Improving Learnt Local MAPF Policies with Heuristic Search
2403.20300
0
0
Abstract
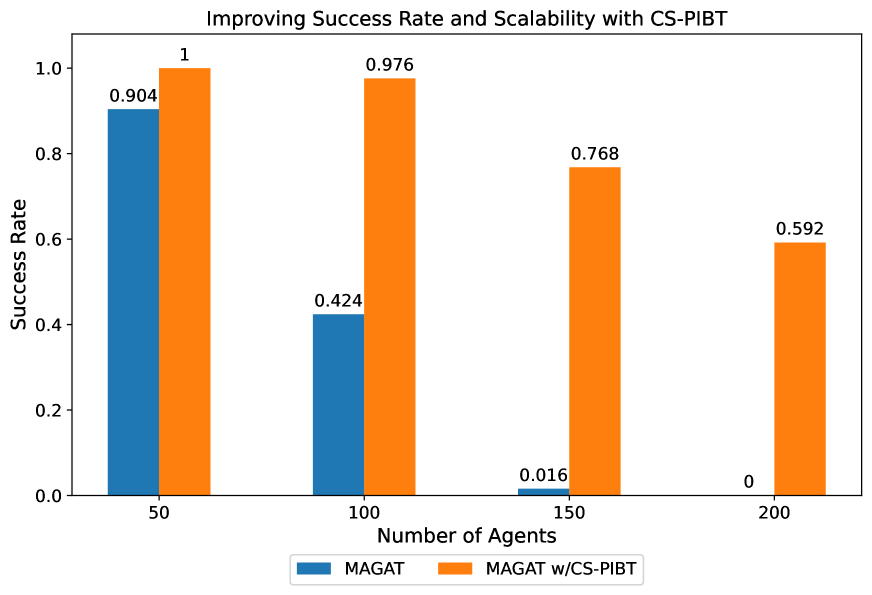
Multi-agent path finding (MAPF) is the problem of finding collision-free paths for a team of agents to reach their goal locations. State-of-the-art classical MAPF solvers typically employ heuristic search to find solutions for hundreds of agents but are typically centralized and can struggle to scale when run with short timeouts. Machine learning (ML) approaches that learn policies for each agent are appealing as these could enable decentralized systems and scale well while maintaining good solution quality. Current ML approaches to MAPF have proposed methods that have started to scratch the surface of this potential. However, state-of-the-art ML approaches produce local policies that only plan for a single timestep and have poor success rates and scalability. Our main idea is that we can improve a ML local policy by using heuristic search methods on the output probability distribution to resolve deadlocks and enable full horizon planning. We show several model-agnostic ways to use heuristic search with learnt policies that significantly improve the policies' success rates and scalability. To our best knowledge, we demonstrate the first time ML-based MAPF approaches have scaled to high congestion scenarios (e.g. 20% agent density).
Create account to get full access
Here is a plain English explanation of the provided research paper:
Overview
- Proposes an approach to improve learnt local policies for multi-agent path finding (MAPF) problems using heuristic search
- MAPF involves finding collision-free paths for multiple agents in a shared environment
- Combines the strengths of learnt policies (fast) and heuristic search (optimality)
- Evaluates the approach on various MAPF scenarios and benchmarks
Plain English Explanation
Multi-agent path finding deals with finding optimal paths for multiple agents (like robots or vehicles) moving in a shared space without colliding. It's like a complex traffic routing problem where each agent needs to reach its destination efficiently while avoiding conflicts with others.
The researchers developed a method that takes advantage of two different approaches: learnt policies and heuristic search. Learnt policies are like rules or behaviors that an AI system has learned from experience, allowing it to make fast decisions. However, these policies may not always find the optimal solution.
Heuristic search, on the other hand, is a more systematic approach that explores different possibilities to find the best solution. It's like having a strategic plan to explore all options, but it can be computationally expensive, especially in complex scenarios.
The proposed method combines the speed of learnt policies with the optimality of heuristic search. It first uses the learnt policy to quickly generate an initial solution. Then, it applies heuristic search to improve that solution, using the learnt policy as a guide to focus the search and reduce computational effort.
It's like having a team of robots where each robot first follows a set of learned behaviors to reach their destinations quickly. However, if they encounter conflicts or suboptimal paths, they switch to a more strategic mode, where they communicate and coordinate their movements to find better solutions while still leveraging their learned behaviors.
Technical Explanation
The researchers developed a two-stage approach:
-
Policy Rollout: In this stage, a learnt local policy is used to generate an initial solution for the MAPF problem. Each agent follows the policy independently, making decisions based on its local observations without explicitly coordinating with others.
-
Heuristic Search: The initial solution from the policy rollout is then used as a starting point for a heuristic search algorithm, such as A* or Conflict-Based Search (CBS). The search explores alternative paths and resolves conflicts, guided by the learnt policy to reduce the search space and computational effort.
The key innovation is the integration of learnt policies with heuristic search, leveraging the strengths of both approaches. The learnt policies provide fast initial solutions, while the heuristic search improves upon these solutions, ensuring optimality or near-optimality.
The researchers evaluated their approach on various MAPF benchmarks, including scenarios with different agent densities, map complexities, and objective functions (e.g., minimizing total travel time or makespan). The results showed that their approach outperformed existing methods in terms of solution quality and computational efficiency.
Critical Analysis
While the proposed approach shows promising results, there are a few considerations and potential limitations:
- The quality of the learnt policies plays a crucial role in the overall performance. If the policies are not well-trained or fail to generalize to new scenarios, the initial solutions may be suboptimal, requiring more computational effort from the heuristic search stage.
- The approach assumes that the learnt policies can generate conflict-free initial solutions. In highly congested or adversarial environments, this assumption may not hold, potentially limiting the effectiveness of the method.
- The computational overhead of the heuristic search stage may still be significant in large-scale or highly complex MAPF problems, although the learnt policies help reduce the search space.
- The researchers focused on specific MAPF scenarios and objective functions. The approach's performance may vary for different problem formulations or constraints, such as dynamic environments or time-varying objectives.
Further research could explore more advanced policy learning techniques, incorporate online adaptation or transfer learning for better generalization, and investigate parallelization or approximation techniques to scale the approach to larger MAPF instances.
Conclusion
The proposed approach offers a promising direction for solving multi-agent path finding problems by combining the strengths of learnt policies and heuristic search. By leveraging the speed of learnt policies and the optimality of heuristic search, the researchers demonstrate improved solution quality and computational efficiency compared to existing methods.
While the approach shows promising results, its real-world applicability may depend on the quality of the learnt policies, the complexity of the MAPF scenarios, and the computational resources available. Further research could explore ways to enhance policy learning, adapt to dynamic environments, and scale the approach to larger problem instances.
The implications of this research could be significant for various applications involving multi-agent coordination, such as autonomous vehicle routing, robot swarm coordination, and traffic management systems. Efficient and optimal path planning for multiple agents in shared environments is a crucial challenge in many domains, and this research contributes to advancing the state-of-the-art in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
Scaling Lifelong Multi-Agent Path Finding to More Realistic Settings: Research Challenges and Opportunities
He Jiang, Yulun Zhang, Rishi Veerapaneni, Jiaoyang Li
0
0
Multi-Agent Path Finding (MAPF) is the problem of moving multiple agents from starts to goals without collisions. Lifelong MAPF (LMAPF) extends MAPF by continuously assigning new goals to agents. We present our winning approach to the 2023 League of Robot Runners LMAPF competition, which leads us to several interesting research challenges and future directions. In this paper, we outline three main research challenges. The first challenge is to search for high-quality LMAPF solutions within a limited planning time (e.g., 1s per step) for a large number of agents (e.g., 10,000) or extremely high agent density (e.g., 97.7%). We present future directions such as developing more competitive rule-based and anytime MAPF algorithms and parallelizing state-of-the-art MAPF algorithms. The second challenge is to alleviate congestion and the effect of myopic behaviors in LMAPF algorithms. We present future directions, such as developing moving guidance and traffic rules to reduce congestion, incorporating future prediction and real-time search, and determining the optimal agent number. The third challenge is to bridge the gaps between the LMAPF models used in the literature and real-world applications. We present future directions, such as dealing with more realistic kinodynamic models, execution uncertainty, and evolving systems.
4/26/2024
🔎
Scalable Mechanism Design for Multi-Agent Path Finding
Paul Friedrich, Yulun Zhang, Michael Curry, Ludwig Dierks, Stephen McAleer, Jiaoyang Li, Tuomas Sandholm, Sven Seuken
0
0
Multi-Agent Path Finding (MAPF) involves determining paths for multiple agents to travel simultaneously and collision-free through a shared area toward given goal locations. This problem is computationally complex, especially when dealing with large numbers of agents, as is common in realistic applications like autonomous vehicle coordination. Finding an optimal solution is often computationally infeasible, making the use of approximate, suboptimal algorithms essential. Adding to the complexity, agents might act in a self-interested and strategic way, possibly misrepresenting their goals to the MAPF algorithm if it benefits them. Although the field of mechanism design offers tools to align incentives, using these tools without careful consideration can fail when only having access to approximately optimal outcomes. In this work, we introduce the problem of scalable mechanism design for MAPF and propose three strategyproof mechanisms, two of which even use approximate MAPF algorithms. We test our mechanisms on realistic MAPF domains with problem sizes ranging from dozens to hundreds of agents. We find that they improve welfare beyond a simple baseline.
5/9/2024

No Panacea in Planning: Algorithm Selection for Suboptimal Multi-Agent Path Finding
Weizhe Chen, Zhihan Wang, Jiaoyang Li, Sven Koenig, Bistra Dilkina
0
0
Since more and more algorithms are proposed for multi-agent path finding (MAPF) and each of them has its strengths, choosing the correct one for a specific scenario that fulfills some specified requirements is an important task. Previous research in algorithm selection for MAPF built a standard workflow and showed that machine learning can help. In this paper, we study general solvers for MAPF, which further include suboptimal algorithms. We propose different groups of optimization objectives and learning tasks to handle the new tradeoff between runtime and solution quality. We conduct extensive experiments to show that the same loss can not be used for different groups of optimization objectives, and that standard computer vision models are no worse than customized architecture. We also provide insightful discussions on how feature-sensitive pre-processing is needed for learning for MAPF, and how different learning metrics are correlated to different learning tasks.
4/5/2024

LNS2+RL: Combining Multi-agent Reinforcement Learning with Large Neighborhood Search in Multi-agent Path Finding
Yutong Wang, Tanishq Duhan, Jiaoyang Li, Guillaume Sartoretti
0
0
Multi-Agent Path Finding (MAPF) is a critical component of logistics and warehouse management, which focuses on planning collision-free paths for a team of robots in a known environment. Recent work introduced a novel MAPF approach, LNS2, which proposed to repair a quickly-obtainable set of infeasible paths via iterative re-planning, by relying on a fast, yet lower-quality, priority-based planner. At the same time, there has been a recent push for Multi-Agent Reinforcement Learning (MARL) based MAPF algorithms, which let agents learn decentralized policies that exhibit improved cooperation over such priority planning, although inevitably remaining slower. In this paper, we introduce a new MAPF algorithm, LNS2+RL, which combines the distinct yet complementary characteristics of LNS2 and MARL to effectively balance their individual limitations and get the best from both worlds. During early iterations, LNS2+RL relies on MARL for low-level re-planning, which we show eliminates collisions much more than a priority-based planner. There, our MARL-based planner allows agents to reason about past and future/predicted information to gradually learn cooperative decision-making through a finely designed curriculum learning. At later stages of planning, LNS2+RL adaptively switches to priority-based planning to quickly resolve the remaining collisions, naturally trading-off solution quality and computational efficiency. Our comprehensive experiments on challenging tasks across various team sizes, world sizes, and map structures consistently demonstrate the superior performance of LNS2+RL compared to many MAPF algorithms, including LNS2, LaCAM, and EECBS, where LNS2+RL shows significantly better performance in complex scenarios. We finally experimentally validate our algorithm in a hybrid simulation of a warehouse mockup involving a team of 100 (real-world and simulated) robots.
5/29/2024