Improved Communication-Privacy Trade-offs in $L_2$ Mean Estimation under Streaming Differential Privacy
2405.02341
0
0
Abstract
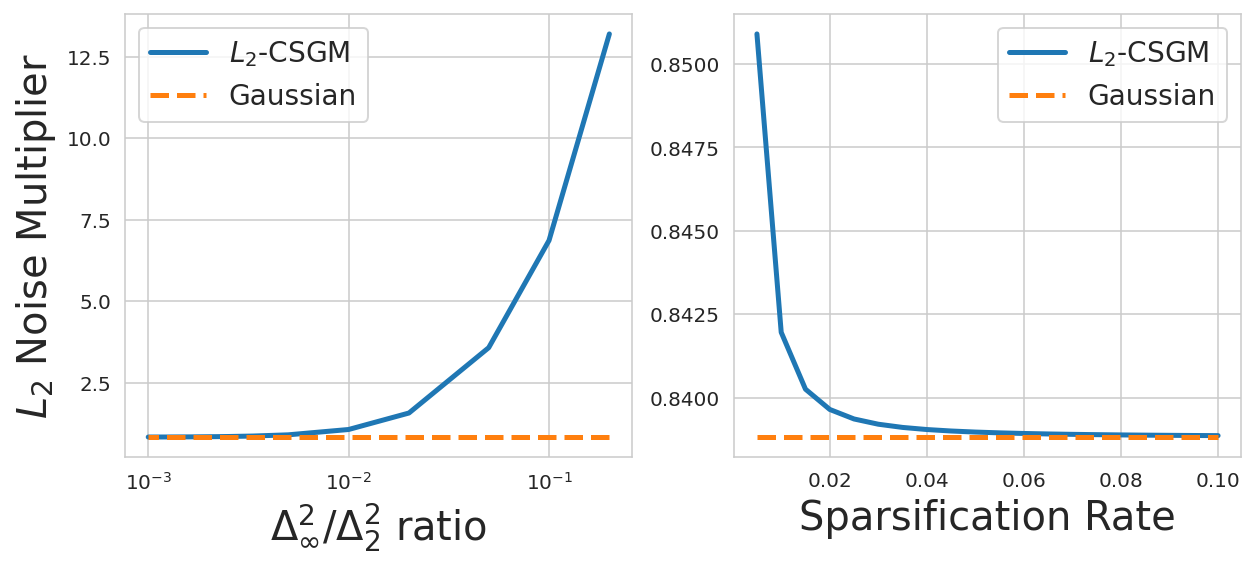
We study $L_2$ mean estimation under central differential privacy and communication constraints, and address two key challenges: firstly, existing mean estimation schemes that simultaneously handle both constraints are usually optimized for $L_infty$ geometry and rely on random rotation or Kashin's representation to adapt to $L_2$ geometry, resulting in suboptimal leading constants in mean square errors (MSEs); secondly, schemes achieving order-optimal communication-privacy trade-offs do not extend seamlessly to streaming differential privacy (DP) settings (e.g., tree aggregation or matrix factorization), rendering them incompatible with DP-FTRL type optimizers. In this work, we tackle these issues by introducing a novel privacy accounting method for the sparsified Gaussian mechanism that incorporates the randomness inherent in sparsification into the DP noise. Unlike previous approaches, our accounting algorithm directly operates in $L_2$ geometry, yielding MSEs that fast converge to those of the uncompressed Gaussian mechanism. Additionally, we extend the sparsification scheme to the matrix factorization framework under streaming DP and provide a precise accountant tailored for DP-FTRL type optimizers. Empirically, our method demonstrates at least a 100x improvement of compression for DP-SGD across various FL tasks.
Create account to get full access
Overview
- This paper explores improved communication-privacy trade-offs in L2 mean estimation under streaming differential privacy.
- It proposes new algorithms that provide better accuracy and communication efficiency compared to existing methods.
- The techniques leverage ideas from [plan-variance-aware-private-mean-estimation], [efficient-near-optimal-noise-generation-streaming-differential], [one-shot-empirical-privacy-estimation-federated-learning], [differentially-private-hierarchical-federated-learning], and [differentially-private-log-location-scale-regression-using].
Plain English Explanation
This research paper looks at a problem called "mean estimation" under a privacy constraint called "differential privacy." Mean estimation is the task of calculating the average value of a set of numbers. Differential privacy is a way to protect individual data points in a dataset while still allowing analysis of the overall dataset.
The key idea is to find ways to calculate the mean while using less communication between different parties, which is important for applications like federated learning where data is spread across many devices. The new algorithms developed in this paper provide better accuracy and communication efficiency compared to previous methods.
The paper builds on several related techniques, including ideas around understanding the statistical uncertainty ("plan variance") in mean estimation, generating noise in an efficient way for streaming data, estimating privacy loss empirically, and handling more complex statistical models like regression. By combining these concepts, the researchers were able to develop new algorithms that improve the communication-privacy trade-off for calculating the average of a dataset.
Technical Explanation
The paper proposes new algorithms for L2 mean estimation under streaming differential privacy. The key technical contributions are:
- A "plan-variance aware" estimator that explicitly accounts for the statistical uncertainty in the mean estimate, allowing for more accurate results.
- An efficient noise generation mechanism for the streaming setting, building on ideas from [efficient-near-optimal-noise-generation-streaming-differential].
- A technique to empirically estimate the privacy loss, inspired by [one-shot-empirical-privacy-estimation-federated-learning], which avoids the need for complex privacy accounting.
- Extensions to handle more complex statistical models like [differentially-private-log-location-scale-regression-using].
The algorithms are evaluated both theoretically and empirically, showing significant improvements in communication cost and estimation accuracy compared to prior work on differentially private mean estimation, such as [plan-variance-aware-private-mean-estimation] and [differentially-private-hierarchical-federated-learning].
Critical Analysis
The paper makes a number of important contributions to the field of differentially private data analysis. The proposed algorithms provide a compelling trade-off between communication, accuracy, and privacy - a key challenge in many real-world applications.
However, the analysis is primarily focused on the L2 mean estimation problem. While this is an important primitive, it would be valuable to understand how these techniques generalize to other statistical tasks, such as regression or classification. Additionally, the empirical evaluation is conducted on synthetic datasets, so further work is needed to validate the performance on real-world data.
Another potential limitation is the reliance on certain assumptions, such as the availability of an unbiased estimate of the plan variance. In practice, this may not always be the case, and the impact of estimation errors should be explored.
Overall, this is a strong piece of research that advances the state-of-the-art in differentially private mean estimation. The ideas presented could have a significant impact on applications that require privacy-preserving data analysis at scale, such as federated learning and distributed data processing.
Conclusion
This paper introduces new algorithms for L2 mean estimation under streaming differential privacy, which provide improved communication-privacy trade-offs compared to previous methods. By leveraging ideas from related work on plan-variance aware estimation, efficient noise generation, and empirical privacy accounting, the researchers were able to develop techniques that are both more accurate and more communication-efficient.
These advances could have important implications for a variety of applications, such as federated learning and distributed data analysis, where privacy protection and communication efficiency are critical concerns. While the focus of this paper is on mean estimation, the underlying principles could potentially be extended to other statistical tasks, opening up new avenues for future research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Private Mean Estimation with Person-Level Differential Privacy
Sushant Agarwal, Gautam Kamath, Mahbod Majid, Argyris Mouzakis, Rose Silver, Jonathan Ullman
0
0
We study differentially private (DP) mean estimation in the case where each person holds multiple samples. Commonly referred to as the user-level setting, DP here requires the usual notion of distributional stability when all of a person's datapoints can be modified. Informally, if $n$ people each have $m$ samples from an unknown $d$-dimensional distribution with bounded $k$-th moments, we show that [n = tilde Thetaleft(frac{d}{alpha^2 m} + frac{d }{ alpha m^{1/2} varepsilon} + frac{d}{alpha^{k/(k-1)} m varepsilon} + frac{d}{varepsilon}right)] people are necessary and sufficient to estimate the mean up to distance $alpha$ in $ell_2$-norm under $varepsilon$-differential privacy (and its common relaxations). In the multivariate setting, we give computationally efficient algorithms under approximate DP (with slightly degraded sample complexity) and computationally inefficient algorithms under pure DP, and our nearly matching lower bounds hold for the most permissive case of approximate DP. Our computationally efficient estimators are based on the well known noisy-clipped-mean approach, but the analysis for our setting requires new bounds on the tails of sums of independent, vector-valued, bounded-moments random variables, and a new argument for bounding the bias introduced by clipping.
6/3/2024

PLAN: Variance-Aware Private Mean Estimation
Martin Aumuller, Christian Janos Lebeda, Boel Nelson, Rasmus Pagh
0
0
Differentially private mean estimation is an important building block in privacy-preserving algorithms for data analysis and machine learning. Though the trade-off between privacy and utility is well understood in the worst case, many datasets exhibit structure that could potentially be exploited to yield better algorithms. In this paper we present $textit{Private Limit Adapted Noise}$ (PLAN), a family of differentially private algorithms for mean estimation in the setting where inputs are independently sampled from a distribution $mathcal{D}$ over $mathbf{R}^d$, with coordinate-wise standard deviations $boldsymbol{sigma} in mathbf{R}^d$. Similar to mean estimation under Mahalanobis distance, PLAN tailors the shape of the noise to the shape of the data, but unlike previous algorithms the privacy budget is spent non-uniformly over the coordinates. Under a concentration assumption on $mathcal{D}$, we show how to exploit skew in the vector $boldsymbol{sigma}$, obtaining a (zero-concentrated) differentially private mean estimate with $ell_2$ error proportional to $|boldsymbol{sigma}|_1$. Previous work has either not taken $boldsymbol{sigma}$ into account, or measured error in Mahalanobis distance $unicode{x2013}$ in both cases resulting in $ell_2$ error proportional to $sqrt{d}|boldsymbol{sigma}|_2$, which can be up to a factor $sqrt{d}$ larger. To verify the effectiveness of PLAN, we empirically evaluate accuracy on both synthetic and real world data.
4/11/2024
👨🏫
A Huber Loss Minimization Approach to Mean Estimation under User-level Differential Privacy
Puning Zhao, Lifeng Lai, Li Shen, Qingming Li, Jiafei Wu, Zhe Liu
0
0
Privacy protection of users' entire contribution of samples is important in distributed systems. The most effective approach is the two-stage scheme, which finds a small interval first and then gets a refined estimate by clipping samples into the interval. However, the clipping operation induces bias, which is serious if the sample distribution is heavy-tailed. Besides, users with large local sample sizes can make the sensitivity much larger, thus the method is not suitable for imbalanced users. Motivated by these challenges, we propose a Huber loss minimization approach to mean estimation under user-level differential privacy. The connecting points of Huber loss can be adaptively adjusted to deal with imbalanced users. Moreover, it avoids the clipping operation, thus significantly reducing the bias compared with the two-stage approach. We provide a theoretical analysis of our approach, which gives the noise strength needed for privacy protection, as well as the bound of mean squared error. The result shows that the new method is much less sensitive to the imbalance of user-wise sample sizes and the tail of sample distributions. Finally, we perform numerical experiments to validate our theoretical analysis.
5/24/2024
🎲
Robustness Implies Privacy in Statistical Estimation
Samuel B. Hopkins, Gautam Kamath, Mahbod Majid, Shyam Narayanan
0
0
We study the relationship between adversarial robustness and differential privacy in high-dimensional algorithmic statistics. We give the first black-box reduction from privacy to robustness which can produce private estimators with optimal tradeoffs among sample complexity, accuracy, and privacy for a wide range of fundamental high-dimensional parameter estimation problems, including mean and covariance estimation. We show that this reduction can be implemented in polynomial time in some important special cases. In particular, using nearly-optimal polynomial-time robust estimators for the mean and covariance of high-dimensional Gaussians which are based on the Sum-of-Squares method, we design the first polynomial-time private estimators for these problems with nearly-optimal samples-accuracy-privacy tradeoffs. Our algorithms are also robust to a nearly optimal fraction of adversarially-corrupted samples.
6/18/2024