Bayesian Inference for Consistent Predictions in Overparameterized Nonlinear Regression
2404.04498
0
0
Abstract
The remarkable generalization performance of overparameterized models has challenged the conventional wisdom of statistical learning theory. While recent theoretical studies have shed light on this behavior in linear models or nonlinear classifiers, a comprehensive understanding of overparameterization in nonlinear regression remains lacking. This paper explores the predictive properties of overparameterized nonlinear regression within the Bayesian framework, extending the methodology of adaptive prior based on the intrinsic spectral structure of the data. We establish posterior contraction for single-neuron models with Lipschitz continuous activation functions and for generalized linear models, demonstrating that our approach achieves consistent predictions in the overparameterized regime. Moreover, our Bayesian framework allows for uncertainty estimation of the predictions. The proposed method is validated through numerical simulations and a real data application, showcasing its ability to achieve accurate predictions and reliable uncertainty estimates. Our work advances the theoretical understanding of the blessing of overparameterization and offers a principled Bayesian approach for prediction in large nonlinear models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a Bayesian inference approach to address the challenges of overparameterized nonlinear regression.
- The key idea is to leverage Bayesian techniques to obtain consistent predictions, even in situations where the model is highly complex and the number of parameters exceeds the number of training samples.
- The authors demonstrate the efficacy of their approach through both theoretical analysis and empirical evaluations.
Plain English Explanation
Nonlinear regression is a powerful technique used to model complex relationships between variables. However, when the model has more parameters than the available training data (known as overparameterization), traditional methods can struggle to make reliable predictions.
The authors of this paper present a Bayesian approach to address this challenge. Bayesian inference is a statistical framework that allows for the incorporation of prior knowledge and uncertainty into the modeling process. By adopting a Bayesian perspective, the researchers show how to obtain consistent predictions, even when the model is highly complex and the number of parameters exceeds the number of training samples.
The key insight is that Bayesian methods can effectively navigate the "overfitting" problem that often arises in overparameterized models. By accounting for the inherent uncertainty in the model parameters, the Bayesian approach is able to make robust predictions that are less sensitive to the specifics of the training data.
Technical Explanation
The paper begins by outlining the problem of overparameterized nonlinear regression, where the number of model parameters exceeds the available training data. This can lead to issues with overfitting and inconsistent predictions. To address this, the authors propose a Bayesian inference framework that explicitly models the uncertainty in the model parameters.
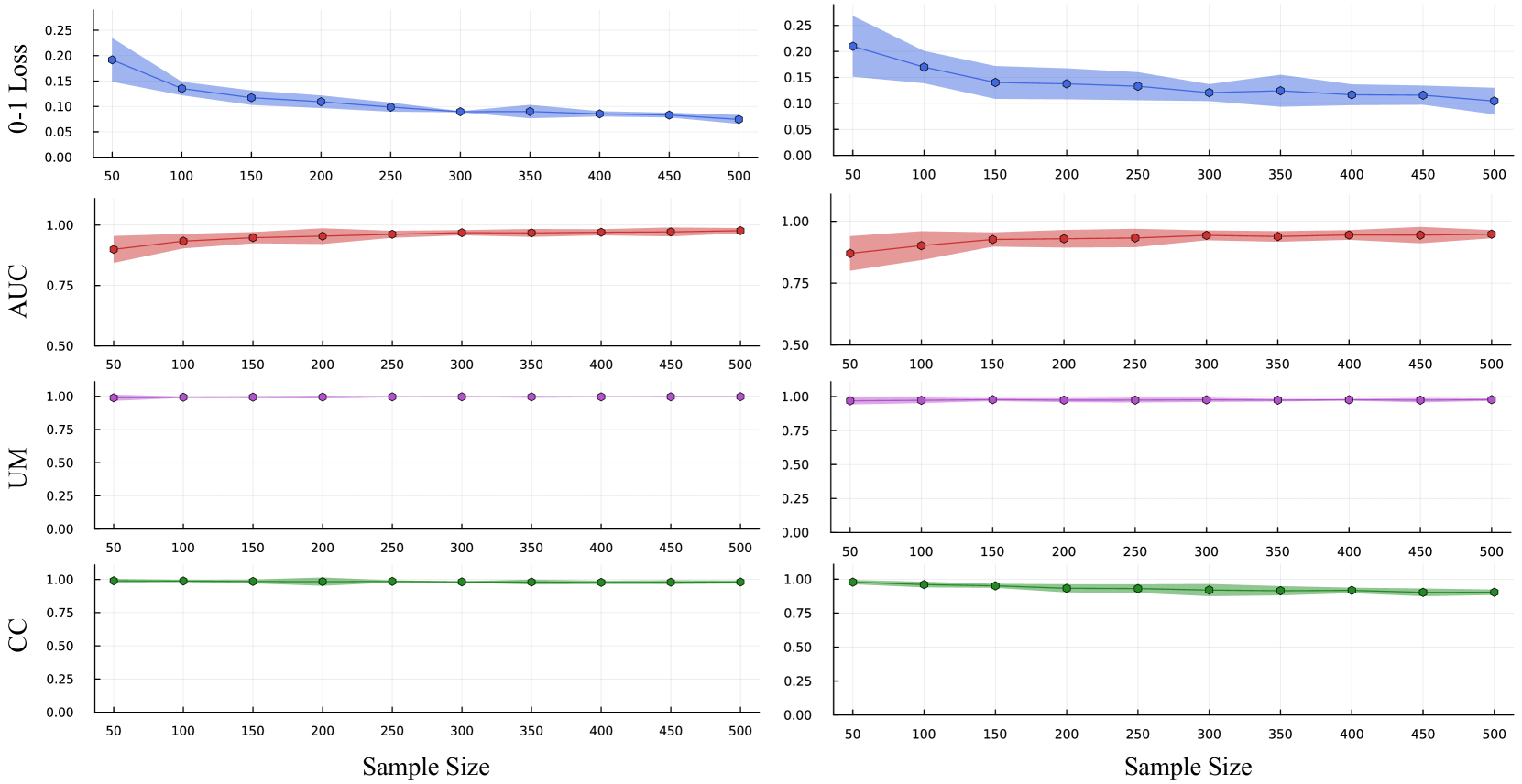
Theoretically, the authors provide a detailed analysis of the properties of their Bayesian approach. They demonstrate that, under certain assumptions, the Bayesian posterior distribution converges to a consistent estimator of the true underlying function, even in the overparameterized setting. This theoretical result establishes the consistency and robustness of the Bayesian approach.
To validate their approach, the authors conduct extensive empirical evaluations on both synthetic and real-world datasets. They compare the performance of their Bayesian method to traditional regularization techniques, such as Restricted Bayesian Neural Networks and Generalization through Adaptivity. The results show that the Bayesian approach outperforms these alternatives, particularly in terms of consistent and reliable predictions.
Critical Analysis
The paper provides a well-grounded theoretical analysis and convincing empirical evidence for the effectiveness of the proposed Bayesian inference approach. However, the authors do acknowledge certain limitations and areas for further research.
One potential limitation is the reliance on specific assumptions, such as the existence of a true underlying function and the availability of sufficient training data. In real-world scenarios, these assumptions may not always hold, and it would be valuable to explore the robustness of the Bayesian approach in more challenging settings, such as those involving inhomogeneous data or complex data structures.
Additionally, the authors mention that the computational complexity of the Bayesian inference process may be a practical concern, especially for large-scale problems. Investigating more efficient Bayesian methods, such as Bayesian Additive Regression Networks or PAC-Bayesian approaches, could help expand the applicability of the proposed framework.
Conclusion
This paper presents a compelling Bayesian approach to address the challenge of overparameterized nonlinear regression. By explicitly modeling parameter uncertainty, the authors demonstrate how Bayesian inference can lead to consistent and reliable predictions, even when the model complexity exceeds the available training data.
The theoretical analysis and empirical results showcase the potential of this Bayesian framework to advance the field of nonlinear regression and support decision-making in a wide range of applications. While the authors highlight some limitations, the overall contributions of this work represent a significant step forward in addressing the critical problem of overparameterization in complex modeling tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Overparameterized Multiple Linear Regression as Hyper-Curve Fitting
E. Atza, N. Budko
0
0
The paper shows that the application of the fixed-effect multiple linear regression model to an overparameterized dataset is equivalent to fitting the data with a hyper-curve parameterized by a single scalar parameter. This equivalence allows for a predictor-focused approach, where each predictor is described by a function of the chosen parameter. It is proven that a linear model will produce exact predictions even in the presence of nonlinear dependencies that violate the model assumptions. Parameterization in terms of the dependent variable and the monomial basis in the predictor function space are applied here to both synthetic and experimental data. The hyper-curve approach is especially suited for the regularization of problems with noise in predictor variables and can be used to remove noisy and improper predictors from the model.
4/12/2024
🤯
Scalable Bayesian Inference in the Era of Deep Learning: From Gaussian Processes to Deep Neural Networks
Javier Antoran
0
0
Large neural networks trained on large datasets have become the dominant paradigm in machine learning. These systems rely on maximum likelihood point estimates of their parameters, precluding them from expressing model uncertainty. This may result in overconfident predictions and it prevents the use of deep learning models for sequential decision making. This thesis develops scalable methods to equip neural networks with model uncertainty. In particular, we leverage the linearised Laplace approximation to equip pre-trained neural networks with the uncertainty estimates provided by their tangent linear models. This turns the problem of Bayesian inference in neural networks into one of Bayesian inference in conjugate Gaussian-linear models. Alas, the cost of this remains cubic in either the number of network parameters or in the number of observations times output dimensions. By assumption, neither are tractable. We address this intractability by using stochastic gradient descent (SGD) -- the workhorse algorithm of deep learning -- to perform posterior sampling in linear models and their convex duals: Gaussian processes. With this, we turn back to linearised neural networks, finding the linearised Laplace approximation to present a number of incompatibilities with modern deep learning practices -- namely, stochastic optimisation, early stopping and normalisation layers -- when used for hyperparameter learning. We resolve these and construct a sample-based EM algorithm for scalable hyperparameter learning with linearised neural networks. We apply the above methods to perform linearised neural network inference with ResNet-50 (25M parameters) trained on Imagenet (1.2M observations and 1000 output dimensions). Additionally, we apply our methods to estimate uncertainty for 3d tomographic reconstructions obtained with the deep image prior network.
5/1/2024
🔮
Online Calibrated and Conformal Prediction Improves Bayesian Optimization
Shachi Deshpande, Charles Marx, Volodymyr Kuleshov
0
0
Accurate uncertainty estimates are important in sequential model-based decision-making tasks such as Bayesian optimization. However, these estimates can be imperfect if the data violates assumptions made by the model (e.g., Gaussianity). This paper studies which uncertainties are needed in model-based decision-making and in Bayesian optimization, and argues that uncertainties can benefit from calibration -- i.e., an 80% predictive interval should contain the true outcome 80% of the time. Maintaining calibration, however, can be challenging when the data is non-stationary and depends on our actions. We propose using simple algorithms based on online learning to provably maintain calibration on non-i.i.d. data, and we show how to integrate these algorithms in Bayesian optimization with minimal overhead. Empirically, we find that calibrated Bayesian optimization converges to better optima in fewer steps, and we demonstrate improved performance on standard benchmark functions and hyperparameter optimization tasks.
4/23/2024
Misspecification uncertainties in near-deterministic regression
Thomas D Swinburne, Danny Perez
0
0
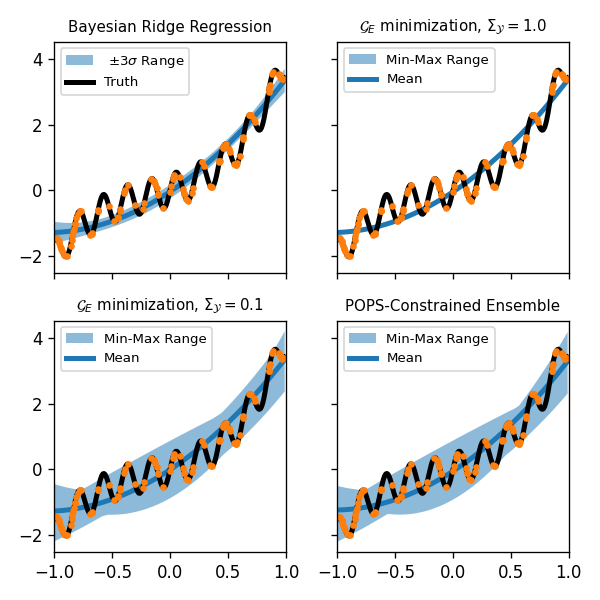
Bayesian regression determines model parameters by minimizing the expected loss, an upper bound to the true generalization error. However, the loss ignores misspecification, where models are imperfect. Parameter uncertainties from Bayesian regression are thus significantly underestimated and vanish in the large data limit. This is particularly problematic when building models of low- noise, or near-deterministic, calculations, as the main source of uncertainty is neglected. We analyze the generalization error of misspecified, near-deterministic surrogate models, a regime of broad relevance in science and engineering. We show posterior distributions must cover every training point to avoid a divergent generalization error and design an ansatz that respects this constraint, which for linear models incurs minimal overhead. This is demonstrated on model problems before application to thousand dimensional datasets in atomistic machine learning. Our efficient misspecification-aware scheme gives accurate prediction and bounding of test errors where existing schemes fail, allowing this important source of uncertainty to be incorporated in computational workflows.
5/8/2024