Improving LLM Abilities in Idiomatic Translation

0
✅
Sign in to get full access
Overview
- Large language models (LLMs) like NLLB and GPT face challenges in accurately translating idioms
- The goal is to enhance translation fidelity by improving LLM processing of idiomatic language while preserving the original linguistic style
- This has significant social impact, as it preserves cultural nuances and ensures translated texts retain their intent and emotional resonance, fostering better cross-cultural communication
Plain English Explanation
Idioms are common expressions in language that have a meaning different from the individual words. For example, "it's raining cats and dogs" doesn't mean actual cats and dogs are falling from the sky, but rather that it's raining heavily. Translating idioms accurately is a challenge for large language models used for tasks like machine translation.
The researchers in this paper aimed to improve how LLMs handle idiomatic language during translation, so the final translated text maintains the original linguistic style and cultural nuances. This is important for effective cross-cultural communication, as it ensures the intended meaning and emotional impact of the original text is preserved.
Previous methods have used knowledge bases to provide the LLM with the meaning of an idiom to use in translation. However, this approach was limited in its ability to also preserve the idiomatic writing style across languages. The researchers in this paper built upon this idea by finding corresponding idioms in the target language to use in the translation.
They tested two methods: 1) using a semantic similarity model to match the original idiom meaning to the best target language idiom, and 2) using the LLM itself to generate a corresponding target language idiom. They compared these to a baseline of direct translation without additional information.
Human evaluations showed the semantic similarity (Cosine Similarity Lookup) method outperformed the other approaches for translating English to Chinese and Chinese to English. The researchers also developed a dataset of Urdu idioms and translations to further build upon this work, demonstrating the potential to overcome language barriers and enable exploration of diverse literary works.
Technical Explanation
The researchers' goal was to enhance the translation fidelity of LLMs like NLLB and GPT when handling idiomatic language, while preserving the original linguistic style. They built upon previous work that used knowledge bases like IdiomKB to provide the LLM with the meaning of an idiom to use in translation.
To go beyond just the meaning, the researchers explored finding corresponding idioms in the target language to use in the translation. They tested two methods:
-
Cosine Similarity Lookup Method: This used the SentenceTransformers model to generate semantic similarity scores between the original and target language idioms, then selected the best matching idiom.
-
LLM-generated Idiom Method: This had the LLM itself find a corresponding idiom in the target language for use in the translation.
They compared these methods to a baseline of direct translation without providing additional information.
Human evaluations on English -> Chinese and Chinese -> English translations showed the Cosine Similarity Lookup method outperformed the others. To further build upon IdiomKB, the researchers also developed a low-resource Urdu dataset containing Urdu idioms and their translations.
Critical Analysis
The researchers acknowledge the limitations of their Urdu dataset, as it is low-resource. However, they demonstrate the potential of the Cosine Similarity Lookup method to overcome language barriers and enable the exploration of diverse literary works in languages like Chinese and Urdu.
One area for further research could be to explore the broader applicability of this approach to a wider range of languages and idioms. Additionally, the researchers could investigate ways to further improve the LLM-generated Idiom method, as it may have untapped potential for certain language pairs or use cases.
Overall, this research represents a promising step forward in enhancing the translation capabilities of large language models when dealing with idiomatic language, which has important implications for cross-cultural understanding and communication.
Conclusion
This research aimed to improve the translation fidelity of large language models when handling idiomatic language, preserving the original linguistic style and cultural nuances. The researchers explored two methods to find corresponding idioms in the target language, with the Cosine Similarity Lookup approach outperforming other methods in human evaluations.
By developing a low-resource Urdu dataset and demonstrating the potential of their techniques, the researchers have laid the groundwork for further advances in this area. Improving the translation of idiomatic language has significant social impact, as it fosters better cross-cultural communication and enables the exploration of diverse literary works across language barriers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Improving LLM Abilities in Idiomatic Translation
Sundesh Donthi, Maximilian Spencer, Om Patel, Joon Doh, Eid Rodan
For large language models (LLMs) like NLLB and GPT, translating idioms remains a challenge. Our goal is to enhance translation fidelity by improving LLM processing of idiomatic language while preserving the original linguistic style. This has a significant social impact, as it preserves cultural nuances and ensures translated texts retain their intent and emotional resonance, fostering better cross-cultural communication. Previous work has utilized knowledge bases like IdiomKB by providing the LLM with the meaning of an idiom to use in translation. Although this method yielded better results than a direct translation, it is still limited in its ability to preserve idiomatic writing style across languages. In this research, we expand upon the knowledge base to find corresponding idioms in the target language. Our research performs translations using two methods: The first method employs the SentenceTransformers model to semantically generate cosine similarity scores between the meanings of the original and target language idioms, selecting the best idiom (Cosine Similarity method). The second method uses an LLM to find a corresponding idiom in the target language for use in the translation (LLM-generated idiom method). As a baseline, we performed a direct translation without providing additional information. Human evaluations on the English -> Chinese, and Chinese -> English show the Cosine Similarity Lookup method out-performed others in all GPT4o translations. To further build upon IdiomKB, we developed a low-resource Urdu dataset containing Urdu idioms and their translations. Despite dataset limitations, the Cosine Similarity Lookup method shows promise, potentially overcoming language barriers and enabling the exploration of diverse literary works in Chinese and Urdu.
Read more7/17/2024

0
Sign of the Times: Evaluating the use of Large Language Models for Idiomaticity Detection
Dylan Phelps, Thomas Pickard, Maggie Mi, Edward Gow-Smith, Aline Villavicencio
Despite the recent ubiquity of large language models and their high zero-shot prompted performance across a wide range of tasks, it is still not known how well they perform on tasks which require processing of potentially idiomatic language. In particular, how well do such models perform in comparison to encoder-only models fine-tuned specifically for idiomaticity tasks? In this work, we attempt to answer this question by looking at the performance of a range of LLMs (both local and software-as-a-service models) on three idiomaticity datasets: SemEval 2022 Task 2a, FLUTE, and MAGPIE. Overall, we find that whilst these models do give competitive performance, they do not match the results of fine-tuned task-specific models, even at the largest scales (e.g. for GPT-4). Nevertheless, we do see consistent performance improvements across model scale. Additionally, we investigate prompting approaches to improve performance, and discuss the practicalities of using LLMs for these tasks.
Read more5/16/2024
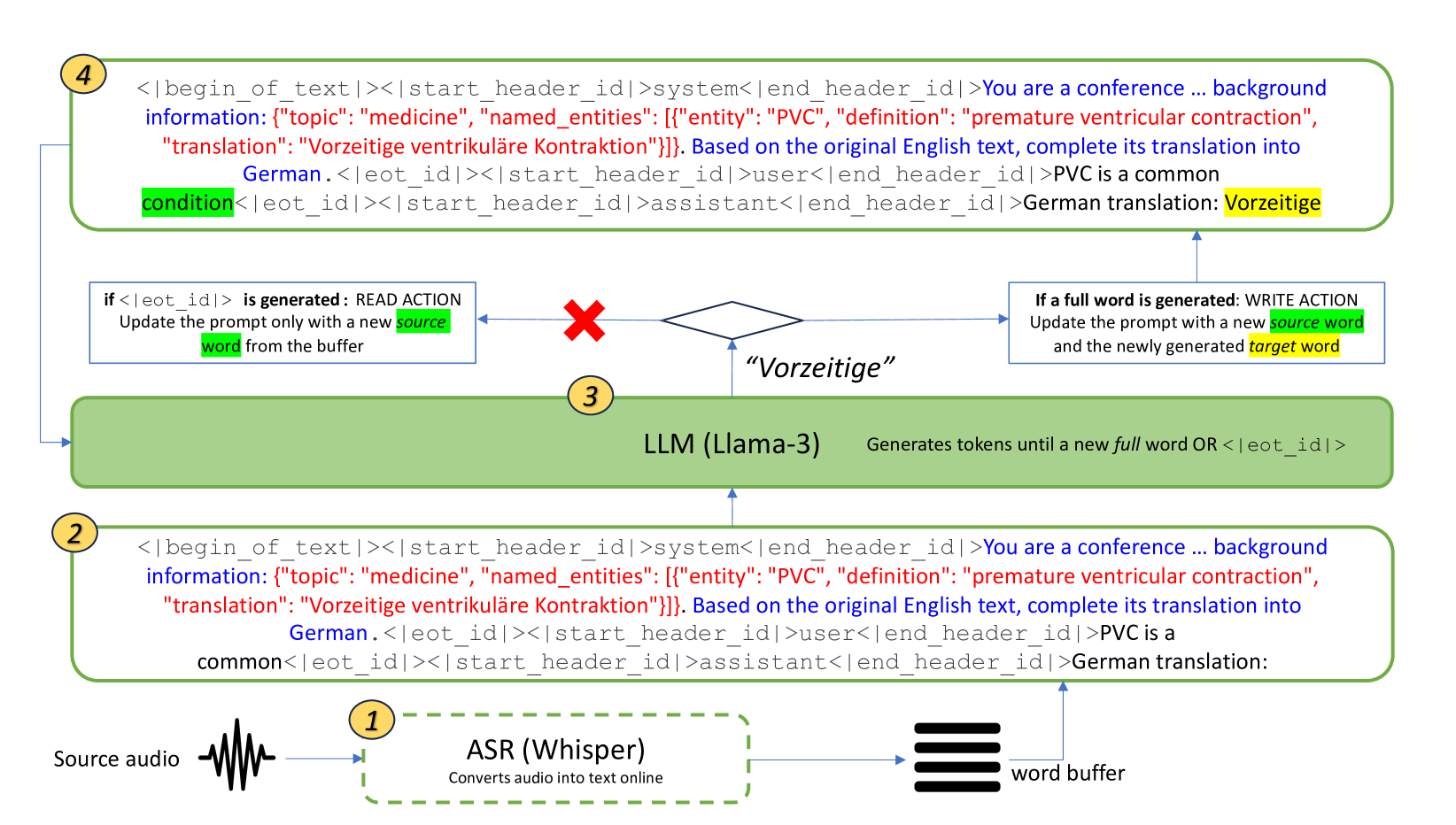
0
LLMs Are Zero-Shot Context-Aware Simultaneous Translators
Roman Koshkin, Katsuhito Sudoh, Satoshi Nakamura
The advent of transformers has fueled progress in machine translation. More recently large language models (LLMs) have come to the spotlight thanks to their generality and strong performance in a wide range of language tasks, including translation. Here we show that open-source LLMs perform on par with or better than some state-of-the-art baselines in simultaneous machine translation (SiMT) tasks, zero-shot. We also demonstrate that injection of minimal background information, which is easy with an LLM, brings further performance gains, especially on challenging technical subject-matter. This highlights LLMs' potential for building next generation of massively multilingual, context-aware and terminologically accurate SiMT systems that require no resource-intensive training or fine-tuning.
Read more6/24/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024