Converging Dimensions: Information Extraction and Summarization through Multisource, Multimodal, and Multilingual Fusion
2406.13715
0
0
Abstract
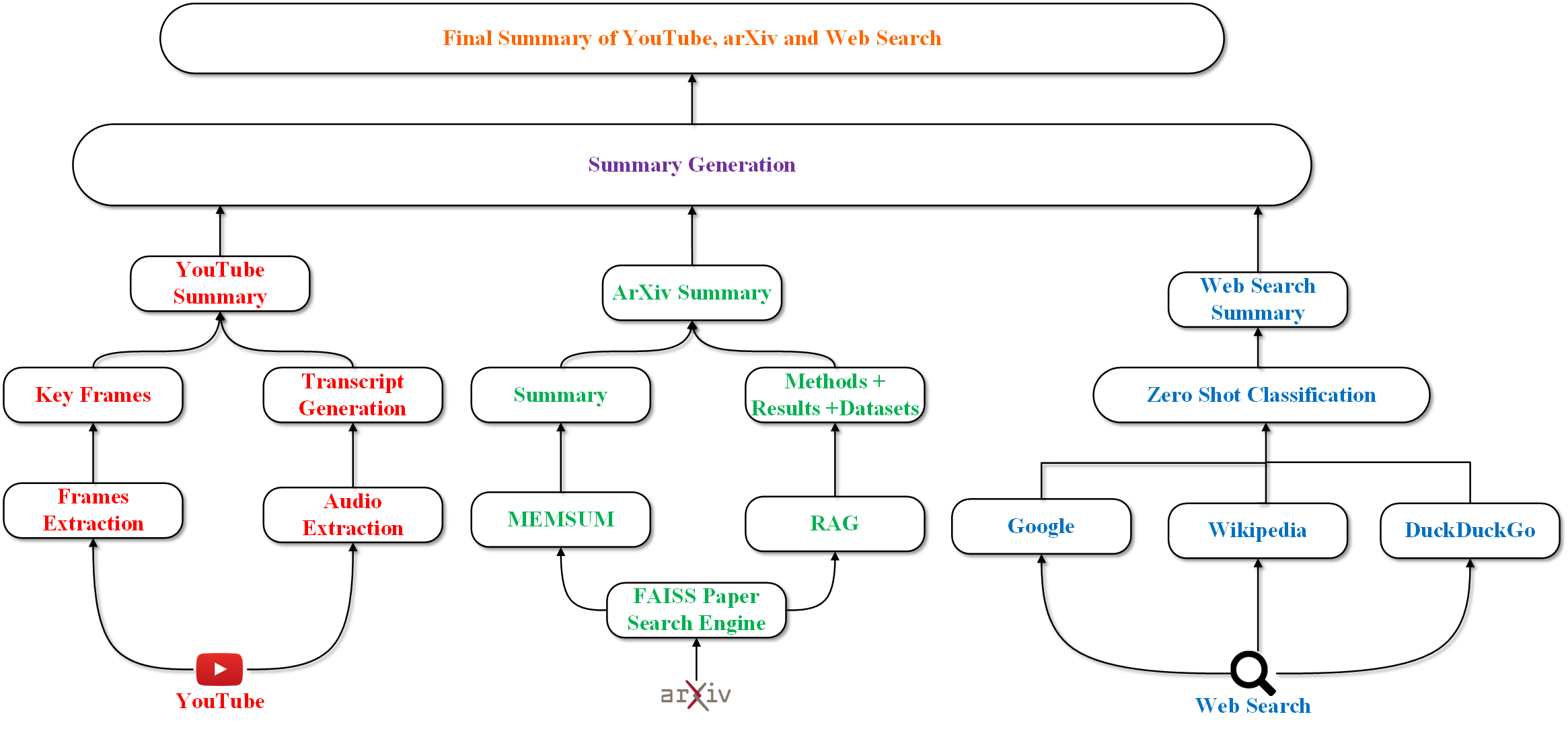
Recent advances in large language models (LLMs) have led to new summarization strategies, offering an extensive toolkit for extracting important information. However, these approaches are frequently limited by their reliance on isolated sources of data. The amount of information that can be gathered is limited and covers a smaller range of themes, which introduces the possibility of falsified content and limited support for multilingual and multimodal data. The paper proposes a novel approach to summarization that tackles such challenges by utilizing the strength of multiple sources to deliver a more exhaustive and informative understanding of intricate topics. The research progresses beyond conventional, unimodal sources such as text documents and integrates a more diverse range of data, including YouTube playlists, pre-prints, and Wikipedia pages. The aforementioned varied sources are then converted into a unified textual representation, enabling a more holistic analysis. This multifaceted approach to summary generation empowers us to extract pertinent information from a wider array of sources. The primary tenet of this approach is to maximize information gain while minimizing information overlap and maintaining a high level of informativeness, which encourages the generation of highly coherent summaries.
Create account to get full access
Overview
- Explores how information extraction and summarization can be enhanced through the fusion of multiple sources, modalities, and languages
- Investigates ways to leverage diverse data inputs to generate more comprehensive and accurate outputs
- Focuses on advancements in multimodal summarization, multilingual summarization, and long-form summarization
Plain English Explanation
This research paper examines how we can improve information extraction and summarization by combining different types of data, such as text, images, and audio, as well as information in multiple languages. The key idea is that by fusing together diverse sources of information, we can generate more complete and accurate summaries compared to using a single source alone.
For example, imagine you're trying to summarize an article about a new medical treatment. If you only look at the text, you might miss important details. But if you also have access to associated images, videos, and even multilingual sources, you can piece together a much richer and more comprehensive summary. The paper investigates ways to leverage these multimodal and multilingual inputs to improve the quality and depth of information extraction and summarization.
Technical Explanation
The paper presents a framework for fusing information from multiple sources, modalities, and languages to enhance both information extraction and summarization. The core idea is to develop models that can effectively combine diverse data inputs, such as text, images, audio, and multilingual content, to generate more comprehensive and accurate output.
The authors explore several key technical challenges, including:
- Effectively aligning and integrating information from disparate sources and modalities
- Handling linguistic and cultural differences when fusing multilingual data
- Generating coherent and concise summaries that capture the most salient information
To address these challenges, the paper investigates advancements in areas like multimodal deep learning, cross-lingual transfer learning, and long-form summarization. The authors present novel architectures and training strategies to effectively leverage the complementary nature of diverse data sources and modalities.
Critical Analysis
The paper makes a compelling case for the benefits of fusing information from multiple sources, modalities, and languages to improve information extraction and summarization. The technical approaches described seem promising, and the authors acknowledge several key challenges and limitations that warrant further research.
One potential concern is the scalability and generalizability of the proposed methods. While the paper demonstrates promising results on specific datasets and tasks, it's unclear how well the techniques would perform in more diverse, real-world scenarios with noisy, incomplete, or conflicting data. Additional research is needed to assess the robustness and applicability of these approaches across a wider range of use cases.
Furthermore, the paper does not delve deeply into the potential biases and ethical considerations that may arise when combining data from disparate sources and modalities. As these techniques become more advanced and widely deployed, it will be critical to carefully examine the social and societal implications to ensure the technology is being developed and used responsibly.
Conclusion
This research paper presents a compelling vision for how information extraction and summarization can be enhanced through the fusion of multiple sources, modalities, and languages. By leveraging the complementary strengths of diverse data inputs, the proposed approaches have the potential to generate more comprehensive, accurate, and insightful summaries that can benefit a wide range of applications, from academic research to journalism and beyond.
While further research is needed to address the scalability and ethical considerations of these techniques, the core ideas outlined in this paper represent an important step forward in the field of multimodal and multilingual information processing and summarization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Modular Approach for Multimodal Summarization of TV Shows
Louis Mahon, Mirella Lapata
0
0
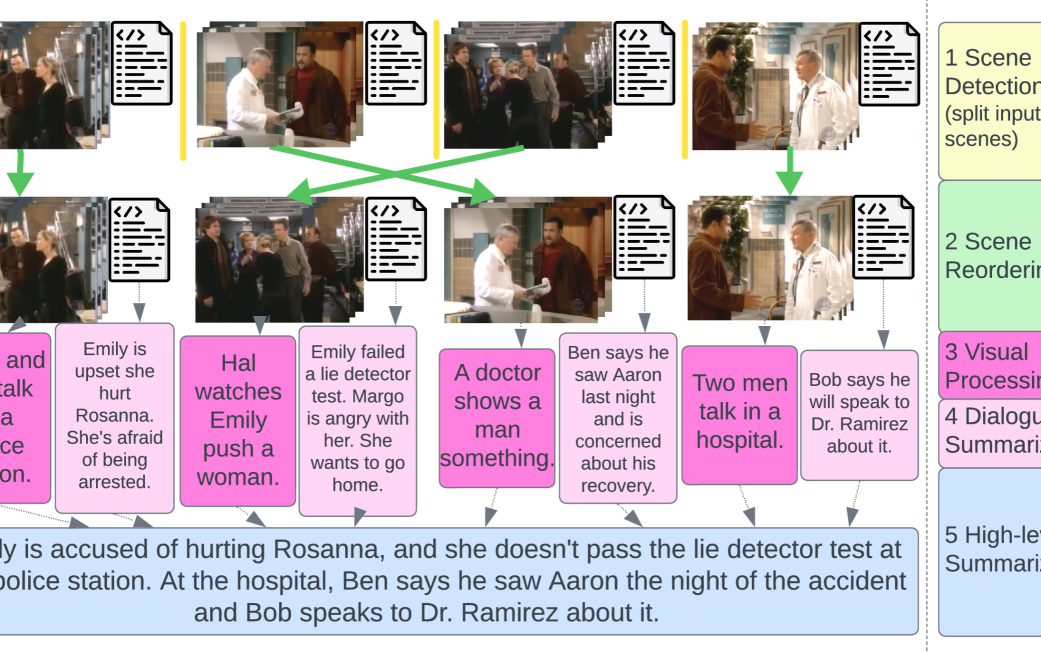
In this paper we address the task of summarizing television shows, which touches key areas in AI research: complex reasoning, multiple modalities, and long narratives. We present a modular approach where separate components perform specialized sub-tasks which we argue affords greater flexibility compared to end-to-end methods. Our modules involve detecting scene boundaries, reordering scenes so as to minimize the number of cuts between different events, converting visual information to text, summarizing the dialogue in each scene, and fusing the scene summaries into a final summary for the entire episode. We also present a new metric, PREFS (Precision and Recall Evaluation of Summary FactS), to measure both precision and recall of generated summaries, which we decompose into atomic facts. Tested on the recently released SummScreen3D dataset Papalampidi and Lapata (2023), our method produces higher quality summaries than comparison models, as measured with ROUGE and our new fact-based metric.
6/17/2024

A Systematic Survey of Text Summarization: From Statistical Methods to Large Language Models
Haopeng Zhang, Philip S. Yu, Jiawei Zhang
0
0
Text summarization research has undergone several significant transformations with the advent of deep neural networks, pre-trained language models (PLMs), and recent large language models (LLMs). This survey thus provides a comprehensive review of the research progress and evolution in text summarization through the lens of these paradigm shifts. It is organized into two main parts: (1) a detailed overview of datasets, evaluation metrics, and summarization methods before the LLM era, encompassing traditional statistical methods, deep learning approaches, and PLM fine-tuning techniques, and (2) the first detailed examination of recent advancements in benchmarking, modeling, and evaluating summarization in the LLM era. By synthesizing existing literature and presenting a cohesive overview, this survey also discusses research trends, open challenges, and proposes promising research directions in summarization, aiming to guide researchers through the evolving landscape of summarization research.
6/18/2024
Characterizing Multimodal Long-form Summarization: A Case Study on Financial Reports
Tianyu Cao, Natraj Raman, Danial Dervovic, Chenhao Tan
0
0
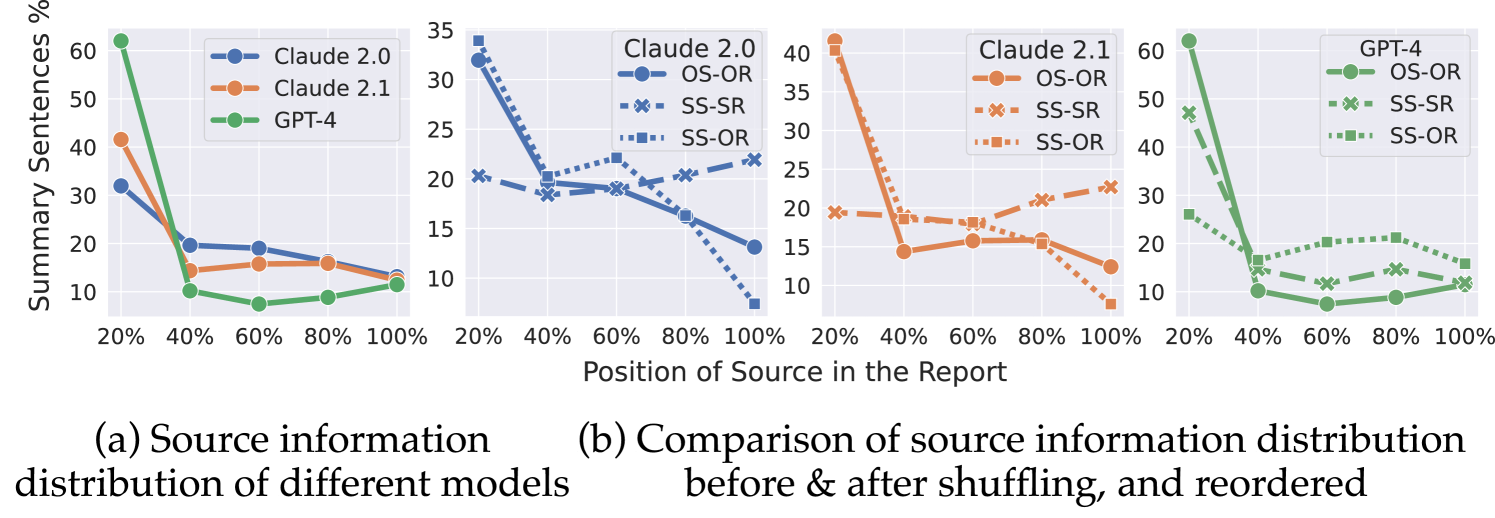
As large language models (LLMs) expand the power of natural language processing to handle long inputs, rigorous and systematic analyses are necessary to understand their abilities and behavior. A salient application is summarization, due to its ubiquity and controversy (e.g., researchers have declared the death of summarization). In this paper, we use financial report summarization as a case study because financial reports not only are long but also use numbers and tables extensively. We propose a computational framework for characterizing multimodal long-form summarization and investigate the behavior of Claude 2.0/2.1, GPT-4/3.5, and Command. We find that GPT-3.5 and Command fail to perform this summarization task meaningfully. For Claude 2 and GPT-4, we analyze the extractiveness of the summary and identify a position bias in LLMs. This position bias disappears after shuffling the input for Claude, which suggests that Claude has the ability to recognize important information. We also conduct a comprehensive investigation on the use of numeric data in LLM-generated summaries and offer a taxonomy of numeric hallucination. We employ prompt engineering to improve GPT-4's use of numbers with limited success. Overall, our analyses highlight the strong capability of Claude 2 in handling long multimodal inputs compared to GPT-4.
5/9/2024
🧠
Which Information Matters? Dissecting Human-written Multi-document Summaries with Partial Information Decomposition
Laura Mascarell, Yan L'Homme, Majed El Helou
0
0
Understanding the nature of high-quality summaries is crucial to further improve the performance of multi-document summarization. We propose an approach to characterize human-written summaries using partial information decomposition, which decomposes the mutual information provided by all source documents into union, redundancy, synergy, and unique information. Our empirical analysis on different MDS datasets shows that there is a direct dependency between the number of sources and their contribution to the summary.
5/24/2024