Optimal Kernel Tuning Parameter Prediction using Deep Sequence Models

0

Sign in to get full access
Overview
- This paper presents a novel approach to predicting optimal kernel tuning parameters using deep sequence models.
- The researchers developed a deep learning model that can accurately predict the optimal kernel tuning parameters for GPU compute kernels, which are critical for achieving high performance in neural machine translation and other deep learning applications.
- The model leverages sequence-to-sequence and attention-based architectures to capture the complex relationships between input features and optimal tuning parameters.
Plain English Explanation
The paper describes a new way to predict the best settings for certain computer programs, called "kernel tuning parameters," that are essential for getting high performance out of graphics processing units (GPUs). These settings are very important for applications like machine translation that use deep learning techniques.
The researchers developed a deep learning model that can automatically figure out the best settings for these kernel tuning parameters. The model looks at the characteristics of the input data and uses an attention-based approach to predict the optimal parameter values. This allows the model to capture the complex relationships between the input features and the ideal tuning parameter settings.
Technical Explanation
The key technical contributions of this paper are:
-
Sequence-to-Sequence Model: The researchers developed a sequence-to-sequence model that takes a set of input features (e.g., GPU hardware specifications, workload characteristics) and predicts the optimal kernel tuning parameter values as an output sequence.
-
Attention Mechanism: To better capture the complex relationships between inputs and outputs, the model incorporates an attention mechanism that allows the model to dynamically focus on the most relevant input features when predicting each output parameter.
-
Experimental Evaluation: The researchers evaluated their model on a large dataset of GPU kernel performance profiles and demonstrated that it can significantly outperform traditional parameter tuning approaches in terms of prediction accuracy and computational efficiency.
Critical Analysis
The paper presents a well-designed and evaluated approach to the important problem of predicting optimal kernel tuning parameters. However, a few potential limitations and areas for further research are worth considering:
-
Generalization to New Hardware: The current model is trained on data from specific GPU hardware, and it's unclear how well it would generalize to new, unseen GPU architectures. Further research could explore techniques to improve the model's ability to adapt to changing hardware landscapes.
-
Interpretability: While the attention mechanism provides some insights into the model's decision-making process, the overall system remains a "black box" to some extent. Developing more interpretable models could help users better understand the factors influencing the parameter predictions.
-
Online Adaptation: The current approach assumes a static set of input features and does not account for potential changes in workload characteristics over time. Incorporating online learning or adaptation mechanisms could enhance the model's ability to continuously refine its predictions in response to evolving system dynamics.
Conclusion
This paper presents a novel deep learning-based approach for predicting optimal kernel tuning parameters, which are crucial for achieving high performance in GPU-accelerated applications like neural machine translation and deep learning workloads. The researchers developed a sequence-to-sequence model with an attention mechanism that can effectively capture the complex relationships between input features and optimal tuning parameters. The demonstrated performance improvements over traditional tuning methods highlight the potential of this approach to streamline the deployment and optimization of GPU-powered deep learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimal Kernel Tuning Parameter Prediction using Deep Sequence Models
Khawir Mahmood, Jehandad Khan, Hammad Afzal
GPU kernels have come to the forefront of comput- ing due to their utility in varied fields, from high-performance computing to machine learning. A typical GPU compute kernel is invoked millions, if not billions of times in a typical application, which makes their performance highly critical. Due to the unknown nature of the optimization surface, an exhaustive search is required to discover the global optimum, which is infeasible due to the possible exponential number of parameter combinations. In this work, we propose a methodology that uses deep sequence- to-sequence models to predict the optimal tuning parameters governing compute kernels. This work considers the prediction of kernel parameters as a sequence to the sequence translation problem, borrowing models from the Natural Language Process- ing (NLP) domain. Parameters describing the input, output and weight tensors are considered as the input language to the model that emits the corresponding kernel parameters. In essence, the model translates the problem parameter language to kernel parameter language. The core contributions of this work are: a) Proposing that a sequence to sequence model can accurately learn the performance dynamics of a GPU compute kernel b) A novel network architecture which predicts the kernel tuning parameters for GPU kernels, c) A constrained beam search which incorporates the physical limits of the GPU hardware as well as other expert knowledge reducing the search space. The proposed algorithm can achieve more than 90% accuracy on various convolutional kernels in MIOpen, the AMD machine learning primitives library. As a result, the proposed technique can reduce the development time and compute resources required to tune unseen input configurations, resulting in shorter development cycles, reduced development costs, and better user experience.
Read more4/17/2024
0
Improving Adaptivity via Over-Parameterization in Sequence Models
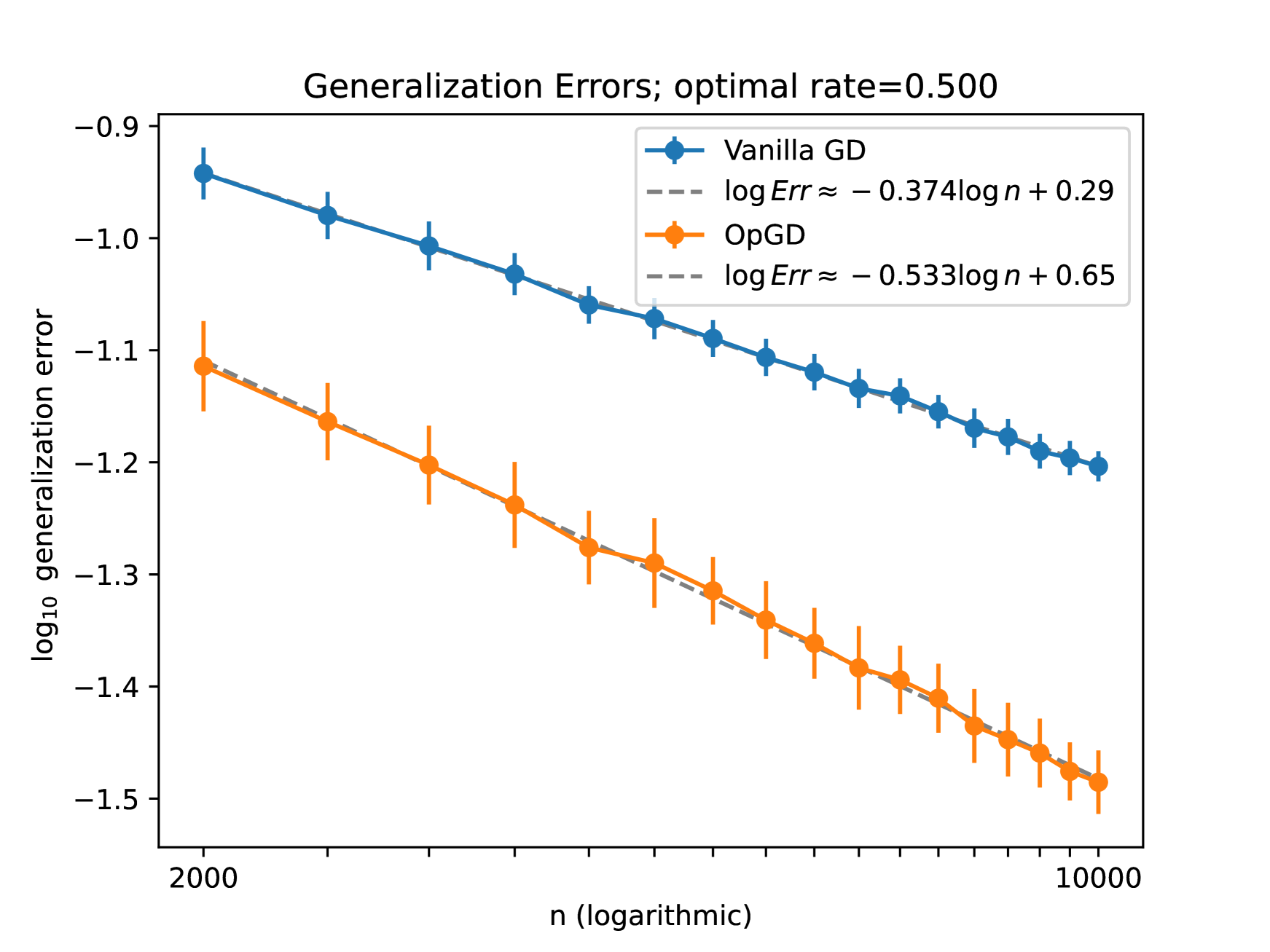
Yicheng Li, Qian Lin
It is well known that eigenfunctions of a kernel play a crucial role in kernel regression. Through several examples, we demonstrate that even with the same set of eigenfunctions, the order of these functions significantly impacts regression outcomes. Simplifying the model by diagonalizing the kernel, we introduce an over-parameterized gradient descent in the realm of sequence model to capture the effects of various orders of a fixed set of eigen-functions. This method is designed to explore the impact of varying eigenfunction orders. Our theoretical results show that the over-parameterization gradient flow can adapt to the underlying structure of the signal and significantly outperform the vanilla gradient flow method. Moreover, we also demonstrate that deeper over-parameterization can further enhance the generalization capability of the model. These results not only provide a new perspective on the benefits of over-parameterization and but also offer insights into the adaptivity and generalization potential of neural networks beyond the kernel regime.
Read more9/4/2024

0
Explore as a Storm, Exploit as a Raindrop: On the Benefit of Fine-Tuning Kernel Schedulers with Coordinate Descent
Michael Canesche, Gaurav Verma, Fernando Magno Quintao Pereira
Machine-learning models consist of kernels, which are algorithms applying operations on tensors -- data indexed by a linear combination of natural numbers. Examples of kernels include convolutions, transpositions, and vectorial products. There are many ways to implement a kernel. These implementations form the kernel's optimization space. Kernel scheduling is the problem of finding the best implementation, given an objective function -- typically execution speed. Kernel optimizers such as Ansor, Halide, and AutoTVM solve this problem via search heuristics, which combine two phases: exploration and exploitation. The first step evaluates many different kernel optimization spaces. The latter tries to improve the best implementations by investigating a kernel within the same space. For example, Ansor combines kernel generation through sketches for exploration and leverages an evolutionary algorithm to exploit the best sketches. In this work, we demonstrate the potential to reduce Ansor's search time while enhancing kernel quality by incorporating Droplet Search, an AutoTVM algorithm, into Ansor's exploration phase. The approach involves limiting the number of samples explored by Ansor, selecting the best, and exploiting it with a coordinate descent algorithm. By applying this approach to the first 300 kernels that Ansor generates, we usually obtain better kernels in less time than if we let Ansor analyze 10,000 kernels. This result has been replicated in 20 well-known deep-learning models (AlexNet, ResNet, VGG, DenseNet, etc.) running on four architectures: an AMD Ryzen 7 (x86), an NVIDIA A100 tensor core, an NVIDIA RTX 3080 GPU, and an ARM A64FX. A patch with this combined approach was approved in Ansor in February 2024. As evidence of the generality of this search methodology, a similar patch, achieving equally good results, was submitted to TVM's MetaSchedule in June 2024.
Read more7/16/2024
0
Data-driven Forecasting of Deep Learning Performance on GPUs
Seonho Lee, Amar Phanishayee, Divya Mahajan
Deep learning kernels exhibit predictable memory accesses and compute patterns, making GPUs' parallel architecture well-suited for their execution. Software and runtime systems for GPUs are optimized to better utilize the stream multiprocessors, on-chip cache, and off-chip high-bandwidth memory. As deep learning models and GPUs evolve, access to newer GPUs is often limited, raising questions about the performance of new model architectures on existing GPUs, existing models on new GPUs, and new model architectures on new GPUs. To address these questions, we introduce NeuSight, a framework to predict the performance of various deep learning models, for both training and inference, on unseen GPUs without requiring actual execution. The framework leverages both GPU hardware behavior and software library optimizations to estimate end-to-end performance. Previous work uses regression models that capture linear trends or multilayer perceptrons to predict the overall latency of deep learning kernels on GPUs. These approaches suffer from higher error percentages when forecasting performance on unseen models and new GPUs. Instead, NeuSight decomposes the prediction problem into smaller problems, bounding the prediction through fundamental performance laws. NeuSight decomposes a single deep learning kernel prediction into smaller working sets called tiles, which are executed independently on the GPU. Tile-granularity predictions are determined using a machine learning approach and aggregated to estimate end-to-end latency. NeuSight outperforms prior work across various deep learning workloads and the latest GPUs. It reduces the percentage error from 198% and 19.7% to 3.8% in predicting the latency of GPT3 model for training and inference on H100, compared to state-of-the-art prior works, where both GPT3 and H100 were not used to train the framework.
Read more7/22/2024