Improved Modelling of Federated Datasets using Mixtures-of-Dirichlet-Multinomials
2406.02416
0
0
Abstract
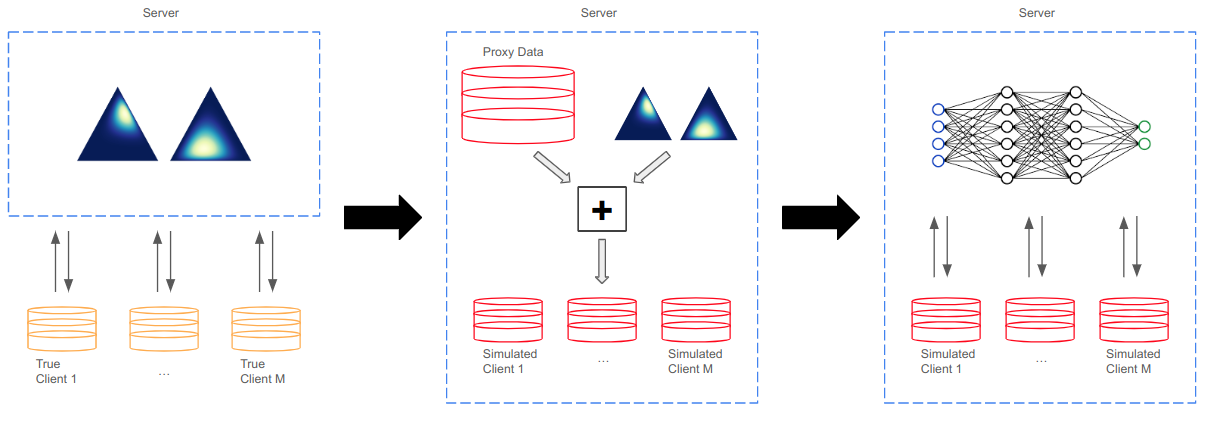
In practice, training using federated learning can be orders of magnitude slower than standard centralized training. This severely limits the amount of experimentation and tuning that can be done, making it challenging to obtain good performance on a given task. Server-side proxy data can be used to run training simulations, for instance for hyperparameter tuning. This can greatly speed up the training pipeline by reducing the number of tuning runs to be performed overall on the true clients. However, it is challenging to ensure that these simulations accurately reflect the dynamics of the real federated training. In particular, the proxy data used for simulations often comes as a single centralized dataset without a partition into distinct clients, and partitioning this data in a naive way can lead to simulations that poorly reflect real federated training. In this paper we address the challenge of how to partition centralized data in a way that reflects the statistical heterogeneity of the true federated clients. We propose a fully federated, theoretically justified, algorithm that efficiently learns the distribution of the true clients and observe improved server-side simulations when using the inferred distribution to create simulated clients from the centralized data.
Create account to get full access
Overview
- Proposes a new approach to modeling federated datasets using mixtures of Dirichlet-multinomial distributions
- Aims to better capture the heterogeneous nature of data distributed across multiple devices or clients in a federated learning setting
- Introduces a hierarchical Bayesian model and associated inference algorithms for learning the model parameters
Plain English Explanation
This research paper presents a novel way to model the data used in federated learning, which is a type of machine learning where models are trained on data distributed across many different devices or clients, rather than a centralized server.
The key insight is that the data on different devices may have very different statistical properties, and using a single model to represent all of this data may not be accurate. Instead, the researchers propose using a mixture of Dirichlet-multinomial distributions to better capture the diversity and heterogeneity of the data.
The Dirichlet-multinomial distribution is a flexible statistical model that can represent different types of discrete data, like text or categorical variables. By using a mixture of these distributions, the model can learn to associate different parts of the overall dataset with different statistical patterns, rather than trying to fit a one-size-fits-all model.
The researchers develop a hierarchical Bayesian framework to learn the parameters of this mixture model from the federated data, allowing the model to automatically discover the underlying statistical structure without requiring manual tuning. This provides a more robust and accurate way to model federated datasets compared to previous approaches.
Technical Explanation
The paper introduces a Mixtures-of-Dirichlet-Multinomials (MoDM) model for federated datasets. The core idea is to use a hierarchical Bayesian framework to learn a mixture of Dirichlet-multinomial distributions, where each component in the mixture represents a distinct statistical pattern in the data distributed across clients.
Formally, the MoDM model assumes that each client's data is generated from one of K latent mixture components, where each component is a Dirichlet-multinomial distribution. The model learns the mixing proportions that determine which component generates each client's data, as well as the Dirichlet-multinomial parameters for each component.
The authors develop an efficient variational inference algorithm to learn the model parameters from the federated data. This allows the model to automatically discover the underlying statistical structure without requiring manual tuning of the number of mixture components or other hyperparameters.
The key advantages of the MoDM approach are:
- Flexibility: The mixture model can capture diverse statistical patterns in the federated data, unlike a single global model.
- Interpretability: The learned mixture components provide insight into the heterogeneous nature of the data distribution across clients.
- Robustness: The hierarchical Bayesian formulation makes the model more resilient to noise and outliers in the federated data.
The authors demonstrate the effectiveness of MoDM on several federated learning benchmarks, showing improved performance compared to baseline federated learning methods.
Critical Analysis
The MoDM model presented in this paper offers a promising approach to modeling the heterogeneous nature of federated datasets. By using a flexible mixture-of-distributions framework, the model can better capture the diverse statistical patterns that may exist across the data distributed on different client devices.
One potential limitation is the computational cost of the variational inference algorithm, especially as the number of mixture components or the size of the federated dataset increases. The authors do not provide a detailed analysis of the scalability of their approach. Further research on improving the efficiency of the inference process would be valuable.
Additionally, the paper does not investigate the robustness of the MoDM model to challenges like non-i.i.d. data distributions or client drift that are common in real-world federated learning settings. Exploring the model's performance under these more realistic conditions would help validate its practical applicability.
Another area for further research could be leveraging synthetic data generation to improve the efficiency and convergence of the federated learning process using the MoDM model. Combining the model's flexibility with techniques for generating high-quality synthetic data could lead to notable improvements in federated learning performance.
Overall, the MoDM model represents an important step forward in modeling the statistical complexity of federated datasets. With further research to address its limitations and expand its capabilities, this approach could become a valuable tool for improving the reliability and effectiveness of federated learning systems.
Conclusion
This paper introduces a Mixtures-of-Dirichlet-Multinomials (MoDM) model for improving the modeling of federated datasets. The key insight is that a single global model may not be able to accurately capture the heterogeneous nature of data distributed across multiple client devices in a federated learning setting.
The MoDM approach instead uses a flexible mixture-of-distributions framework, where each component in the mixture represents a distinct statistical pattern in the federated data. The authors develop an efficient variational inference algorithm to learn the model parameters, allowing the approach to automatically discover the underlying structure without manual tuning.
Experiments on federated learning benchmarks show that the MoDM model can outperform baseline methods, demonstrating its potential to enhance the accuracy and robustness of federated learning systems. Further research is needed to address the computational efficiency of the inference process and the model's performance under more realistic federated learning conditions, but this work represents an important step forward in this increasingly important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Exploring One-shot Semi-supervised Federated Learning with A Pre-trained Diffusion Model
Mingzhao Yang, Shangchao Su, Bin Li, Xiangyang Xue
0
0
Recently, semi-supervised federated learning (semi-FL) has been proposed to handle the commonly seen real-world scenarios with labeled data on the server and unlabeled data on the clients. However, existing methods face several challenges such as communication costs, data heterogeneity, and training pressure on client devices. To address these challenges, we introduce the powerful diffusion models (DM) into semi-FL and propose FedDISC, a Federated Diffusion-Inspired Semi-supervised Co-training method. Specifically, we first extract prototypes of the labeled server data and use these prototypes to predict pseudo-labels of the client data. For each category, we compute the cluster centroids and domain-specific representations to signify the semantic and stylistic information of their distributions. After adding noise, these representations are sent back to the server, which uses the pre-trained DM to generate synthetic datasets complying with the client distributions and train a global model on it. With the assistance of vast knowledge within DM, the synthetic datasets have comparable quality and diversity to the client images, subsequently enabling the training of global models that achieve performance equivalent to or even surpassing the ceiling of supervised centralized training. FedDISC works within one communication round, does not require any local training, and involves very minimal information uploading, greatly enhancing its practicality. Extensive experiments on three large-scale datasets demonstrate that FedDISC effectively addresses the semi-FL problem on non-IID clients and outperforms the compared SOTA methods. Sufficient visualization experiments also illustrate that the synthetic dataset generated by FedDISC exhibits comparable diversity and quality to the original client dataset, with a neglectable possibility of leaking privacy-sensitive information of the clients.
6/13/2024
Federated Learning under Partially Class-Disjoint Data via Manifold Reshaping
Ziqing Fan, Jiangchao Yao, Ruipeng Zhang, Lingjuan Lyu, Ya Zhang, Yanfeng Wang
0
0
Statistical heterogeneity severely limits the performance of federated learning (FL), motivating several explorations e.g., FedProx, MOON and FedDyn, to alleviate this problem. Despite effectiveness, their considered scenario generally requires samples from almost all classes during the local training of each client, although some covariate shifts may exist among clients. In fact, the natural case of partially class-disjoint data (PCDD), where each client contributes a few classes (instead of all classes) of samples, is practical yet underexplored. Specifically, the unique collapse and invasion characteristics of PCDD can induce the biased optimization direction in local training, which prevents the efficiency of federated learning. To address this dilemma, we propose a manifold reshaping approach called FedMR to calibrate the feature space of local training. Our FedMR adds two interplaying losses to the vanilla federated learning: one is intra-class loss to decorrelate feature dimensions for anti-collapse; and the other one is inter-class loss to guarantee the proper margin among categories in the feature expansion. We conduct extensive experiments on a range of datasets to demonstrate that our FedMR achieves much higher accuracy and better communication efficiency. Source code is available at: https://github.com/MediaBrain-SJTU/FedMR.git.
6/4/2024
🔮
Locally Adaptive Federated Learning
Sohom Mukherjee, Nicolas Loizou, Sebastian U. Stich
0
0
Federated learning is a paradigm of distributed machine learning in which multiple clients coordinate with a central server to learn a model, without sharing their own training data. Standard federated optimization methods such as Federated Averaging (FedAvg) ensure balance among the clients by using the same stepsize for local updates on all clients. However, this means that all clients need to respect the global geometry of the function which could yield slow convergence. In this work, we propose locally adaptive federated learning algorithms, that leverage the local geometric information for each client function. We show that such locally adaptive methods with uncoordinated stepsizes across all clients can be particularly efficient in interpolated (overparameterized) settings, and analyze their convergence in the presence of heterogeneous data for convex and strongly convex settings. We validate our theoretical claims by performing illustrative experiments for both i.i.d. non-i.i.d. cases. Our proposed algorithms match the optimization performance of tuned FedAvg in the convex setting, outperform FedAvg as well as state-of-the-art adaptive federated algorithms like FedAMS for non-convex experiments, and come with superior generalization performance.
5/15/2024

Hybrid FedGraph: An efficient hybrid federated learning algorithm using graph convolutional neural network
Jaeyeon Jang, Diego Klabjan, Veena Mendiratta, Fanfei Meng
0
0
Federated learning is an emerging paradigm for decentralized training of machine learning models on distributed clients, without revealing the data to the central server. Most existing works have focused on horizontal or vertical data distributions, where each client possesses different samples with shared features, or each client fully shares only sample indices, respectively. However, the hybrid scheme is much less studied, even though it is much more common in the real world. Therefore, in this paper, we propose a generalized algorithm, FedGraph, that introduces a graph convolutional neural network to capture feature-sharing information while learning features from a subset of clients. We also develop a simple but effective clustering algorithm that aggregates features produced by the deep neural networks of each client while preserving data privacy.
4/16/2024