Multilingual Pretraining and Instruction Tuning Improve Cross-Lingual Knowledge Alignment, But Only Shallowly
2404.04659
0
0
Abstract
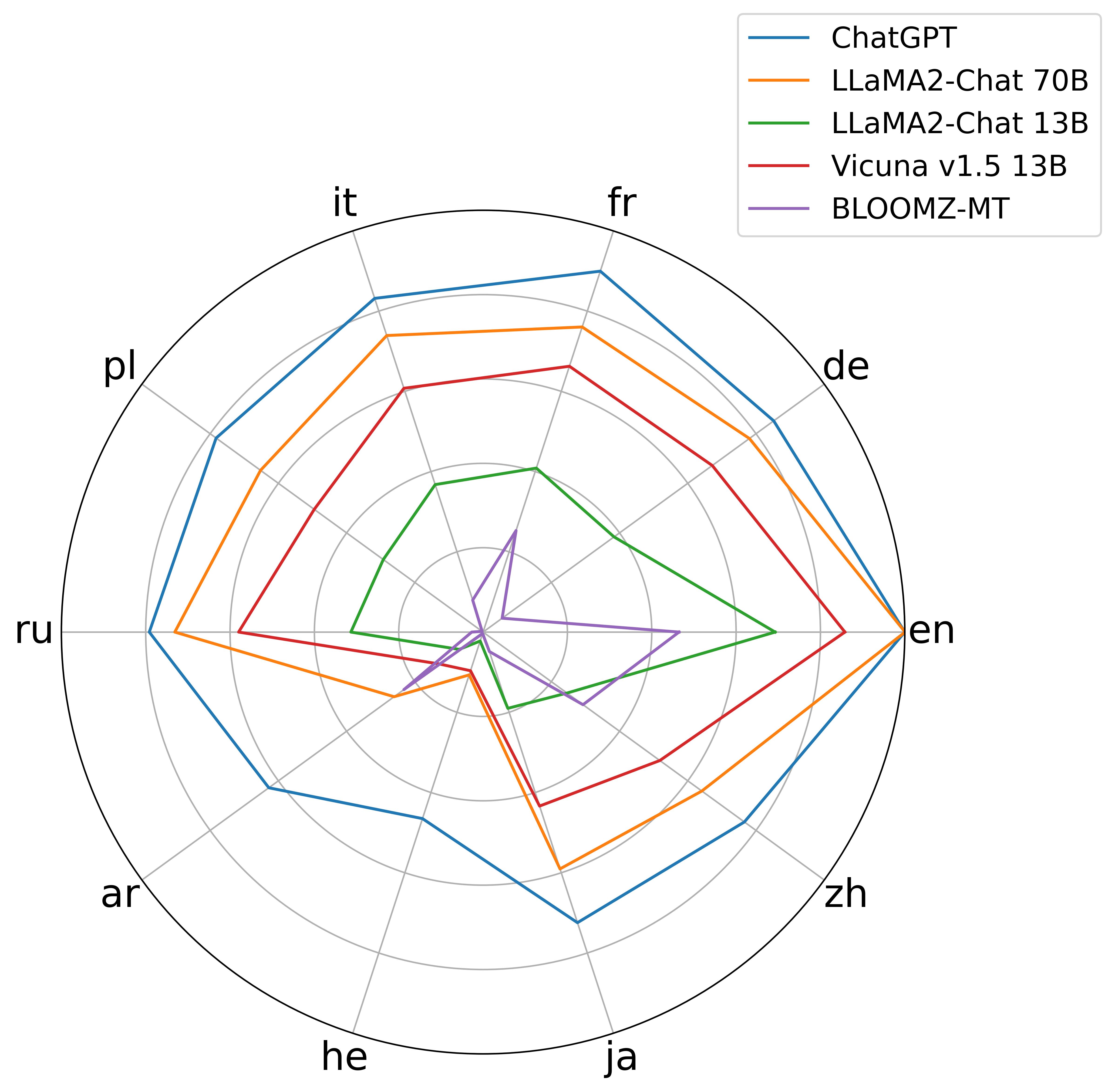
Despite their strong ability to retrieve knowledge in English, current large language models show imbalance abilities in different languages. Two approaches are proposed to address this, i.e., multilingual pretraining and multilingual instruction tuning. However, whether and how do such methods contribute to the cross-lingual knowledge alignment inside the models is unknown. In this paper, we propose CLiKA, a systematic framework to assess the cross-lingual knowledge alignment of LLMs in the Performance, Consistency and Conductivity levels, and explored the effect of multilingual pretraining and instruction tuning on the degree of alignment. Results show that: while both multilingual pretraining and instruction tuning are beneficial for cross-lingual knowledge alignment, the training strategy needs to be carefully designed. Namely, continued pretraining improves the alignment of the target language at the cost of other languages, while mixed pretraining affect other languages less. Also, the overall cross-lingual knowledge alignment, especially in the conductivity level, is unsatisfactory for all tested LLMs, and neither multilingual pretraining nor instruction tuning can substantially improve the cross-lingual knowledge conductivity.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates how multilingual pretraining and instruction tuning affect the alignment of cross-lingual knowledge in large language models.
- The researchers found that these techniques can improve cross-lingual knowledge alignment, but only in a shallow manner, without deeply integrating knowledge across languages.
- The paper provides insights into the limitations of current approaches to cross-lingual transfer and the challenges of achieving deep, generalizable cross-lingual understanding.
Plain English Explanation
This paper looks at how training language models on multiple languages (multilingual pretraining) and fine-tuning them on specific tasks (instruction tuning) affects their ability to understand information across different languages. The researchers found that these techniques can help the models better align their knowledge across languages, but this improvement is only on a surface level. The models don't actually develop a deep, integrated understanding of concepts that can be applied broadly across languages.
This is an important finding because it highlights the limitations of current approaches to building cross-lingual natural language processing systems. While these techniques can provide some benefits, the paper suggests that more work is needed to achieve true, generalizable cross-lingual understanding that can be leveraged in a wide range of applications.
Technical Explanation
The paper examines how multilingual pretraining and instruction tuning impact the cross-lingual knowledge alignment of large language models. The researchers trained several multilingual models using different pretraining and fine-tuning approaches, including TACO, and evaluated their cross-lingual performance on a range of tasks.
The results show that both multilingual pretraining and instruction tuning can improve cross-lingual knowledge alignment to some degree. However, the improvements were primarily limited to shallow, surface-level connections between concepts across languages, without demonstrating deeper, more generalized cross-lingual understanding.
The researchers hypothesize that the psychometric predictive power of these models is constrained by the efficient approach used to train them, which may not be sufficient to achieve truly robust cross-lingual transfer.
Critical Analysis
The paper provides valuable insights into the current limitations of cross-lingual transfer in large language models. While the authors demonstrate that multilingual pretraining and instruction tuning can improve cross-lingual knowledge alignment to some degree, the fact that these improvements are primarily shallow is an important limitation that deserves further exploration.
One potential area for future research could be investigating alternative training approaches or model architectures that may be better suited to achieving deeper, more generalized cross-lingual understanding. Additionally, the paper does not delve into the potential reasons why the current techniques fall short in this regard, which could be an interesting direction for further analysis.
Overall, this paper highlights the need for continued advancements in cross-lingual natural language processing to fully realize the potential of multilingual language models in real-world applications.
Conclusion
This paper investigates the impact of multilingual pretraining and instruction tuning on the cross-lingual knowledge alignment of large language models. The researchers found that these techniques can improve cross-lingual knowledge alignment, but only in a shallow manner, without achieving deeper, more generalized cross-lingual understanding.
This limitation has important implications for the development of truly robust and versatile cross-lingual natural language processing systems. The paper suggests that further advancements in training approaches and model architectures may be necessary to overcome the current constraints and unlock the full potential of multilingual language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CrossIn: An Efficient Instruction Tuning Approach for Cross-Lingual Knowledge Alignment
Geyu Lin, Bin Wang, Zhengyuan Liu, Nancy F. Chen
0
0
Multilingual proficiency presents a significant challenge for large language models (LLMs). English-centric models are usually suboptimal in other languages, particularly those that are linguistically distant from English. This performance discrepancy mainly stems from the imbalanced distribution of training data across languages during pre-training and instruction tuning stages. To address this problem, we propose a novel approach called CrossIn, which utilizes a mixed composition of cross-lingual instruction tuning data. Our method leverages the compressed representation shared by various languages to efficiently enhance the model's task-solving capabilities and multilingual proficiency within a single process. In addition, we introduce a multi-task and multi-faceted benchmark to evaluate the effectiveness of CrossIn. Experimental results demonstrate that our method substantially improves performance across tasks and languages, and we provide extensive insights into the impact of cross-lingual data volume and the integration of translation data on enhancing multilingual consistency and accuracy.
4/19/2024
Zero-shot cross-lingual transfer in instruction tuning of large language models
Nadezhda Chirkova, Vassilina Nikoulina
0
0
Instruction tuning (IT) is widely used to teach pretrained large language models (LLMs) to follow arbitrary instructions, but is under-studied in multilingual settings. In this work, we conduct a systematic study of zero-shot cross-lingual transfer in IT, when an LLM is instruction-tuned on English-only data and then tested on user prompts in other languages. We advocate for the importance of evaluating various aspects of model responses in multilingual instruction following and investigate the influence of different model configuration choices. We find that cross-lingual transfer does happen successfully in IT even if all stages of model training are English-centric, but only if multiliguality is taken into account in hyperparameter tuning and with large enough IT data. English-trained LLMs are capable of generating correct-language, comprehensive and helpful responses in other languages, but suffer from low factuality and may occasionally have fluency errors.
4/23/2024

mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Tianze Hua, Tian Yun, Ellie Pavlick
0
0
Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of anchor tokens (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
4/22/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024