Improving Machine Translation with Large Language Models: A Preliminary Study with Cooperative Decoding

0
💬
Sign in to get full access
Overview
- Contemporary translation engines based on the encoder-decoder framework have made significant progress, but the emergence of Large Language Models (LLMs) has disrupted their position.
- The paper aims to assess the strengths and limitations of various commercial NMT systems and MT-oriented LLMs, and to propose a solution that combines their strengths.
- The researchers introduce Cooperative Decoding (CoDec), which uses NMT systems as a pre-translation model and MT-oriented LLMs as a supplemental solution to handle complex scenarios.
Plain English Explanation
Machine translation, the process of automatically translating text from one language to another, has come a long way in recent years. Contemporary translation engines based on the encoder-decoder framework, a type of artificial intelligence (AI) model, have made significant advancements. These models take the text in one language, encode it into a numerical representation, and then decode it into the target language.
However, a new type of AI model, called Large Language Models (LLMs), has emerged and disrupted the position of traditional translation engines. LLMs are trained on vast amounts of text data and can understand and generate human-like language. Researchers believe these models have the potential to achieve even better translation quality than the traditional encoder-decoder models.
To understand the strengths and limitations of both approaches, the researchers conducted a comprehensive analysis. They found that neither traditional translation engines nor LLMs alone can effectively address all the issues in machine translation. However, the researchers discovered that LLMs show promise as a complementary solution to the traditional models.
Building on this insight, the researchers propose a new approach called Cooperative Decoding (CoDec). In this approach, the traditional translation engine is used as a pre-translation model, and the LLM is used as a supplemental solution to handle more complex scenarios that the traditional model cannot handle on its own. The researchers tested this approach on various language translation tasks and found it to be effective and efficient, making it a promising solution for the future of machine translation.
Technical Explanation
The paper begins by acknowledging the significant progress made by contemporary translation engines based on the encoder-decoder framework, but also recognizes the disruptive potential of Large Language Models (LLMs).
To understand the strengths and limitations of both approaches, the researchers conduct a comprehensive analysis of various commercial Neural Machine Translation (NMT) systems and MT-oriented LLMs. Their findings indicate that neither NMT nor MT-oriented LLMs alone can effectively address all the translation issues, but MT-oriented LLMs show promise as a complementary solution to NMT systems.
Building upon these insights, the researchers propose Cooperative Decoding (CoDec), a new approach that treats NMT systems as a pre-translation model and MT-oriented LLMs as a supplemental solution to handle complex scenarios beyond the capability of NMT alone. The CoDec approach involves using the NMT system to generate an initial translation, and then leveraging the MT-oriented LLM to refine and improve the translation quality.
The researchers evaluate the effectiveness and efficiency of CoDec using the WMT22 test sets and a newly collected test set WebCrawl. The results demonstrate the potential of CoDec as a robust solution for combining NMT systems with MT-oriented LLMs in the field of machine translation.
Critical Analysis
The paper presents a thoughtful and well-designed study that explores the strengths and limitations of both NMT systems and MT-oriented LLMs, and proposes a novel Cooperative Decoding (CoDec) approach to leverage the strengths of both.
One potential limitation of the research is the reliance on a newly collected test set, WebCrawl, which may not be fully representative of real-world translation challenges. It would be valuable to further validate the CoDec approach on a more diverse range of translation tasks and datasets.
Additionally, the paper does not provide a deep analysis of the specific scenarios where CoDec excels or falls short compared to NMT or LLM-only approaches. A more nuanced understanding of the use cases and limitations of CoDec would be helpful for researchers and practitioners to assess its practical applicability.
Overall, the paper presents a promising direction for improving machine translation quality by combining the strengths of NMT systems and MT-oriented LLMs. The Cooperative Decoding (CoDec) approach warrants further exploration and validation to fully realize its potential in the field of machine translation.
Conclusion
The paper explores the impact of Large Language Models (LLMs) on the field of machine translation, which has traditionally been dominated by encoder-decoder-based contemporary translation engines.
Through a comprehensive analysis, the researchers found that neither NMT systems nor MT-oriented LLMs alone can effectively address all the challenges in machine translation. However, they propose a novel Cooperative Decoding (CoDec) approach that combines the strengths of both, using NMT as a pre-translation model and LLMs as a supplemental solution for more complex scenarios.
The experimental results demonstrate the effectiveness and efficiency of CoDec, highlighting its potential as a robust solution for enhancing machine translation quality by leveraging the complementary capabilities of NMT systems and MT-oriented LLMs. This work paves the way for further advancements in the field of machine translation, where the synergistic integration of different AI models can lead to significant improvements in translation accuracy and versatility.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Improving Machine Translation with Large Language Models: A Preliminary Study with Cooperative Decoding
Jiali Zeng, Fandong Meng, Yongjing Yin, Jie Zhou
Contemporary translation engines based on the encoder-decoder framework have made significant strides in development. However, the emergence of Large Language Models (LLMs) has disrupted their position by presenting the potential for achieving superior translation quality. To uncover the circumstances in which LLMs excel and explore how their strengths can be harnessed to enhance translation quality, we first conduct a comprehensive analysis to assess the strengths and limitations of various commercial NMT systems and MT-oriented LLMs. Our findings indicate that neither NMT nor MT-oriented LLMs alone can effectively address all the translation issues, but MT-oriented LLMs show promise as a complementary solution to NMT systems. Building upon these insights, we propose Cooperative Decoding (CoDec), which treats NMT systems as a pretranslation model and MT-oriented LLMs as a supplemental solution to handle complex scenarios beyond the capability of NMT alone. Experimental results on the WMT22 test sets and a newly collected test set WebCrawl demonstrate the effectiveness and efficiency of CoDec, highlighting its potential as a robust solution for combining NMT systems with MT-oriented LLMs in the field of machine translation.
Read more5/28/2024

0
GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
Read more5/17/2024
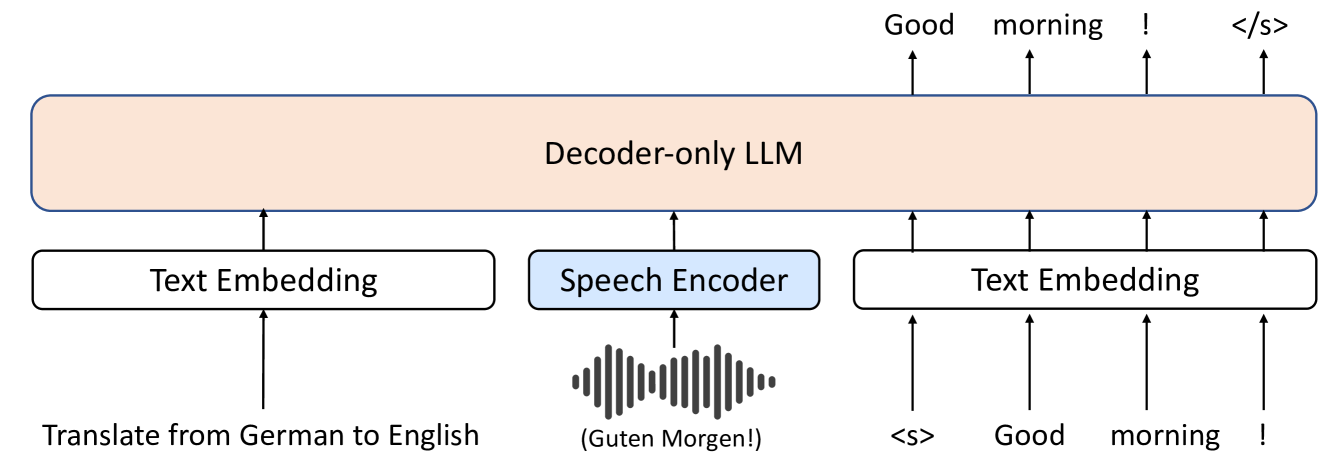
0
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
Read more7/4/2024
💬
0
Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis
Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, Lei Li
Large language models (LLMs) have demonstrated remarkable potential in handling multilingual machine translation (MMT). In this paper, we systematically investigate the advantages and challenges of LLMs for MMT by answering two questions: 1) How well do LLMs perform in translating massive languages? 2) Which factors affect LLMs' performance in translation? We thoroughly evaluate eight popular LLMs, including ChatGPT and GPT-4. Our empirical results show that translation capabilities of LLMs are continually involving. GPT-4 has beat the strong supervised baseline NLLB in 40.91% of translation directions but still faces a large gap towards the commercial translation system like Google Translate, especially on low-resource languages. Through further analysis, we discover that LLMs exhibit new working patterns when used for MMT. First, LLM can acquire translation ability in a resource-efficient way and generate moderate translation even on zero-resource languages. Second, instruction semantics can surprisingly be ignored when given in-context exemplars. Third, cross-lingual exemplars can provide better task guidance for low-resource translation than exemplars in the same language pairs. Code will be released at: https://github.com/NJUNLP/MMT-LLM.
Read more6/17/2024