Rethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off

0

Sign in to get full access
Overview
This paper examines the trade-off between the accuracy and robustness of deep learning models, with a focus on improving adversarial robustness without significantly compromising accuracy. The researchers propose a novel approach to invariance regularization in adversarial training, which aims to strike a better balance between these competing objectives.
Plain English Explanation
Deep learning models have become incredibly powerful at tasks like image recognition and natural language processing. However, these models can be vulnerable to "adversarial attacks" - small, carefully crafted changes to the input that can fool the model into making incorrect predictions. Improving the robustness of these models to such attacks is an important area of research.
One common approach is to use "adversarial training," where the model is trained on both normal examples and adversarial examples. This helps the model learn to be more robust. However, this can also lead to a trade-off, where the model becomes more robust but less accurate on normal, non-adversarial inputs.
The researchers in this paper propose a new way to do adversarial training that tries to strike a better balance between robustness and accuracy. The key idea is to modify how the model learns to be invariant (or "insensitive") to small changes in the input. By rethinking this aspect of the training process, the researchers show they can improve the robustness-accuracy trade-off, making the models more robust without sacrificing too much accuracy.
Technical Explanation
The paper begins by formulating the adversarial training problem and describing the standard approach of adversarial training, which aims to learn models that are robust to adversarial perturbations.
The researchers then introduce their main contribution, which is a novel invariance regularization scheme for adversarial training. This builds on prior work on spectral regularization and latent adversarial training, but with a key difference in how the invariance regularization is applied.
Specifically, the new approach leverages the layered intrinsic dimensionality of the model's representation, applying the invariance regularization in a more targeted way. This allows the model to learn a more optimal trade-off between robustness and accuracy.
The paper then presents extensive experiments on standard benchmarks, showing that the proposed method outperforms prior approaches in terms of the robustness-accuracy trade-off. Additional analyses are provided to gain insights into the workings of the method.
Critical Analysis
The paper provides a well-designed and thorough investigation of the proposed approach, with rigorous experiments and thoughtful analysis. The researchers acknowledge the inherent trade-off between robustness and accuracy, and their method represents a meaningful step towards addressing this challenge.
That said, the paper does not explore the full extent of this trade-off or the potential limitations of the approach. For example, it would be interesting to understand how the method performs on more diverse datasets or against more sophisticated adversarial attacks. Additionally, the paper does not delve into the computational complexity or training time required by the new regularization scheme, which could be an important practical consideration.
Overall, the research presented in this paper is a valuable contribution to the field of adversarial robustness and trustworthy AI. The proposed approach represents a promising step towards developing more robust and accurate deep learning models, but further investigation is needed to fully understand its capabilities and limitations.
Conclusion
This paper introduces a novel invariance regularization scheme for adversarial training that aims to improve the trade-off between the robustness and accuracy of deep learning models. By leveraging the layered intrinsic dimensionality of the model's representation, the researchers demonstrate that their approach can achieve better robustness without sacrificing too much accuracy.
The findings of this work contribute to the ongoing efforts to develop more trustworthy and reliable AI systems, which is crucial as these technologies become increasingly pervasive in our lives. While further research is needed, this paper represents a valuable step forward in the quest to build deep learning models that are both highly capable and resilient to adversarial attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Rethinking Invariance Regularization in Adversarial Training to Improve Robustness-Accuracy Trade-off
Futa Waseda, Ching-Chun Chang, Isao Echizen
Although adversarial training has been the state-of-the-art approach to defend against adversarial examples (AEs), it suffers from a robustness-accuracy trade-off, where high robustness is achieved at the cost of clean accuracy. In this work, we leverage invariance regularization on latent representations to learn discriminative yet adversarially invariant representations, aiming to mitigate this trade-off. We analyze two key issues in representation learning with invariance regularization: (1) a gradient conflict between invariance loss and classification objectives, leading to suboptimal convergence, and (2) the mixture distribution problem arising from diverged distributions of clean and adversarial inputs. To address these issues, we propose Asymmetrically Representation-regularized Adversarial Training (AR-AT), which incorporates asymmetric invariance loss with stop-gradient operation and a predictor to improve the convergence, and a split-BatchNorm (BN) structure to resolve the mixture distribution problem. Our method significantly improves the robustness-accuracy trade-off by learning adversarially invariant representations without sacrificing discriminative ability. Furthermore, we discuss the relevance of our findings to knowledge-distillation-based defense methods, contributing to a deeper understanding of their relative successes.
Read more5/30/2024

0
Regularization for Adversarial Robust Learning
Jie Wang, Rui Gao, Yao Xie
Despite the growing prevalence of artificial neural networks in real-world applications, their vulnerability to adversarial attacks remains a significant concern, which motivates us to investigate the robustness of machine learning models. While various heuristics aim to optimize the distributionally robust risk using the $infty$-Wasserstein metric, such a notion of robustness frequently encounters computation intractability. To tackle the computational challenge, we develop a novel approach to adversarial training that integrates $phi$-divergence regularization into the distributionally robust risk function. This regularization brings a notable improvement in computation compared with the original formulation. We develop stochastic gradient methods with biased oracles to solve this problem efficiently, achieving the near-optimal sample complexity. Moreover, we establish its regularization effects and demonstrate it is asymptotic equivalence to a regularized empirical risk minimization framework, by considering various scaling regimes of the regularization parameter and robustness level. These regimes yield gradient norm regularization, variance regularization, or a smoothed gradient norm regularization that interpolates between these extremes. We numerically validate our proposed method in supervised learning, reinforcement learning, and contextual learning and showcase its state-of-the-art performance against various adversarial attacks.
Read more8/23/2024
0
Improving Accuracy-robustness Trade-off via Pixel Reweighted Adversarial Training
Jiacheng Zhang, Feng Liu, Dawei Zhou, Jingfeng Zhang, Tongliang Liu
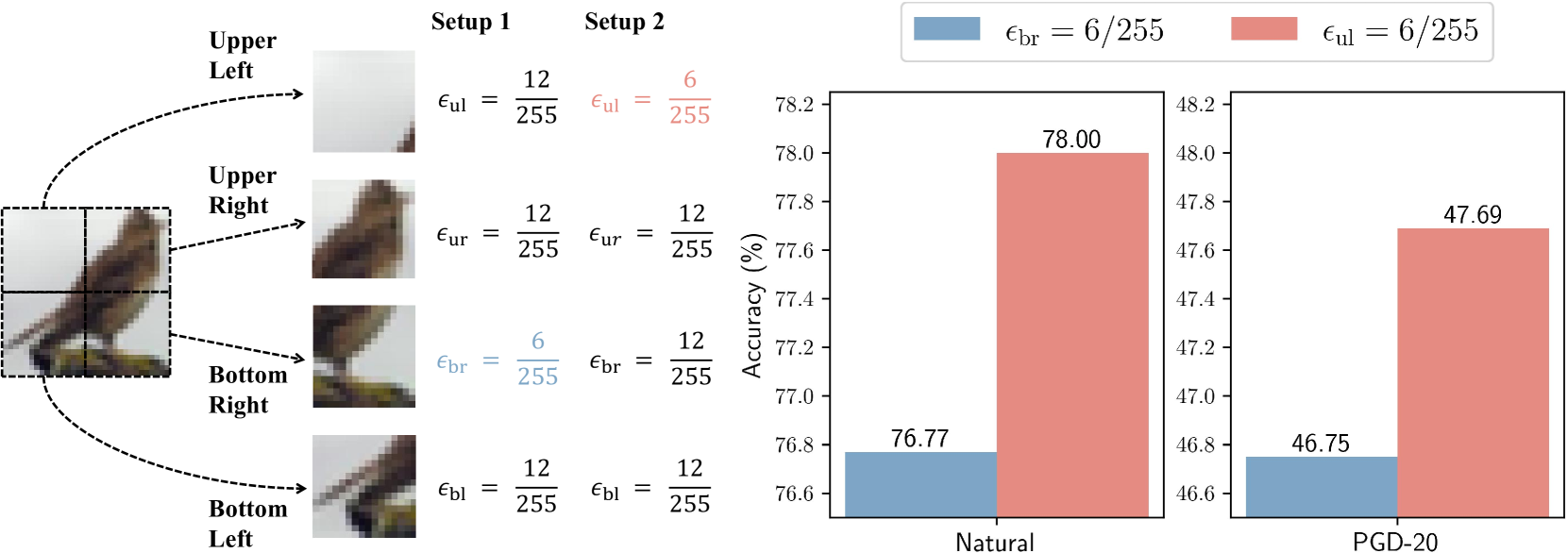
Adversarial training (AT) trains models using adversarial examples (AEs), which are natural images modified with specific perturbations to mislead the model. These perturbations are constrained by a predefined perturbation budget $epsilon$ and are equally applied to each pixel within an image. However, in this paper, we discover that not all pixels contribute equally to the accuracy on AEs (i.e., robustness) and accuracy on natural images (i.e., accuracy). Motivated by this finding, we propose Pixel-reweighted AdveRsarial Training (PART), a new framework that partially reduces $epsilon$ for less influential pixels, guiding the model to focus more on key regions that affect its outputs. Specifically, we first use class activation mapping (CAM) methods to identify important pixel regions, then we keep the perturbation budget for these regions while lowering it for the remaining regions when generating AEs. In the end, we use these pixel-reweighted AEs to train a model. PART achieves a notable improvement in accuracy without compromising robustness on CIFAR-10, SVHN and TinyImagenet-200, justifying the necessity to allocate distinct weights to different pixel regions in robust classification.
Read more6/4/2024
0
Exploiting the Layered Intrinsic Dimensionality of Deep Models for Practical Adversarial Training
Enes Altinisik, Safa Messaoud, Husrev Taha Sencar, Hassan Sajjad, Sanjay Chawla
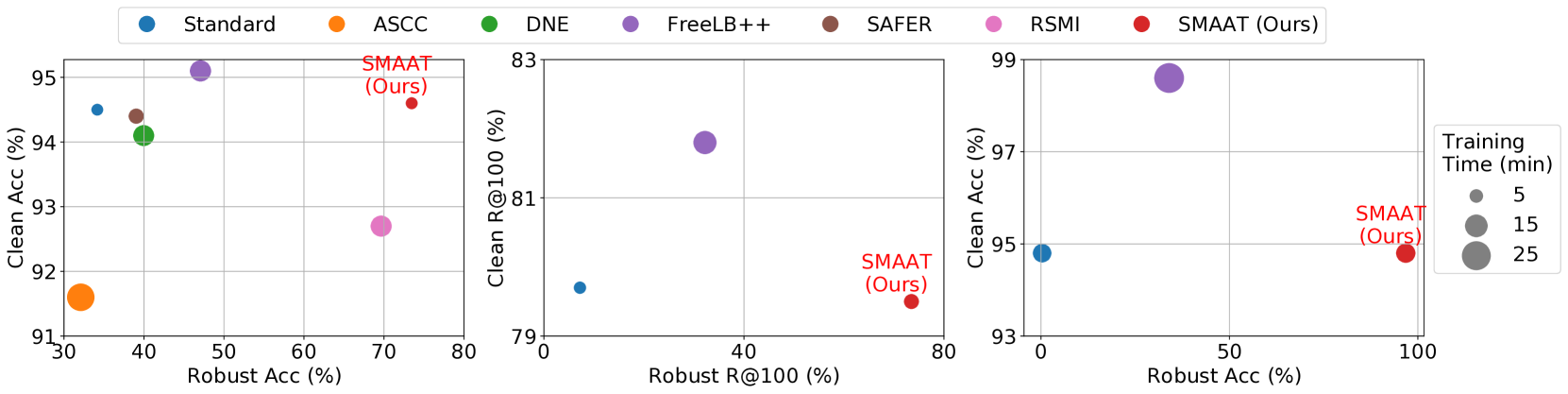
Despite being a heavily researched topic, Adversarial Training (AT) is rarely, if ever, deployed in practical AI systems for two primary reasons: (i) the gained robustness is frequently accompanied by a drop in generalization and (ii) generating adversarial examples (AEs) is computationally prohibitively expensive. To address these limitations, we propose SMAAT, a new AT algorithm that leverages the manifold conjecture, stating that off-manifold AEs lead to better robustness while on-manifold AEs result in better generalization. Specifically, SMAAT aims at generating a higher proportion of off-manifold AEs by perturbing the intermediate deepnet layer with the lowest intrinsic dimension. This systematically results in better scalability compared to classical AT as it reduces the PGD chains length required for generating the AEs. Additionally, our study provides, to the best of our knowledge, the first explanation for the difference in the generalization and robustness trends between vision and language models, ie., AT results in a drop in generalization in vision models whereas, in encoder-based language models, generalization either improves or remains unchanged. We show that vision transformers and decoder-based models tend to have low intrinsic dimensionality in the earlier layers of the network (more off-manifold AEs), while encoder-based models have low intrinsic dimensionality in the later layers. We demonstrate the efficacy of SMAAT; on several tasks, including robustifying (i) sentiment classifiers, (ii) safety filters in decoder-based models, and (iii) retrievers in RAG setups. SMAAT requires only 25-33% of the GPU time compared to standard AT, while significantly improving robustness across all applications and maintaining comparable generalization.
Read more5/28/2024