Improving Agent Behaviors with RL Fine-tuning for Autonomous Driving

0
📶
Sign in to get full access
Overview
- Modeling agent behaviors is a critical challenge in autonomous vehicle research, with applications in realistic simulations and traffic forecasting.
- Supervised learning models can suffer from distribution shift when deployed, reducing their reliability.
- This work uses reinforcement learning to fine-tune behavior models, improving overall performance and targeted metrics like collision rate.
- A novel policy evaluation benchmark is introduced to assess the quality of autonomous vehicle planners using simulated agents.
Plain English Explanation
Self-driving cars need to understand how other vehicles and road users (agents) will behave in order to drive safely and effectively. Modeling agent behaviors is a key challenge in autonomous vehicle research.
Researchers have used supervised learning to train models that can predict agent behaviors. However, these models can struggle when deployed in the real world, as the conditions may differ from the data they were trained on.
This paper presents a new approach that uses reinforcement learning to fine-tune the behavior models. The researchers found this led to improved overall performance, as well as better results on specific metrics like reducing the rate of collisions.
Additionally, the team developed a new way to evaluate the quality of autonomous vehicle planners using these simulated agents. This provides a way to directly assess how well a self-driving car's planning system will work in the real world.
Technical Explanation
The researchers aimed to improve the reliability of agent behavior models used in autonomous vehicle research. They approached this by using reinforcement learning to fine-tune supervised learning models, which can suffer from distribution shift when deployed.
The team fine-tuned behavior models using a reinforcement learning process that optimized for improved overall performance as well as targeted metrics like collision rate. This closed-loop fine-tuning approach demonstrated significant benefits compared to the original supervised learning models.
Additionally, the researchers introduced a novel policy evaluation benchmark that uses these simulated agents to directly assess the quality of autonomous vehicle planners. This provides a valuable new tool for evaluating self-driving car systems.
Critical Analysis
The paper presents a compelling approach to improving the reliability of agent behavior models through reinforcement learning. However, the authors acknowledge that further research is needed to understand the generalization capabilities of their fine-tuned models.
Additionally, the novel policy evaluation benchmark is a promising development, but its effectiveness will depend on how well the simulated agents capture the complexity of real-world driving scenarios. Ongoing validation and refinement of this benchmark will be important.
Overall, this work makes valuable contributions to the challenge of modeling agent behaviors for autonomous vehicle research. The reinforcement learning approach and new evaluation tool represent meaningful steps forward, while also highlighting the need for continued advancements in this critical area.
Conclusion
This research tackles the key challenge of modeling agent behaviors for autonomous vehicles. By using reinforcement learning to fine-tune supervised learning models, the team was able to improve the overall reliability and performance of their behavior predictions.
The introduction of a novel policy evaluation benchmark also provides a new way to directly assess the quality of autonomous vehicle planning systems using these simulated agents. This represents an important step forward in evaluating self-driving car technologies.
While further research is needed, this work demonstrates the potential of reinforcement learning to enhance agent behavior modeling and evaluations - critical components for realizing the promise of autonomous vehicles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Improving Agent Behaviors with RL Fine-tuning for Autonomous Driving
Zhenghao Peng, Wenjie Luo, Yiren Lu, Tianyi Shen, Cole Gulino, Ari Seff, Justin Fu
A major challenge in autonomous vehicle research is modeling agent behaviors, which has critical applications including constructing realistic and reliable simulations for off-board evaluation and forecasting traffic agents motion for onboard planning. While supervised learning has shown success in modeling agents across various domains, these models can suffer from distribution shift when deployed at test-time. In this work, we improve the reliability of agent behaviors by closed-loop fine-tuning of behavior models with reinforcement learning. Our method demonstrates improved overall performance, as well as improved targeted metrics such as collision rate, on the Waymo Open Sim Agents challenge. Additionally, we present a novel policy evaluation benchmark to directly assess the ability of simulated agents to measure the quality of autonomous vehicle planners and demonstrate the effectiveness of our approach on this new benchmark.
Read more9/30/2024

0
Act Better by Timing: A timing-Aware Reinforcement Learning for Autonomous Driving
Guanzhou Li, Jianping Wu, Yujing He
Coping with intensively interactive scenarios is one of the significant challenges in the development of autonomous driving. Reinforcement learning (RL) offers an ideal solution for such scenarios through its self-evolution mechanism via interaction with the environment. However, the lack of sufficient safety mechanisms in common RL leads to the fact that agent often find it difficult to interact well in highly dynamic environment and may collide in pursuit of short-term rewards. Much of the existing safe RL methods require environment modeling to generate reliable safety boundaries that constrain agent behavior. Nevertheless, acquiring such safety boundaries is not always feasible in dynamic environments. Inspired by the driver's behavior of acting when uncertainty is minimal, this study introduces the concept of action timing to replace explicit safety boundary modeling. We define actor as an agent to decide optimal action at each step. By imaging the actor take opportunity to act as a timing-dependent gradual process, the other agent called timing taker can evaluate the optimal action execution time, and relate the optimal timing to each action moment as a dynamic safety factor to constrain the actor's action. In the experiment involving a complex, unsignaled intersection interaction, this framework achieved superior safety performance compared to all benchmark models.
Read more6/21/2024

0
Multi-Agent Reinforcement Learning for Autonomous Driving: A Survey
Ruiqi Zhang, Jing Hou, Florian Walter, Shangding Gu, Jiayi Guan, Florian Rohrbein, Yali Du, Panpan Cai, Guang Chen, Alois Knoll
Reinforcement Learning (RL) is a potent tool for sequential decision-making and has achieved performance surpassing human capabilities across many challenging real-world tasks. As the extension of RL in the multi-agent system domain, multi-agent RL (MARL) not only need to learn the control policy but also requires consideration regarding interactions with all other agents in the environment, mutual influences among different system components, and the distribution of computational resources. This augments the complexity of algorithmic design and poses higher requirements on computational resources. Simultaneously, simulators are crucial to obtain realistic data, which is the fundamentals of RL. In this paper, we first propose a series of metrics of simulators and summarize the features of existing benchmarks. Second, to ease comprehension, we recall the foundational knowledge and then synthesize the recently advanced studies of MARL-related autonomous driving and intelligent transportation systems. Specifically, we examine their environmental modeling, state representation, perception units, and algorithm design. Conclusively, we discuss open challenges as well as prospects and opportunities. We hope this paper can help the researchers integrate MARL technologies and trigger more insightful ideas toward the intelligent and autonomous driving.
Read more8/20/2024
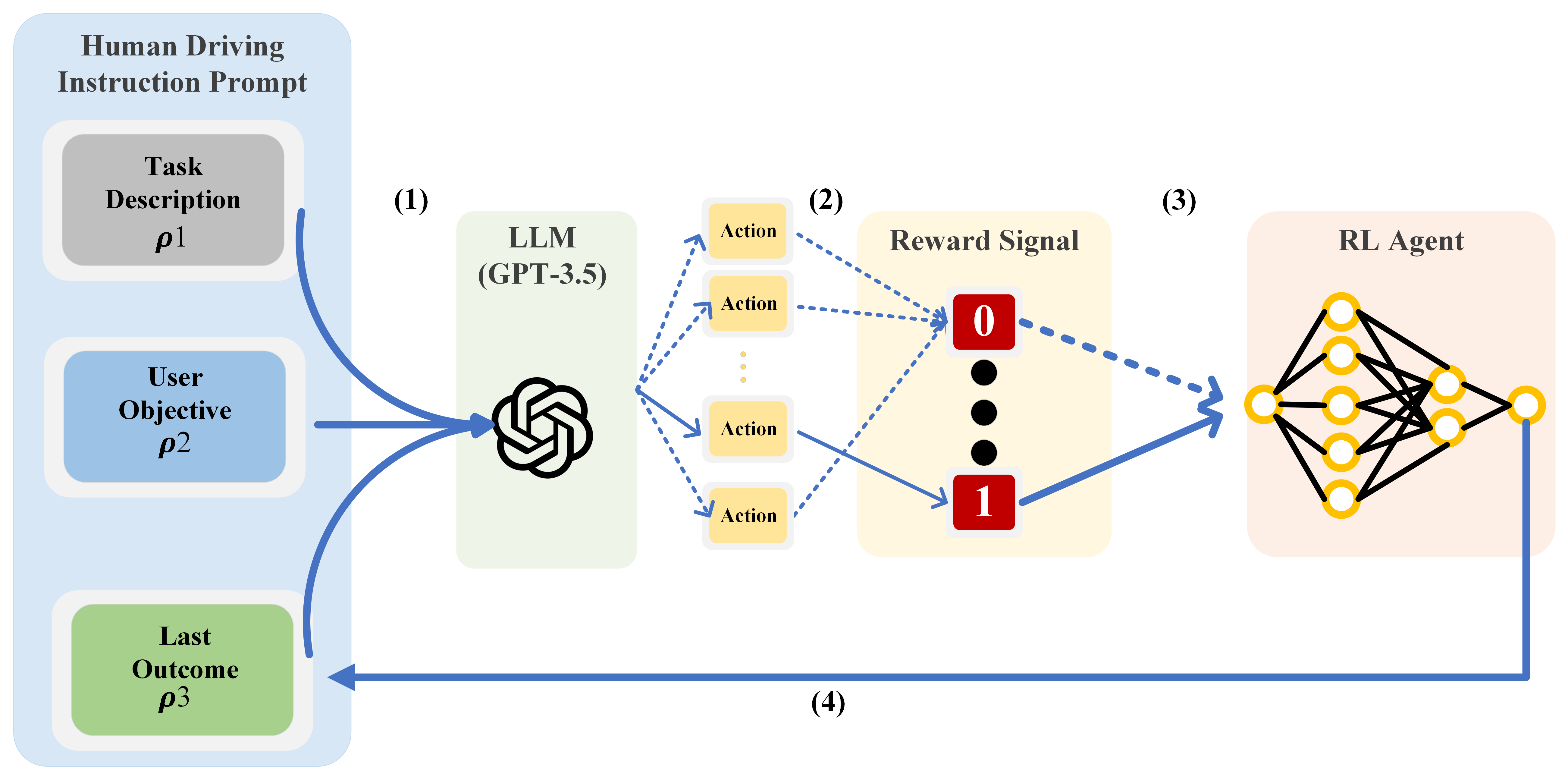
0
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
Read more5/8/2024