Improving Long Text Understanding with Knowledge Distilled from Summarization Model
2405.04955
0
0
🤔
Abstract
Long text understanding is important yet challenging for natural language processing. A long article or document usually contains many redundant words that are not pertinent to its gist and sometimes can be regarded as noise. With recent advances of abstractive summarization, we propose our emph{Gist Detector} to leverage the gist detection ability of a summarization model and integrate the extracted gist into downstream models to enhance their long text understanding ability. Specifically, Gist Detector first learns the gist detection knowledge distilled from a summarization model, and then produces gist-aware representations to augment downstream models. We evaluate our method on three different tasks: long document classification, distantly supervised open-domain question answering, and non-parallel text style transfer. The experimental results show that our method can significantly improve the performance of baseline models on all tasks.
Create account to get full access
Overview
- This paper proposes a novel approach called "Gist Detector" to enhance the long text understanding ability of natural language processing models.
- The key idea is to leverage the gist detection capability of a summarization model and integrate the extracted gist information into downstream models.
- The authors evaluate their method on three different tasks: long document classification, distantly supervised open-domain question answering, and non-parallel text style transfer.
- The experimental results show that the Gist Detector can significantly improve the performance of baseline models on all these tasks.
Plain English Explanation
Long articles or documents often contain many redundant words that are not essential to the main idea or "gist" of the text. Advances in abstractive summarization have enabled models to better capture the core meaning of a long piece of writing. The authors of this paper propose a way to leverage this gist detection capability to enhance the performance of other natural language processing tasks that involve understanding long-form text.
Their approach, called the "Gist Detector", first learns the gist detection knowledge from a summarization model. It then uses this knowledge to produce gist-aware representations that can be integrated into downstream models, such as those used for long document classification, open-domain question answering, and text style transfer. By incorporating the gist information, these downstream models can better understand the core meaning of the long-form text, leading to improved performance on the respective tasks.
Technical Explanation
The authors first train a summarization model to learn the ability to extract the gist or core meaning from long input text. They then use this trained summarization model to distill the gist detection knowledge, which is then integrated into the downstream models.
Specifically, the Gist Detector consists of two main components:
-
Gist Detector Module: This module learns the gist detection capability from the summarization model using knowledge distillation techniques. It takes the long input text and produces a gist-aware representation.
-
Gist-Aware Representation: The gist-aware representation produced by the Gist Detector module is then concatenated with the original input representation and fed into the downstream models to enhance their long text understanding ability.
The authors evaluate their Gist Detector approach on three different tasks: long document classification, distantly supervised open-domain question answering, and non-parallel text style transfer. The results show that incorporating the gist-aware representations can significantly improve the performance of the baseline models on all these tasks, demonstrating the effectiveness of the proposed method.
Critical Analysis
The paper presents a novel and promising approach to leveraging the gist detection capabilities of summarization models to enhance the performance of various natural language processing tasks involving long-form text. However, the authors do not provide much discussion on the potential limitations or caveats of their method.
For example, the paper does not explore how the Gist Detector's performance might vary across different types of long-form text or domains. It would be interesting to see if the method generalizes well or if there are certain characteristics of the input text that pose challenges.
Additionally, the authors do not delve into the potential tradeoffs or computational costs associated with integrating the gist-aware representations into the downstream models. Automated text mining and experimental methodologies could provide useful insights in this regard.
Overall, the Gist Detector approach is a valuable contribution to the field of long text understanding, but further research is needed to fully understand its limitations and potential for real-world applications.
Conclusion
This paper introduces the Gist Detector, a novel method that leverages the gist detection capabilities of summarization models to enhance the long text understanding ability of various natural language processing tasks. By incorporating the gist-aware representations, the authors demonstrate significant performance improvements on long document classification, open-domain question answering, and text style transfer.
The Gist Detector approach represents an important step forward in addressing the challenges of long text understanding, which is a critical aspect of many real-world applications. The findings of this research suggest that integrating gist information can be a powerful way to improve the performance of natural language processing models when dealing with lengthy, complex input texts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Thesis: Document Summarization with applications to Keyword extraction and Image Retrieval
Jayaprakash Sundararaj
0
0
Automatic summarization is the process of reducing a text document in order to generate a summary that retains the most important points of the original document. In this work, we study two problems - i) summarizing a text document as set of keywords/caption, for image recommedation, ii) generating opinion summary which good mix of relevancy and sentiment with the text document. Intially, we present our work on an recommending images for enhancing a substantial amount of existing plain text news articles. We use probabilistic models and word similarity heuristics to generate captions and extract Key-phrases which are re-ranked using a rank aggregation framework with relevance feedback mechanism. We show that such rank aggregation and relevant feedback which are typically used in Tagging Documents, Text Information Retrieval also helps in improving image retrieval. These queries are fed to the Yahoo Search Engine to obtain relevant images 1. Our proposed method is observed to perform better than all existing baselines. Additonally, We propose a set of submodular functions for opinion summarization. Opinion summarization has built in it the tasks of summarization and sentiment detection. However, it is not easy to detect sentiment and simultaneously extract summary. The two tasks conflict in the sense that the demand of compression may drop sentiment bearing sentences, and the demand of sentiment detection may bring in redundant sentences. However, using submodularity we show how to strike a balance between the two requirements. Our functions generate summaries such that there is good correlation between document sentiment and summary sentiment along with good ROUGE score. We also compare the performances of the proposed submodular functions.
6/4/2024

Utilizing GPT to Enhance Text Summarization: A Strategy to Minimize Hallucinations
Hassan Shakil, Zeydy Ortiz, Grant C. Forbes
0
0
In this research, we uses the DistilBERT model to generate extractive summary and the T5 model to generate abstractive summaries. Also, we generate hybrid summaries by combining both DistilBERT and T5 models. Central to our research is the implementation of GPT-based refining process to minimize the common problem of hallucinations that happens in AI-generated summaries. We evaluate unrefined summaries and, after refining, we also assess refined summaries using a range of traditional and novel metrics, demonstrating marked improvements in the accuracy and reliability of the summaries. Results highlight significant improvements in reducing hallucinatory content, thereby increasing the factual integrity of the summaries.
5/8/2024
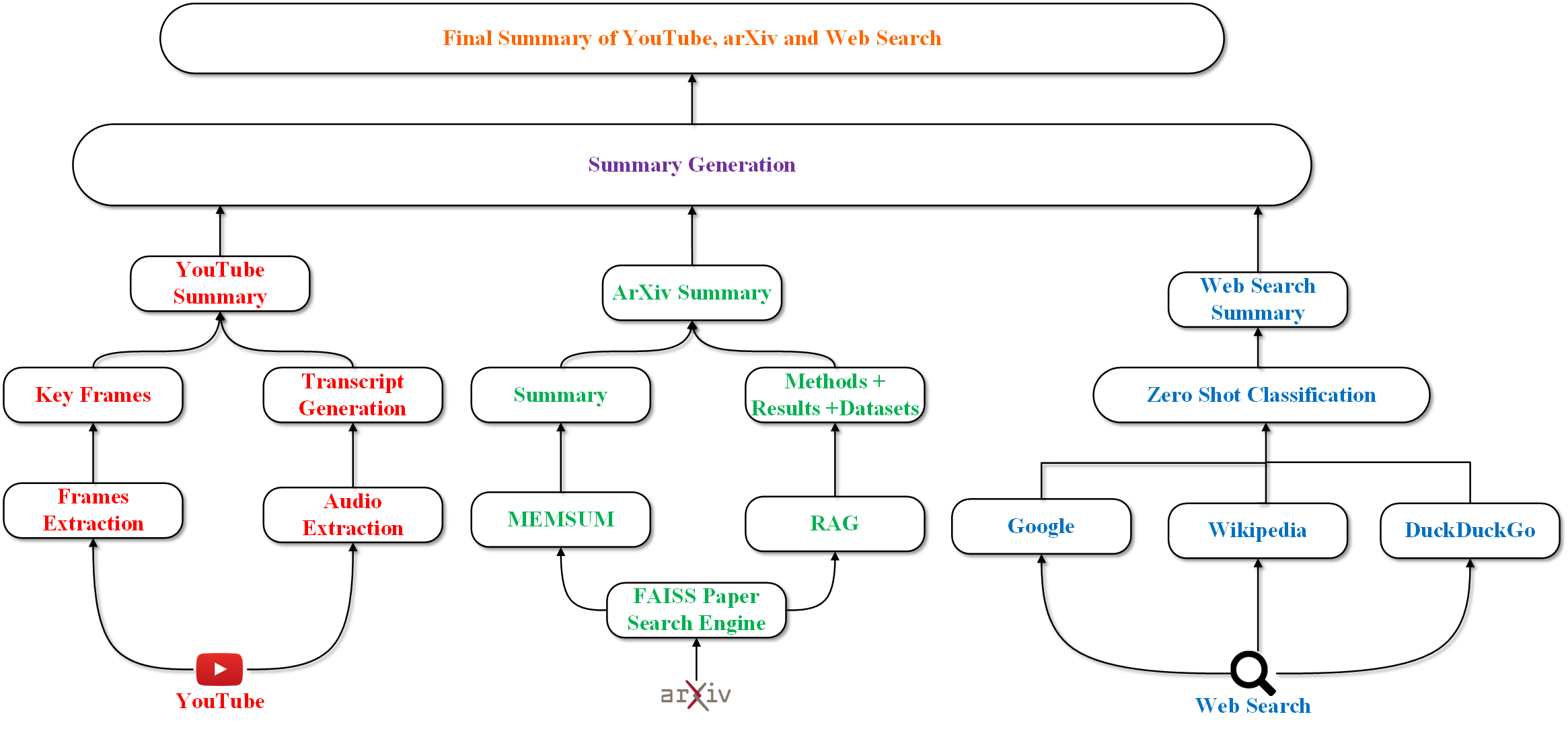
Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
Pranav Janjani, Mayank Palan, Sarvesh Shirude, Ninad Shegokar, Sunny Kumar, Faruk Kazi
0
0
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
6/21/2024
⛏️
Research on Information Extraction of LCSTS Dataset Based on an Improved BERTSum-LSTM Model
Yiming Chen, Haobin Chen, Simin Liu, Yunyun Liu, Fanhao Zhou, Bing Wei
0
0
With the continuous advancement of artificial intelligence, natural language processing technology has become widely utilized in various fields. At the same time, there are many challenges in creating Chinese news summaries. First of all, the semantics of Chinese news is complex, and the amount of information is enormous. Extracting critical information from Chinese news presents a significant challenge. Second, the news summary should be concise and clear, focusing on the main content and avoiding redundancy. In addition, the particularity of the Chinese language, such as polysemy, word segmentation, etc., makes it challenging to generate Chinese news summaries. Based on the above, this paper studies the information extraction method of the LCSTS dataset based on an improved BERTSum-LSTM model. We improve the BERTSum-LSTM model to make it perform better in generating Chinese news summaries. The experimental results show that the proposed method has a good effect on creating news summaries, which is of great importance to the construction of news summaries.
6/27/2024