work, we tackle difficulties coming from distribution shifts by developing a novel importance weighted group accuracy estimator. Specifically, we present a new perspective of addressing the model calibration and model selection tasks by estimating the group accuracy. Then, we formulate an optimization problem for finding an importance weight that leads to an accurate group accuracy estimation with theoretical analyses. Our extensive experiments show that our approach improves state-of-the-art performances by 22% in the model calibration task and 14% in the model selection task.
Read more7/18/2024