Worldwide Federated Training of Language Models
2405.14446
0
0
🏋️
Abstract
The reliance of language model training on massive amounts of computation and vast datasets scraped from potentially low-quality, copyrighted, or sensitive data has come into question practically, legally, and ethically. Federated learning provides a plausible alternative by enabling previously untapped data to be voluntarily gathered from collaborating organizations. However, when scaled globally, federated learning requires collaboration across heterogeneous legal, security, and privacy regimes while accounting for the inherent locality of language data; this further exacerbates the established challenge of federated statistical heterogeneity. We propose a Worldwide Federated Language Model Training~(WorldLM) system based on federations of federations, where each federation has the autonomy to account for factors such as its industry, operating jurisdiction, or competitive environment. WorldLM enables such autonomy in the presence of statistical heterogeneity via partial model localization by allowing sub-federations to attentively aggregate key layers from their constituents. Furthermore, it can adaptively share information across federations via residual layer embeddings. Evaluations of language modeling on naturally heterogeneous datasets show that WorldLM outperforms standard federations by up to $1.91times$, approaches the personalized performance of fully local models, and maintains these advantages under privacy-enhancing techniques.
Create account to get full access
Overview
- The reliance of language model training on vast datasets and computational resources has raised practical, legal, and ethical concerns.
- Federated learning provides a potential solution by enabling the use of data from collaborating organizations.
- However, scaling federated learning globally introduces challenges around heterogeneous legal, security, and privacy regimes, as well as the inherent locality of language data.
Plain English Explanation
The training of large language models, such as those used in chatbots and virtual assistants, typically requires access to massive amounts of text data and immense computational power. This reliance on vast datasets and resources has raised various concerns, including practical issues around data quality and copyright, as well as legal and ethical questions.
Federated learning offers a promising alternative approach, where data from multiple collaborating organizations can be used to train the language model without the need to centralize the data. This allows for the tapping of previously untapped data sources.
However, scaling federated learning globally presents additional challenges. When working across different legal jurisdictions, security protocols, and privacy regimes, it becomes more complex to ensure the language model is trained effectively. Furthermore, language data can be inherently local, meaning that the way people use language can vary significantly based on their geographic location, industry, or cultural context.
Technical Explanation
The paper proposes a system called Worldwide Federated Language Model Training (WorldLM) to address these challenges. WorldLM is based on the concept of "federations of federations," where each local federation has the autonomy to account for factors such as industry, jurisdiction, or competitive environment.
This autonomy is enabled through a technique called "partial model localization," which allows sub-federations to selectively aggregate key layers from their constituent models. This helps the system adapt to the inherent statistical heterogeneity of language data across different contexts.
Additionally, WorldLM can adaptively share information across federations via "residual layer embeddings." This allows the system to maintain performance advantages while preserving the benefits of federated learning, such as data privacy and reduced computational requirements.
The paper evaluates the performance of WorldLM on naturally heterogeneous language datasets and shows that it outperforms standard federated learning approaches by up to 1.91 times. It also demonstrates that WorldLM can approach the personalized performance of fully local models while maintaining these advantages even when incorporating privacy-enhancing techniques.
Critical Analysis
The paper addresses an important challenge in the development of large language models, namely, the reliance on centralized datasets and computational resources. The proposed WorldLM system offers a promising solution by enabling federated learning at scale while accounting for the inherent heterogeneity of language data.
However, the paper does not delve into potential limitations or concerns that may arise in real-world deployment scenarios. For example, the feasibility of establishing and governing the complex "federations of federations" structure, the potential for collusion or manipulation within these federated systems, and the long-term sustainability of the model-sharing approach could be areas for further exploration.
Additionally, the paper does not address potential biases or fairness issues that may arise from the uneven distribution of language data across different contexts. Blind federated learning techniques could be an interesting direction to explore in this regard.
Overall, the WorldLM proposal offers a compelling approach to address the challenges of large language model training, but further research is needed to fully understand its practical implications and potential limitations.
Conclusion
The paper presents a novel system called WorldLM that aims to overcome the limitations of relying on centralized datasets and computational resources for large language model training. By leveraging federated learning with a hierarchical "federations of federations" structure, WorldLM is designed to adapt to the inherent heterogeneity of language data while preserving privacy and reducing computational demands.
The technical evaluation shows promising results, with WorldLM outperforming standard federated learning approaches and approaching the personalized performance of fully local models. This suggests that the proposed system could be a viable solution for enabling the development of large language models in a more scalable and ethical manner.
As the field of natural language processing continues to evolve, the challenges addressed by this research will likely become increasingly important. The WorldLM approach offers a thought-provoking direction for future large language model pre-training and federated learning research, with potential implications for a wide range of language-based applications and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The Future of Large Language Model Pre-training is Federated
Lorenzo Sani, Alex Iacob, Zeyu Cao, Bill Marino, Yan Gao, Tomas Paulik, Wanru Zhao, William F. Shen, Preslav Aleksandrov, Xinchi Qiu, Nicholas D. Lane
0
0
Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
5/20/2024
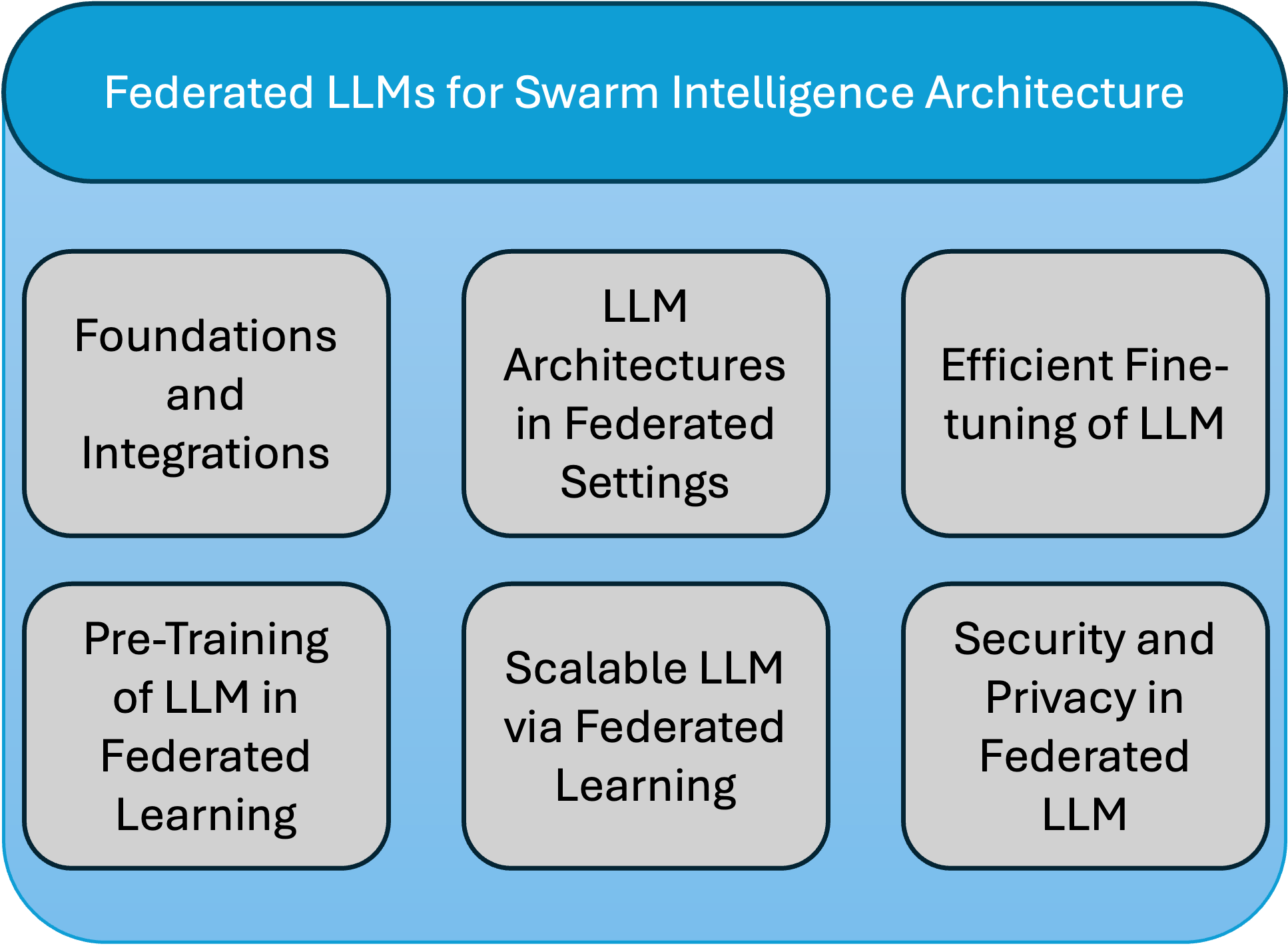
Federated Learning driven Large Language Models for Swarm Intelligence: A Survey
Youyang Qu
0
0
Federated learning (FL) offers a compelling framework for training large language models (LLMs) while addressing data privacy and decentralization challenges. This paper surveys recent advancements in the federated learning of large language models, with a particular focus on machine unlearning, a crucial aspect for complying with privacy regulations like the Right to be Forgotten. Machine unlearning in the context of federated LLMs involves systematically and securely removing individual data contributions from the learned model without retraining from scratch. We explore various strategies that enable effective unlearning, such as perturbation techniques, model decomposition, and incremental learning, highlighting their implications for maintaining model performance and data privacy. Furthermore, we examine case studies and experimental results from recent literature to assess the effectiveness and efficiency of these approaches in real-world scenarios. Our survey reveals a growing interest in developing more robust and scalable federated unlearning methods, suggesting a vital area for future research in the intersection of AI ethics and distributed machine learning technologies.
6/17/2024
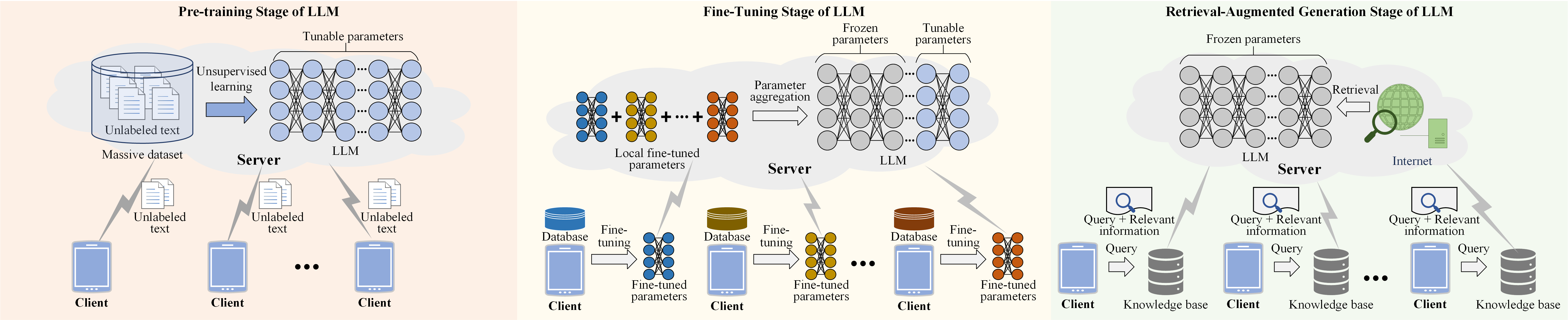
Personalized Wireless Federated Learning for Large Language Models
Feibo Jiang, Li Dong, Siwei Tu, Yubo Peng, Kezhi Wang, Kun Yang, Cunhua Pan, Dusit Niyato
0
0
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their deployment in wireless networks still face challenges, i.e., a lack of privacy and security protection mechanisms. Federated Learning (FL) has emerged as a promising approach to address these challenges. Yet, it suffers from issues including inefficient handling with big and heterogeneous data, resource-intensive training, and high communication overhead. To tackle these issues, we first compare different learning stages and their features of LLMs in wireless networks. Next, we introduce two personalized wireless federated fine-tuning methods with low communication overhead, i.e., (1) Personalized Federated Instruction Tuning (PFIT), which employs reinforcement learning to fine-tune local LLMs with diverse reward models to achieve personalization; (2) Personalized Federated Task Tuning (PFTT), which can leverage global adapters and local Low-Rank Adaptations (LoRA) to collaboratively fine-tune local LLMs, where the local LoRAs can be applied to achieve personalization without aggregation. Finally, we perform simulations to demonstrate the effectiveness of the proposed two methods and comprehensively discuss open issues.
4/23/2024
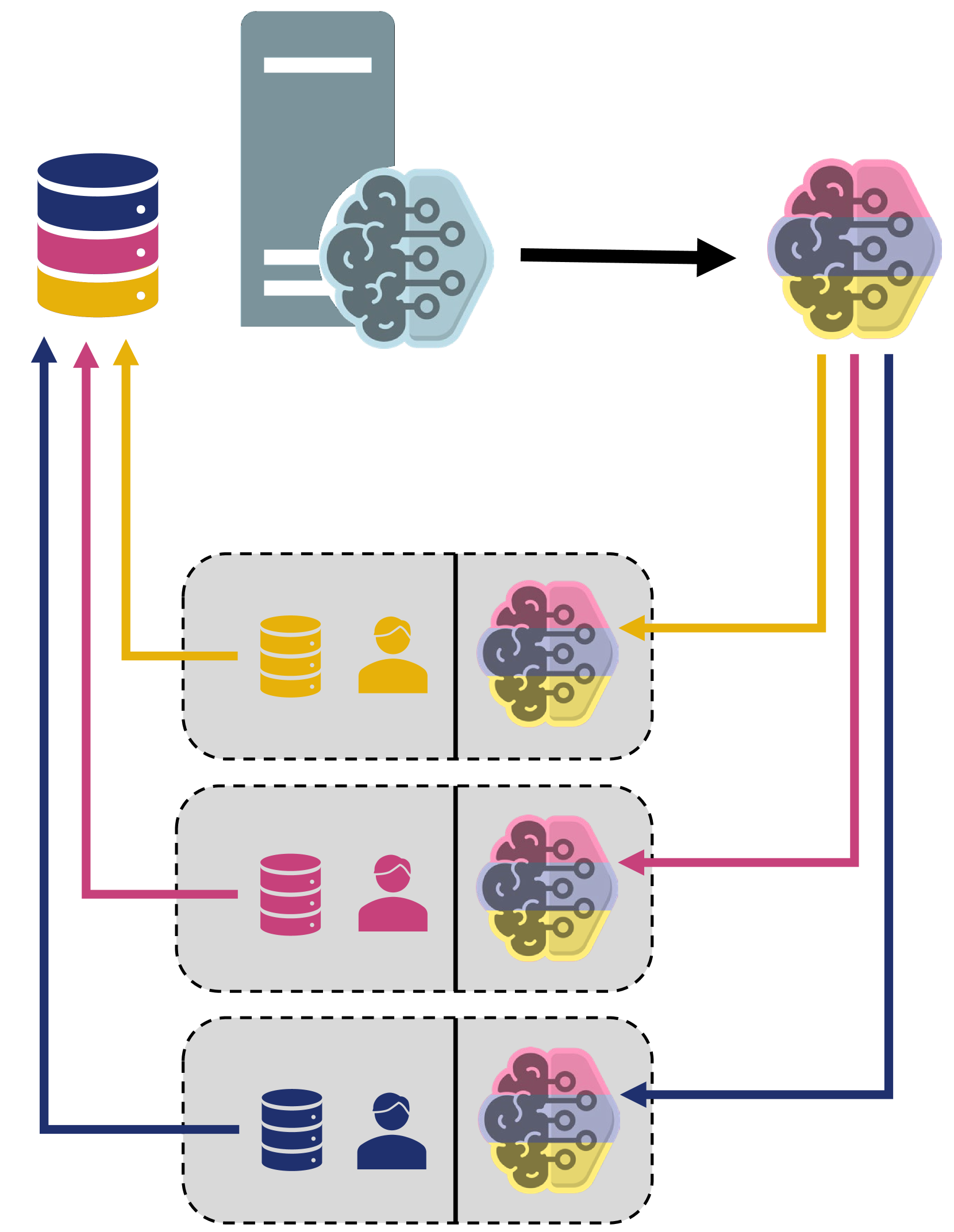
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
0
0
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
5/28/2024