Optimizing Autonomous Driving for Safety: A Human-Centric Approach with LLM-Enhanced RLHF

0

Sign in to get full access
Overview
- This paper presents a novel approach to optimizing autonomous driving for safety using a human-centric Reinforcement Learning from Human Feedback (RLHF) method enhanced by Large Language Models (LLMs).
- The key ideas include using LLMs to better capture human preferences and safety considerations, and an RLHF framework to train autonomous driving agents to behave in alignment with these preferences.
- The authors demonstrate the effectiveness of their approach through simulation experiments, showing improved safety and human-like driving behavior compared to baseline methods.
Plain English Explanation
The paper discusses a new way to make self-driving cars safer and more aligned with human preferences. Traditional approaches to training self-driving AI systems often focus solely on technical performance metrics like speed and efficiency. However, the authors argue that it's also crucial to consider how the car's behavior aligns with human values and expectations around safety.
To address this, the researchers use a technique called Reinforcement Learning from Human Feedback (RLHF) to train the self-driving AI. This allows the system to learn from examples of good and bad driving behavior provided by humans, rather than just being optimized for narrow technical objectives.
The novel twist in this paper is using large language models (LLMs) to help the RLHF system better understand human preferences and safety considerations. LLMs are powerful AI models that can process and generate human-like text, and the authors leverage this capability to more accurately capture the nuances of what people consider "safe" driving.
Through simulation experiments, the researchers show that their LLM-enhanced RLHF approach produces self-driving agents that not only perform well on technical metrics, but also exhibit more human-like, cautious, and safety-conscious behavior compared to other methods. This is an important step towards developing self-driving cars that people can trust and feel comfortable using.
Technical Explanation
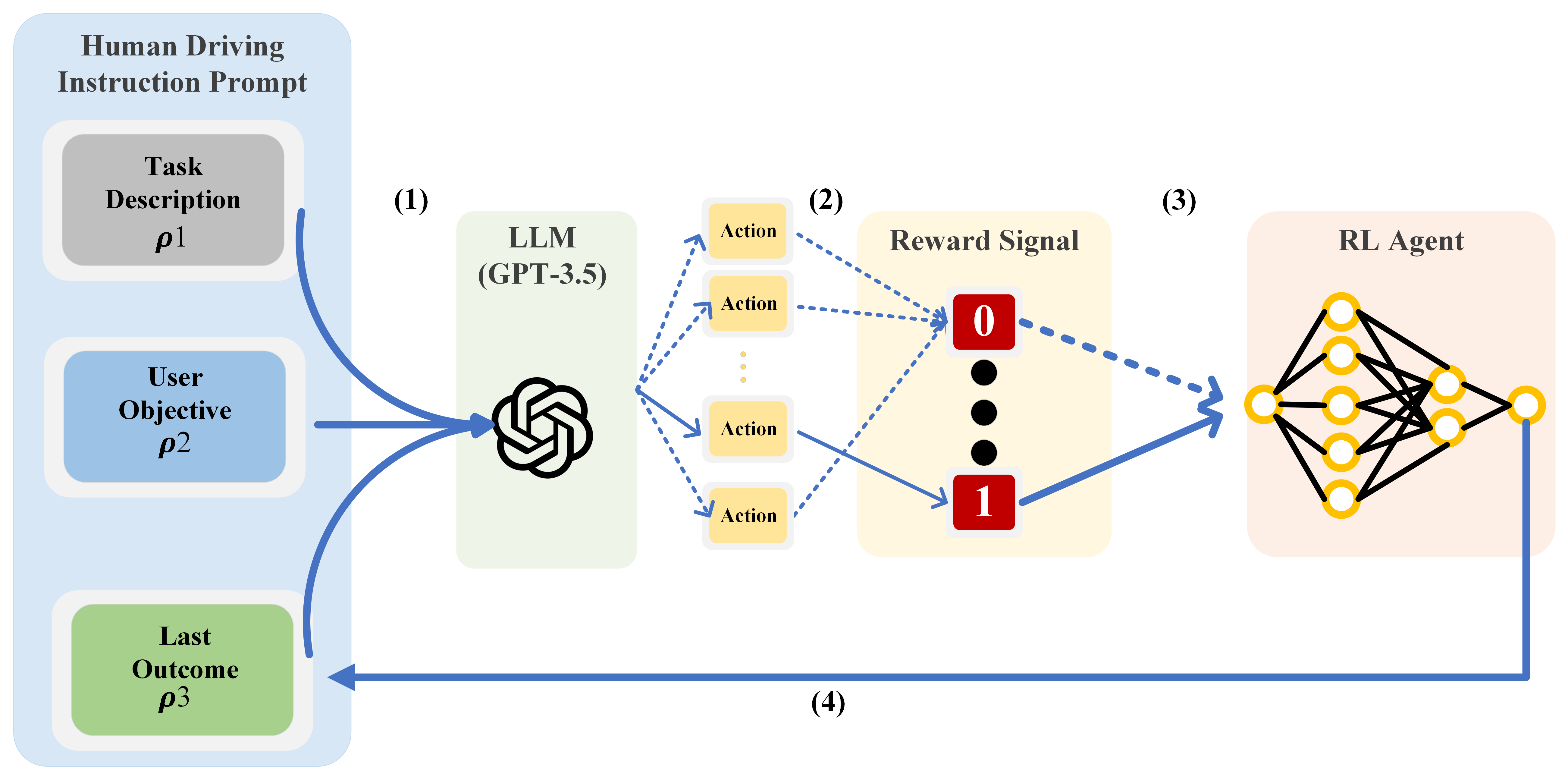
The paper introduces a novel approach to training autonomous driving agents that combines Reinforcement Learning from Human Feedback (RLHF) with the use of Large Language Models (LLMs) to better capture human preferences and safety considerations.
The authors first design a simulation environment for autonomous driving scenarios, drawing inspiration from the Context Learning for Automated Driving Scenarios work. This environment provides a testbed for evaluating the proposed approach.
Next, the researchers leverage LLMs, such as the HighwayLLM model, to enhance the RLHF framework. The LLMs are used to better understand and incorporate human preferences and safety considerations into the reward function used for training the autonomous driving agents.
The training process follows a multi-turn Reinforcement Learning from Preference approach, where the agents receive feedback from humans on their driving behavior and iteratively improve their performance.
Through extensive simulation experiments, the authors demonstrate that their LLM-enhanced RLHF approach produces autonomous driving agents that exhibit more human-like, cautious, and safety-conscious behavior compared to baseline methods. The agents are able to navigate complex scenarios while prioritizing safety and alignment with human values.
Critical Analysis
The paper presents a promising approach to optimizing autonomous driving for safety, but it is important to acknowledge some potential limitations and areas for further research.
One key consideration is the reliance on simulation environments, which may not fully capture the complexity and unpredictability of real-world driving scenarios. While the simulation experiments provide valuable insights, further validation and testing in real-world settings would be necessary to assess the practical applicability and generalizability of the proposed method.
Additionally, the authors acknowledge the challenge of accurately capturing and quantifying human preferences and safety considerations. While the use of LLMs aims to address this, there may be inherent biases or limitations in the language models that could affect the reliability of the inferred human preferences.
Another potential issue is the scalability of the RLHF training process, which can be computationally intensive and time-consuming. Exploring ways to improve the efficiency and scalability of the training approach would be an important area for future research.
Finally, the paper does not delve into the potential ethical implications of deploying autonomous driving systems optimized for human-centric safety. Careful consideration of the societal impact, fairness, and accountability of such systems would be crucial before real-world deployment.
Conclusion
This paper presents a novel approach to optimizing autonomous driving for safety using a human-centric RLHF method enhanced by LLMs. The key contribution is the integration of LLMs to better capture human preferences and safety considerations, which is then used to train autonomous driving agents through an RLHF framework.
The simulation experiments demonstrate the effectiveness of this approach, showing that the trained agents exhibit more human-like, cautious, and safety-conscious behavior compared to baseline methods. This is an important step towards developing self-driving cars that can reliably and safely navigate complex environments while aligning with human values.
However, the paper also highlights the need for further research to address the limitations of simulation-based testing, the challenges of accurately quantifying human preferences, and the potential ethical implications of deploying such systems. Addressing these considerations will be crucial for the successful and responsible implementation of this technology in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Autonomous Driving for Safety: A Human-Centric Approach with LLM-Enhanced RLHF
Yuan Sun, Navid Salami Pargoo, Peter J. Jin, Jorge Ortiz
Reinforcement Learning from Human Feedback (RLHF) is popular in large language models (LLMs), whereas traditional Reinforcement Learning (RL) often falls short. Current autonomous driving methods typically utilize either human feedback in machine learning, including RL, or LLMs. Most feedback guides the car agent's learning process (e.g., controlling the car). RLHF is usually applied in the fine-tuning step, requiring direct human preferences, which are not commonly used in optimizing autonomous driving models. In this research, we innovatively combine RLHF and LLMs to enhance autonomous driving safety. Training a model with human guidance from scratch is inefficient. Our framework starts with a pre-trained autonomous car agent model and implements multiple human-controlled agents, such as cars and pedestrians, to simulate real-life road environments. The autonomous car model is not directly controlled by humans. We integrate both physical and physiological feedback to fine-tune the model, optimizing this process using LLMs. This multi-agent interactive environment ensures safe, realistic interactions before real-world application. Finally, we will validate our model using data gathered from real-life testbeds located in New Jersey and New York City.
Read more6/10/2024

0
Trustworthy Human-AI Collaboration: Reinforcement Learning with Human Feedback and Physics Knowledge for Safe Autonomous Driving
Zilin Huang, Zihao Sheng, Sikai Chen
In the field of autonomous driving, developing safe and trustworthy autonomous driving policies remains a significant challenge. Recently, Reinforcement Learning with Human Feedback (RLHF) has attracted substantial attention due to its potential to enhance training safety and sampling efficiency. Nevertheless, existing RLHF-enabled methods often falter when faced with imperfect human demonstrations, potentially leading to training oscillations or even worse performance than rule-based approaches. Inspired by the human learning process, we propose Physics-enhanced Reinforcement Learning with Human Feedback (PE-RLHF). This novel framework synergistically integrates human feedback (e.g., human intervention and demonstration) and physics knowledge (e.g., traffic flow model) into the training loop of reinforcement learning. The key advantage of PE-RLHF is its guarantee that the learned policy will perform at least as well as the given physics-based policy, even when human feedback quality deteriorates, thus ensuring trustworthy safety improvements. PE-RLHF introduces a Physics-enhanced Human-AI (PE-HAI) collaborative paradigm for dynamic action selection between human and physics-based actions, employs a reward-free approach with a proxy value function to capture human preferences, and incorporates a minimal intervention mechanism to reduce the cognitive load on human mentors. Extensive experiments across diverse driving scenarios demonstrate that PE-RLHF significantly outperforms traditional methods, achieving state-of-the-art (SOTA) performance in safety, efficiency, and generalizability, even with varying quality of human feedback. The philosophy behind PE-RLHF not only advances autonomous driving technology but can also offer valuable insights for other safety-critical domains. Demo video and code are available at: https://zilin-huang.github.io/PE-RLHF-website/
Read more9/6/2024
0
In-context Learning for Automated Driving Scenarios
Ziqi Zhou, Jingyue Zhang, Jingyuan Zhang, Boyue Wang, Tianyu Shi, Alaa Khamis
One of the key challenges in current Reinforcement Learning (RL)-based Automated Driving (AD) agents is achieving flexible, precise, and human-like behavior cost-effectively. This paper introduces an innovative approach utilizing Large Language Models (LLMs) to intuitively and effectively optimize RL reward functions in a human-centric way. We developed a framework where instructions and dynamic environment descriptions are input into the LLM. The LLM then utilizes this information to assist in generating rewards, thereby steering the behavior of RL agents towards patterns that more closely resemble human driving. The experimental results demonstrate that this approach not only makes RL agents more anthropomorphic but also reaches better performance. Additionally, various strategies for reward-proxy and reward-shaping are investigated, revealing the significant impact of prompt design on shaping an AD vehicle's behavior. These findings offer a promising direction for the development of more advanced and human-like automated driving systems. Our experimental data and source code can be found here.
Read more5/8/2024
🏅
0
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
Read more5/1/2024