LNS2+RL: Combining Multi-agent Reinforcement Learning with Large Neighborhood Search in Multi-agent Path Finding
2405.17794
0
0

Abstract
Multi-Agent Path Finding (MAPF) is a critical component of logistics and warehouse management, which focuses on planning collision-free paths for a team of robots in a known environment. Recent work introduced a novel MAPF approach, LNS2, which proposed to repair a quickly-obtainable set of infeasible paths via iterative re-planning, by relying on a fast, yet lower-quality, priority-based planner. At the same time, there has been a recent push for Multi-Agent Reinforcement Learning (MARL) based MAPF algorithms, which let agents learn decentralized policies that exhibit improved cooperation over such priority planning, although inevitably remaining slower. In this paper, we introduce a new MAPF algorithm, LNS2+RL, which combines the distinct yet complementary characteristics of LNS2 and MARL to effectively balance their individual limitations and get the best from both worlds. During early iterations, LNS2+RL relies on MARL for low-level re-planning, which we show eliminates collisions much more than a priority-based planner. There, our MARL-based planner allows agents to reason about past and future/predicted information to gradually learn cooperative decision-making through a finely designed curriculum learning. At later stages of planning, LNS2+RL adaptively switches to priority-based planning to quickly resolve the remaining collisions, naturally trading-off solution quality and computational efficiency. Our comprehensive experiments on challenging tasks across various team sizes, world sizes, and map structures consistently demonstrate the superior performance of LNS2+RL compared to many MAPF algorithms, including LNS2, LaCAM, and EECBS, where LNS2+RL shows significantly better performance in complex scenarios. We finally experimentally validate our algorithm in a hybrid simulation of a warehouse mockup involving a team of 100 (real-world and simulated) robots.
Create account to get full access
Overview
- This paper presents a new approach called LNS2+RL that combines Multi-agent Reinforcement Learning (MARL) with Large Neighborhood Search (LNS) to solve the Multi-agent Path Finding (MAPF) problem.
- MAPF is a challenging optimization problem where multiple agents need to find collision-free paths to their destinations.
- The authors propose integrating MARL, which allows agents to learn cooperative behaviors, with LNS, a powerful optimization technique, to create a more effective solution for MAPF.
Plain English Explanation
The paper focuses on the problem of Multi-agent Path Finding (MAPF), where multiple agents need to find paths to their destinations without colliding with each other. This is a complex optimization challenge, as the agents need to coordinate their movements to avoid conflicts.
The researchers developed a new approach called LNS2+RL that combines two powerful techniques: Multi-agent Reinforcement Learning (MARL) and Large Neighborhood Search (LNS).
MARL allows the agents to learn cooperative behaviors through trial and error, similar to how humans learn to work together. This helps the agents find more efficient and coordinated paths.
LNS is an optimization technique that explores a "large neighborhood" of possible solutions, searching for the best one. By combining MARL and LNS, the researchers created a more powerful approach that can find high-quality solutions to MAPF problems.
The key idea is to let the agents learn how to coordinate their movements through MARL, and then use LNS to further optimize the paths, ensuring they are collision-free and efficient. This hybrid approach takes advantage of the strengths of both techniques to solve the MAPF problem more effectively.
Technical Explanation
The authors propose the LNS2+RL algorithm, which integrates Multi-agent Reinforcement Learning (MARL) and Large Neighborhood Search (LNS) to solve the Multi-agent Path Finding (MAPF) problem.
In the first stage, the agents use MARL to learn cooperative behaviors and policies for navigating the environment. The agents receive rewards based on their ability to reach their destinations without collisions, which incentivizes them to learn coordinated movement strategies.
In the second stage, the LNS component is used to further optimize the paths found by the MARL agents. LNS explores a "large neighborhood" of possible solutions, considering various combinations of agent paths and searching for the globally optimal solution.
The key innovation of LNS2+RL is the integration of these two techniques. The MARL component allows the agents to learn how to cooperate, while the LNS component ensures that the final solution is collision-free and efficient. By combining the strengths of both approaches, the authors demonstrate that LNS2+RL outperforms existing MAPF algorithms in terms of solution quality and computational efficiency.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the LNS2+RL algorithm, with experiments on a variety of MAPF instances and comparisons to several baseline methods. The results show that LNS2+RL can find high-quality solutions to MAPF problems more efficiently than other approaches.
However, the paper does acknowledge some limitations of the proposed method. For example, the LNS component can be computationally expensive, especially for larger problem instances. The authors suggest that further research is needed to improve the scalability of the LNS2+RL algorithm.
Additionally, the paper does not discuss the potential challenges of applying MARL in real-world MAPF scenarios, where factors like sensor noise, communication delays, and dynamic environments may affect the agents' ability to learn and coordinate effectively. Further research is needed to address these practical concerns.
Overall, the LNS2+RL approach represents a promising step forward in solving the MAPF problem, but there are still opportunities for improvement and further exploration of the technique's strengths and limitations.
Conclusion
The LNS2+RL algorithm presented in this paper demonstrates a novel and effective approach to solving the Multi-agent Path Finding (MAPF) problem. By combining Multi-agent Reinforcement Learning (MARL) and Large Neighborhood Search (LNS), the authors have created a hybrid method that can find high-quality, collision-free solutions to MAPF instances more efficiently than existing algorithms.
The key insights of this research are the benefits of integrating learning-based and optimization-based techniques to tackle complex multi-agent coordination problems. The MARL component allows the agents to learn cooperative behaviors, while the LNS component ensures the final solution is globally optimal.
While the paper identifies some limitations in terms of computational complexity, the LNS2+RL approach represents an important advancement in the field of MAPF and multi-agent systems. Further research to address the scalability and real-world applicability of this technique could lead to significant improvements in areas like autonomous transportation, warehouse logistics, and multi-robot coordination.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
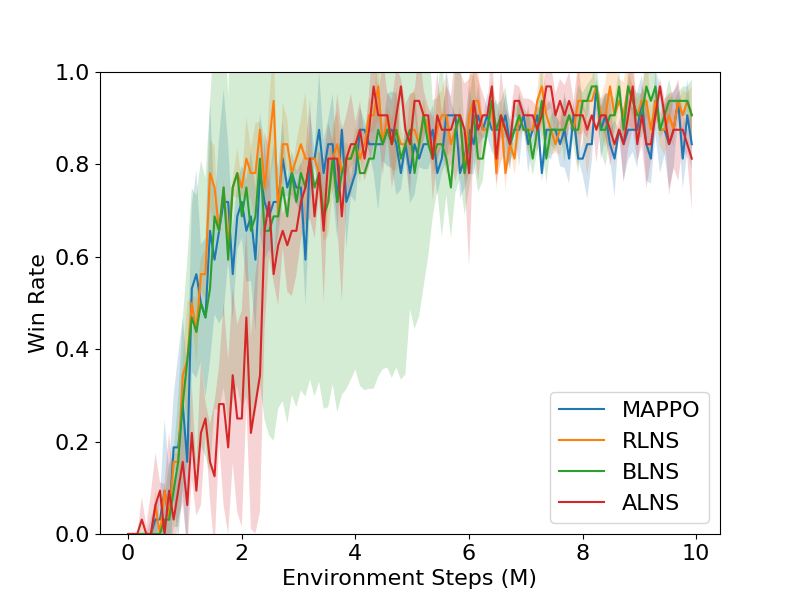
MARL-LNS: Cooperative Multi-agent Reinforcement Learning via Large Neighborhoods Search
Weizhe Chen, Sven Koenig, Bistra Dilkina
0
0
Cooperative multi-agent reinforcement learning (MARL) has been an increasingly important research topic in the last half-decade because of its great potential for real-world applications. Because of the curse of dimensionality, the popular centralized training decentralized execution framework requires a long time in training, yet still cannot converge efficiently. In this paper, we propose a general training framework, MARL-LNS, to algorithmically address these issues by training on alternating subsets of agents using existing deep MARL algorithms as low-level trainers, while not involving any additional parameters to be trained. Based on this framework, we provide three algorithm variants based on the framework: random large neighborhood search (RLNS), batch large neighborhood search (BLNS), and adaptive large neighborhood search (ALNS), which alternate the subsets of agents differently. We test our algorithms on both the StarCraft Multi-Agent Challenge and Google Research Football, showing that our algorithms can automatically reduce at least 10% of training time while reaching the same final skill level as the original algorithm.
4/5/2024
🤖
Scaling Lifelong Multi-Agent Path Finding to More Realistic Settings: Research Challenges and Opportunities
He Jiang, Yulun Zhang, Rishi Veerapaneni, Jiaoyang Li
0
0
Multi-Agent Path Finding (MAPF) is the problem of moving multiple agents from starts to goals without collisions. Lifelong MAPF (LMAPF) extends MAPF by continuously assigning new goals to agents. We present our winning approach to the 2023 League of Robot Runners LMAPF competition, which leads us to several interesting research challenges and future directions. In this paper, we outline three main research challenges. The first challenge is to search for high-quality LMAPF solutions within a limited planning time (e.g., 1s per step) for a large number of agents (e.g., 10,000) or extremely high agent density (e.g., 97.7%). We present future directions such as developing more competitive rule-based and anytime MAPF algorithms and parallelizing state-of-the-art MAPF algorithms. The second challenge is to alleviate congestion and the effect of myopic behaviors in LMAPF algorithms. We present future directions, such as developing moving guidance and traffic rules to reduce congestion, incorporating future prediction and real-time search, and determining the optimal agent number. The third challenge is to bridge the gaps between the LMAPF models used in the literature and real-world applications. We present future directions, such as dealing with more realistic kinodynamic models, execution uncertainty, and evolving systems.
4/26/2024

Caching-Augmented Lifelong Multi-Agent Path Finding
Yimin Tang, Zhenghong Yu, Yi Zheng, T. K. Satish Kumar, Jiaoyang Li, Sven Koenig
0
0
Multi-Agent Path Finding (MAPF), which involves finding collision-free paths for multiple robots, is crucial in various applications. Lifelong MAPF, where targets are reassigned to agents as soon as they complete their initial targets, offers a more accurate approximation of real-world warehouse planning. In this paper, we present a novel mechanism named Caching-Augmented Lifelong MAPF (CAL-MAPF), designed to improve the performance of Lifelong MAPF. We have developed a new type of map grid called cache for temporary item storage and replacement, and created a locking mechanism to improve the planning solution's stability. A task assigner (TA) is designed for CAL-MAPF to allocate target locations to agents and control agent status in different situations. CAL-MAPF has been evaluated using various cache replacement policies and input task distributions. We have identified three main factors significantly impacting CAL-MAPF performance through experimentation: suitable input task distribution, high cache hit rate, and smooth traffic. In general, CAL-MAPF has demonstrated potential for performance improvements in certain task distributions, map and agent configurations.
4/9/2024

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024