Improving Accuracy-robustness Trade-off via Pixel Reweighted Adversarial Training

0
Sign in to get full access
Overview
- This paper proposes a new adversarial training method called Pixel Reweighted Adversarial Training (PRAT) to improve the tradeoff between accuracy and robustness of deep neural networks.
- The key idea is to dynamically reweight the importance of different pixels during adversarial training to focus on the most informative regions for classification.
- The authors demonstrate that PRAT can outperform standard adversarial training on benchmark tasks like ImageNet, improving both clean accuracy and robustness to adversarial attacks.
Plain English Explanation
Deep neural networks have become powerful tools for many machine learning tasks, but they can be vulnerable to adversarial attacks - small, carefully crafted perturbations to the input that cause the model to make mistakes. Adversarial training is a technique to improve a model's robustness by training it on these adversarial examples.
However, there is often a tradeoff between a model's accuracy on clean, unperturbed data and its robustness to adversarial attacks. The Pixel Reweighted Adversarial Training (PRAT) method proposed in this paper aims to address this by dynamically focusing the training on the most informative pixels for classification.
The key idea is that not all pixels in an image are equally important for the model's decision-making. PRAT assigns higher weights to the pixels that are more important, and lower weights to less informative pixels, during the adversarial training process. This allows the model to learn more robust features while maintaining good clean accuracy.
The authors show that PRAT can outperform standard adversarial training on benchmark tasks like ImageNet, improving both the model's accuracy on clean data and its robustness to adversarial attacks. This suggests that dynamically reweighting pixels during training can be a effective way to navigate the accuracy-robustness tradeoff.
Technical Explanation
The paper first provides background on the accuracy-robustness tradeoff in deep learning, where improving a model's robustness to adversarial attacks often comes at the cost of reduced clean accuracy.
The authors then introduce the Pixel Reweighted Adversarial Training (PRAT) method. PRAT works by dynamically reweighting the importance of different pixels in the input during the adversarial training process. The key idea is to focus the training on the most informative pixels for classification, rather than treating all pixels equally.
Specifically, PRAT computes a per-pixel importance score based on the gradients of the model's output with respect to the input pixels. Pixels with larger gradients are considered more important and are given higher weights in the adversarial training loss function. This encourages the model to learn more robust features in the informative regions of the input.
The authors evaluate PRAT on standard benchmark tasks like ImageNet classification, and compare it to baseline adversarial training methods. They show that PRAT can achieve better clean accuracy and robustness to adversarial attacks compared to these baselines. For example, on ImageNet, PRAT improves the clean accuracy by 2-3% and the robust accuracy by 4-5% over standard adversarial training.
The paper also provides theoretical analysis to understand why PRAT can improve the accuracy-robustness tradeoff. The authors show that the per-pixel reweighting can be seen as a form of regularization that encourages the model to learn more robust features.
Overall, this work presents a novel adversarial training method that dynamically focuses on the most informative pixels, leading to improvements in both clean accuracy and adversarial robustness.
Critical Analysis
The key strength of this work is the intuitive idea of dynamically reweighting pixels during adversarial training to focus on the most informative regions. This builds on prior research showing the importance of the layered intrinsic dimensionality of deep models, and suggests that selectively attending to the most important features can be an effective way to navigate the accuracy-robustness tradeoff.
That said, the paper does not provide a comprehensive exploration of the limitations and potential issues with PRAT. For example, it would be useful to understand how sensitive the method is to hyperparameter choices, and whether the pixel reweighting strategy generalizes well to other types of adversarial attacks beyond the standard Linf-bounded perturbations considered here.
Additionally, the paper primarily evaluates PRAT on ImageNet, which is a relatively coarse-grained classification task. It would be valuable to see how the method performs on more fine-grained or structured prediction tasks, where the importance of different input regions may be more nuanced.
Overall, this is a promising piece of work that introduces an interesting new angle on the accuracy-robustness tradeoff. Further research is needed to fully understand the strengths, limitations, and broader applicability of the Pixel Reweighted Adversarial Training approach.
Conclusion
This paper presents a novel adversarial training method called Pixel Reweighted Adversarial Training (PRAT) that aims to improve the tradeoff between accuracy and robustness in deep neural networks. The key idea is to dynamically reweight the importance of different pixels during training, focusing on the most informative regions for classification.
The authors show that PRAT can outperform standard adversarial training on benchmark tasks like ImageNet, improving both clean accuracy and robustness to adversarial attacks. This suggests that selectively attending to the most important input features can be an effective way to navigate the accuracy-robustness tradeoff in deep learning.
While further research is needed to fully understand the limitations and broader applicability of this approach, this work introduces an interesting new perspective on a fundamental challenge in adversarial machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Accuracy-robustness Trade-off via Pixel Reweighted Adversarial Training
Jiacheng Zhang, Feng Liu, Dawei Zhou, Jingfeng Zhang, Tongliang Liu
Adversarial training (AT) trains models using adversarial examples (AEs), which are natural images modified with specific perturbations to mislead the model. These perturbations are constrained by a predefined perturbation budget $epsilon$ and are equally applied to each pixel within an image. However, in this paper, we discover that not all pixels contribute equally to the accuracy on AEs (i.e., robustness) and accuracy on natural images (i.e., accuracy). Motivated by this finding, we propose Pixel-reweighted AdveRsarial Training (PART), a new framework that partially reduces $epsilon$ for less influential pixels, guiding the model to focus more on key regions that affect its outputs. Specifically, we first use class activation mapping (CAM) methods to identify important pixel regions, then we keep the perturbation budget for these regions while lowering it for the remaining regions when generating AEs. In the end, we use these pixel-reweighted AEs to train a model. PART achieves a notable improvement in accuracy without compromising robustness on CIFAR-10, SVHN and TinyImagenet-200, justifying the necessity to allocate distinct weights to different pixel regions in robust classification.
Read more6/4/2024

0
Rethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off
Futa Waseda, Ching-Chun Chang, Isao Echizen
Although adversarial training has been the state-of-the-art approach to defend against adversarial examples (AEs), it suffers from a robustness-accuracy trade-off, where high robustness is achieved at the cost of clean accuracy. In this work, we leverage invariance regularization on latent representations to learn discriminative yet adversarially invariant representations, aiming to mitigate this trade-off. We analyze two key issues in representation learning with invariance regularization: (1) a gradient conflict between invariance loss and classification objectives, leading to suboptimal convergence, and (2) the mixture distribution problem arising from diverged distributions of clean and adversarial inputs. To address these issues, we propose Asymmetrically Representation-regularized Adversarial Training (AR-AT), which incorporates asymmetric invariance loss with stop-gradient operation and a predictor to improve the convergence, and a split-BatchNorm (BN) structure to resolve the mixture distribution problem. Our method significantly improves the robustness-accuracy trade-off by learning adversarially invariant representations without sacrificing discriminative ability. Furthermore, we discuss the relevance of our findings to knowledge-distillation-based defense methods, contributing to a deeper understanding of their relative successes.
Read more5/30/2024
🏋️
0
Provable Unrestricted Adversarial Training without Compromise with Generalizability
Lilin Zhang, Ning Yang, Yanchao Sun, Philip S. Yu
Adversarial training (AT) is widely considered as the most promising strategy to defend against adversarial attacks and has drawn increasing interest from researchers. However, the existing AT methods still suffer from two challenges. First, they are unable to handle unrestricted adversarial examples (UAEs), which are built from scratch, as opposed to restricted adversarial examples (RAEs), which are created by adding perturbations bound by an $l_p$ norm to observed examples. Second, the existing AT methods often achieve adversarial robustness at the expense of standard generalizability (i.e., the accuracy on natural examples) because they make a tradeoff between them. To overcome these challenges, we propose a unique viewpoint that understands UAEs as imperceptibly perturbed unobserved examples. Also, we find that the tradeoff results from the separation of the distributions of adversarial examples and natural examples. Based on these ideas, we propose a novel AT approach called Provable Unrestricted Adversarial Training (PUAT), which can provide a target classifier with comprehensive adversarial robustness against both UAE and RAE, and simultaneously improve its standard generalizability. Particularly, PUAT utilizes partially labeled data to achieve effective UAE generation by accurately capturing the natural data distribution through a novel augmented triple-GAN. At the same time, PUAT extends the traditional AT by introducing the supervised loss of the target classifier into the adversarial loss and achieves the alignment between the UAE distribution, the natural data distribution, and the distribution learned by the classifier, with the collaboration of the augmented triple-GAN. Finally, the solid theoretical analysis and extensive experiments conducted on widely-used benchmarks demonstrate the superiority of PUAT.
Read more5/21/2024
0
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
Enes Altinisik, Safa Messaoud, Husrev Taha Sencar, Hassan Sajjad, Sanjay Chawla
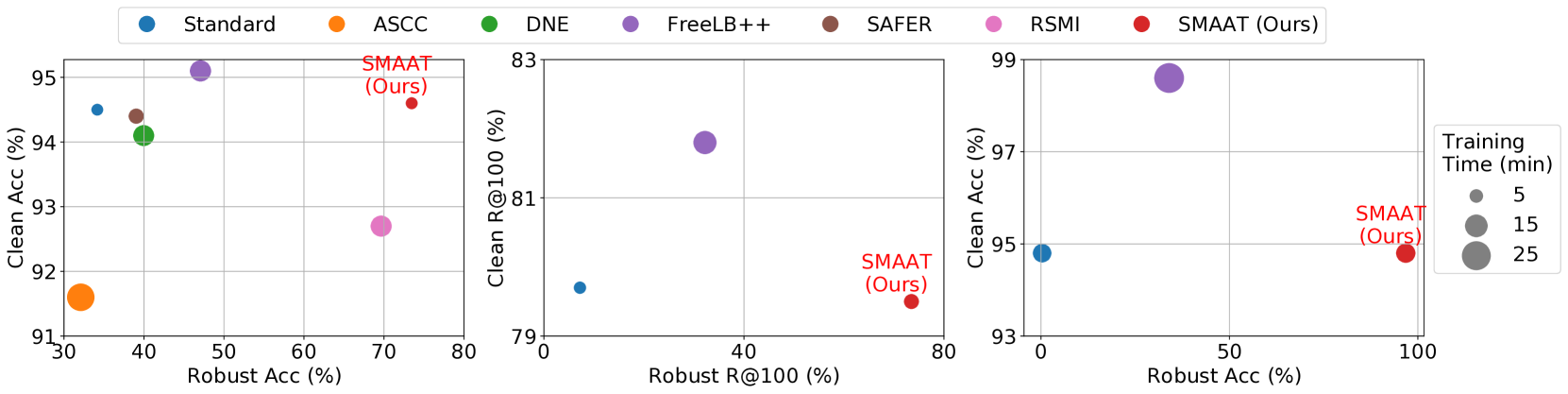
Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
Read more5/28/2024