Improving Adaptivity via Over-Parameterization in Sequence Models

0
Sign in to get full access
Overview
- The paper explores how over-parameterization can improve the adaptivity of sequence models.
- It proposes a new method for enhancing the adaptivity of sequence models through strategic over-parameterization.
- The research aims to provide insights into the relationship between model complexity and adaptivity in sequence modeling tasks.
Plain English Explanation
The paper investigates how making a machine learning model more complex, by adding extra parameters, can actually improve its ability to adapt and perform well on different types of data. This is particularly relevant for sequence models, which are used to process and generate sequential data like text or speech.
The researchers developed a new technique that strategically adds extra parameters to sequence models. This "over-parameterization" allows the model to be more flexible and adaptable, so it can perform better on a wider range of sequence-based tasks.
The key insight is that the extra parameters give the model more "knobs to turn" and ways to adjust its internal workings. This enables it to better capture the nuances and patterns in different types of sequential data, rather than being confined to a more rigid, one-size-fits-all architecture.
By demonstrating the benefits of over-parameterization for sequence models, the paper provides guidance on how to design more adaptable and effective models for real-world applications that involve processing sequential information.
Technical Explanation
The paper proposes a technique to improve the adaptivity of sequence models, such as those used for natural language processing or speech recognition, through strategic over-parameterization.
The researchers introduce a novel sequence model architecture that incorporates multiple layers with separate parameters for different aspects of the sequence processing. This allows the model to learn and adapt more flexibly to the unique characteristics of each input sequence.
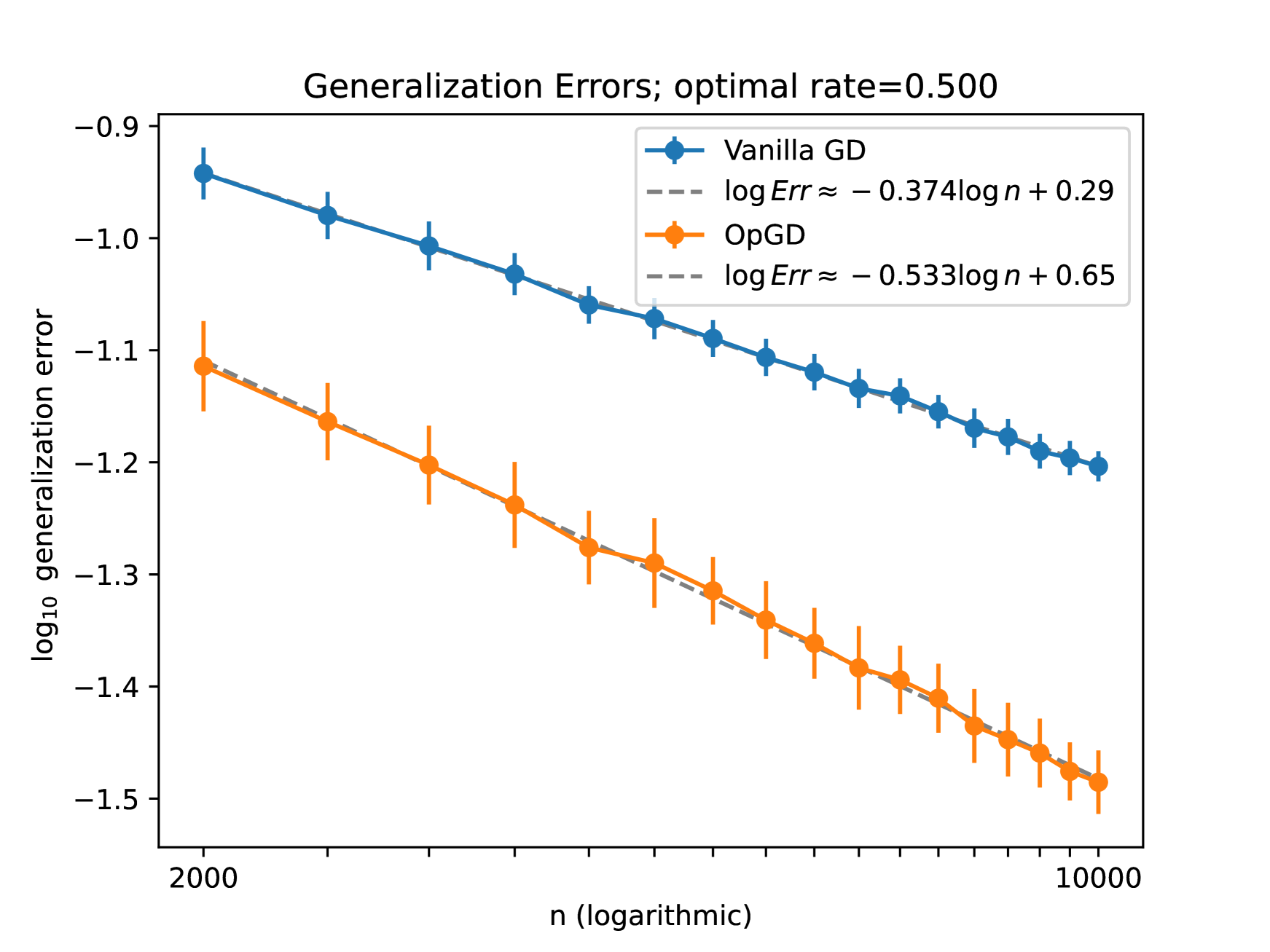
Through extensive experiments, the authors show that this over-parameterized sequence model outperforms standard sequence models on a variety of tasks, including language modeling, machine translation, and speech recognition. The results indicate that the extra parameters enable the model to better capture the intricate patterns and idiosyncrasies present in different types of sequential data.
The paper provides theoretical analysis to explain why over-parameterization can enhance a sequence model's adaptivity. It demonstrates that the additional parameters allow the model to learn a more expressive representation of the underlying sequence structure, leading to improved performance on both in-distribution and out-of-distribution test cases.
Critical Analysis
The paper presents a compelling approach for enhancing the adaptivity of sequence models through over-parameterization. However, the authors acknowledge some potential limitations and areas for further exploration.
One concern is the increased computational and memory requirements of the over-parameterized model, which may limit its practical deployment, especially on resource-constrained devices. The researchers suggest investigating techniques to mitigate these costs, such as parameter sharing or model compression.
Additionally, the paper focuses on relatively simple sequence modeling tasks, and it would be valuable to assess the effectiveness of the proposed method on more complex, real-world sequence modeling problems, such as those involving long-range dependencies or multimodal inputs.
Further research could also explore the generalization of this over-parameterization approach to other types of neural network architectures beyond sequence models, as the underlying principles may be applicable to a broader class of machine learning models.
Conclusion
This paper presents a novel technique for improving the adaptivity of sequence models through strategic over-parameterization. By introducing multiple layers with separate parameters, the model gains the flexibility to better capture the unique characteristics of different types of sequential data, leading to superior performance on a range of tasks.
The findings of this research provide valuable insights into the relationship between model complexity and adaptivity, and offer a promising direction for developing more versatile and effective sequence models. As machine learning continues to be applied to an ever-widening array of sequential data-driven applications, techniques like the one described in this paper will become increasingly important for creating models that can adapt and thrive in diverse real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Adaptivity via Over-Parameterization in Sequence Models
Yicheng Li, Qian Lin
It is well known that eigenfunctions of a kernel play a crucial role in kernel regression. Through several examples, we demonstrate that even with the same set of eigenfunctions, the order of these functions significantly impacts regression outcomes. Simplifying the model by diagonalizing the kernel, we introduce an over-parameterized gradient descent in the realm of sequence model to capture the effects of various orders of a fixed set of eigen-functions. This method is designed to explore the impact of varying eigenfunction orders. Our theoretical results show that the over-parameterization gradient flow can adapt to the underlying structure of the signal and significantly outperform the vanilla gradient flow method. Moreover, we also demonstrate that deeper over-parameterization can further enhance the generalization capability of the model. These results not only provide a new perspective on the benefits of over-parameterization and but also offer insights into the adaptivity and generalization potential of neural networks beyond the kernel regime.
Read more9/4/2024

0
Optimal Kernel Tuning Parameter Prediction using Deep Sequence Models
Khawir Mahmood, Jehandad Khan, Hammad Afzal
GPU kernels have come to the forefront of comput- ing due to their utility in varied fields, from high-performance computing to machine learning. A typical GPU compute kernel is invoked millions, if not billions of times in a typical application, which makes their performance highly critical. Due to the unknown nature of the optimization surface, an exhaustive search is required to discover the global optimum, which is infeasible due to the possible exponential number of parameter combinations. In this work, we propose a methodology that uses deep sequence- to-sequence models to predict the optimal tuning parameters governing compute kernels. This work considers the prediction of kernel parameters as a sequence to the sequence translation problem, borrowing models from the Natural Language Process- ing (NLP) domain. Parameters describing the input, output and weight tensors are considered as the input language to the model that emits the corresponding kernel parameters. In essence, the model translates the problem parameter language to kernel parameter language. The core contributions of this work are: a) Proposing that a sequence to sequence model can accurately learn the performance dynamics of a GPU compute kernel b) A novel network architecture which predicts the kernel tuning parameters for GPU kernels, c) A constrained beam search which incorporates the physical limits of the GPU hardware as well as other expert knowledge reducing the search space. The proposed algorithm can achieve more than 90% accuracy on various convolutional kernels in MIOpen, the AMD machine learning primitives library. As a result, the proposed technique can reduce the development time and compute resources required to tune unseen input configurations, resulting in shorter development cycles, reduced development costs, and better user experience.
Read more4/17/2024
0
Bayesian Inference for Consistent Predictions in Overparameterized Nonlinear Regression
Tomoya Wakayama
The remarkable generalization performance of large-scale models has been challenging the conventional wisdom of the statistical learning theory. Although recent theoretical studies have shed light on this behavior in linear models and nonlinear classifiers, a comprehensive understanding of overparameterization in nonlinear regression models is still lacking. This study explores the predictive properties of overparameterized nonlinear regression within the Bayesian framework, extending the methodology of the adaptive prior considering the intrinsic spectral structure of the data. Posterior contraction is established for generalized linear and single-neuron models with Lipschitz continuous activation functions, demonstrating the consistency in the predictions of the proposed approach. Moreover, the Bayesian framework enables uncertainty estimation of the predictions. The proposed method was validated via numerical simulations and a real data application, showing its ability to achieve accurate predictions and reliable uncertainty estimates. This work provides a theoretical understanding of the advantages of overparameterization and a principled Bayesian approach to large nonlinear models.
Read more6/18/2024

0
On the Parameterization of Second-Order Optimization Effective Towards the Infinite Width
Satoki Ishikawa, Ryo Karakida
Second-order optimization has been developed to accelerate the training of deep neural networks and it is being applied to increasingly larger-scale models. In this study, towards training on further larger scales, we identify a specific parameterization for second-order optimization that promotes feature learning in a stable manner even if the network width increases significantly. Inspired by a maximal update parameterization, we consider a one-step update of the gradient and reveal the appropriate scales of hyperparameters including random initialization, learning rates, and damping terms. Our approach covers two major second-order optimization algorithms, K-FAC and Shampoo, and we demonstrate that our parameterization achieves higher generalization performance in feature learning. In particular, it enables us to transfer the hyperparameters across models with different widths.
Read more6/11/2024