SoftMCL: Soft Momentum Contrastive Learning for Fine-grained Sentiment-aware Pre-training

0
📈
Sign in to get full access
Overview
- Current language models can capture general language understanding, but struggle to distinguish the emotional impact of words in specific contexts.
- Recent works have explored using contrastive learning to help language models learn affective information.
- However, these methods have limitations, such as being constrained by GPU memory and using overly simplistic sentiment labels.
Plain English Explanation
Language models trained on large amounts of text can generally understand the meaning of words and how they are used. However, they often fail to grasp the emotional impact that certain words can have in particular contexts. For example, the word "fire" could have very different emotional connotations if it's used to describe a cozy fireplace versus a chaotic house fire.
Researchers have tried to address this by using a technique called contrastive learning. The idea is to train the language model to not only understand the meaning of words, but also their emotional associations. This is done by having the model compare a word used in a positive context to the same word used in a negative context, and learn to differentiate between them.
But current contrastive learning approaches have a few issues. First, they are limited by the amount of GPU memory available, which restricts the number of negative examples the model can consider during training. Having more negative examples helps the model learn better emotional representations.
Additionally, most of these methods only use broad sentiment categories like "positive," "neutral," and "negative" as labels. This can cause all the emotional representations to get squished together, limiting the model's ability to learn nuanced emotional understanding.
Technical Explanation
The paper proposes a new approach called "Soft Momentum Contrastive Learning" (SoftMCL) to address these limitations. Instead of using simple sentiment labels, SoftMCL uses "valence ratings" as soft labels to provide more fine-grained supervision for the contrastive learning process. Valence ratings measure the emotional intensity of a word or sentence on a continuous scale, allowing the model to learn more subtle emotional associations.
Additionally, SoftMCL introduces a "momentum queue" to store and reuse negative examples, expanding the pool of contrastive samples beyond what can fit in GPU memory at once. This helps the model learn more robust emotional representations.
The SoftMCL approach is applied at both the word level and sentence level, further enhancing the model's ability to capture affective information. The researchers evaluated the effectiveness of SoftMCL on four different sentiment-related tasks, and found it outperformed other state-of-the-art methods.
Critical Analysis
The paper presents a compelling solution to the limitations of existing contrastive learning approaches for sentiment-aware language model pre-training. The use of soft valence ratings as labels, rather than hard sentiment categories, is a clever way to capture more nuanced emotional information.
However, the authors do not discuss the potential challenges in obtaining high-quality valence ratings at scale, which could be a practical limitation in applying this method. Additionally, the paper would benefit from a more in-depth analysis of the types of emotional representations learned by the SoftMCL model, and how they differ from those learned by simpler approaches.
It would also be interesting to see how SoftMCL performs on tasks that require a deeper understanding of emotional context, such as emotion recognition or customizing language model responses based on emotional context.
Conclusion
The SoftMCL approach proposed in this paper represents an important step forward in helping language models better understand the emotional impact of words and language. By using soft valence ratings as supervision and a momentum queue to expand the pool of negative samples, the model can learn more nuanced and robust emotional representations.
This could have significant implications for a wide range of applications, from better sentiment analysis to more empathetic and context-aware language generation. As the field of affective computing continues to advance, techniques like SoftMCL will be crucial in developing language models that can truly understand and respond to the emotional nuances of human communication.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
SoftMCL: Soft Momentum Contrastive Learning for Fine-grained Sentiment-aware Pre-training
Jin Wang, Liang-Chih Yu, Xuejie Zhang
The pre-training for language models captures general language understanding but fails to distinguish the affective impact of a particular context to a specific word. Recent works have sought to introduce contrastive learning (CL) for sentiment-aware pre-training in acquiring affective information. Nevertheless, these methods present two significant limitations. First, the compatibility of the GPU memory often limits the number of negative samples, hindering the opportunities to learn good representations. In addition, using only a few sentiment polarities as hard labels, e.g., positive, neutral, and negative, to supervise CL will force all representations to converge to a few points, leading to the issue of latent space collapse. This study proposes a soft momentum contrastive learning (SoftMCL) for fine-grained sentiment-aware pre-training. Instead of hard labels, we introduce valence ratings as soft-label supervision for CL to fine-grained measure the sentiment similarities between samples. The proposed SoftMCL is conducted on both the word- and sentence-level to enhance the model's ability to learn affective information. A momentum queue was introduced to expand the contrastive samples, allowing storing and involving more negatives to overcome the limitations of hardware platforms. Extensive experiments were conducted on four different sentiment-related tasks, which demonstrates the effectiveness of the proposed SoftMCL method. The code and data of the proposed SoftMCL is available at: https://www.github.com/wangjin0818/SoftMCL/.
Read more5/6/2024
0
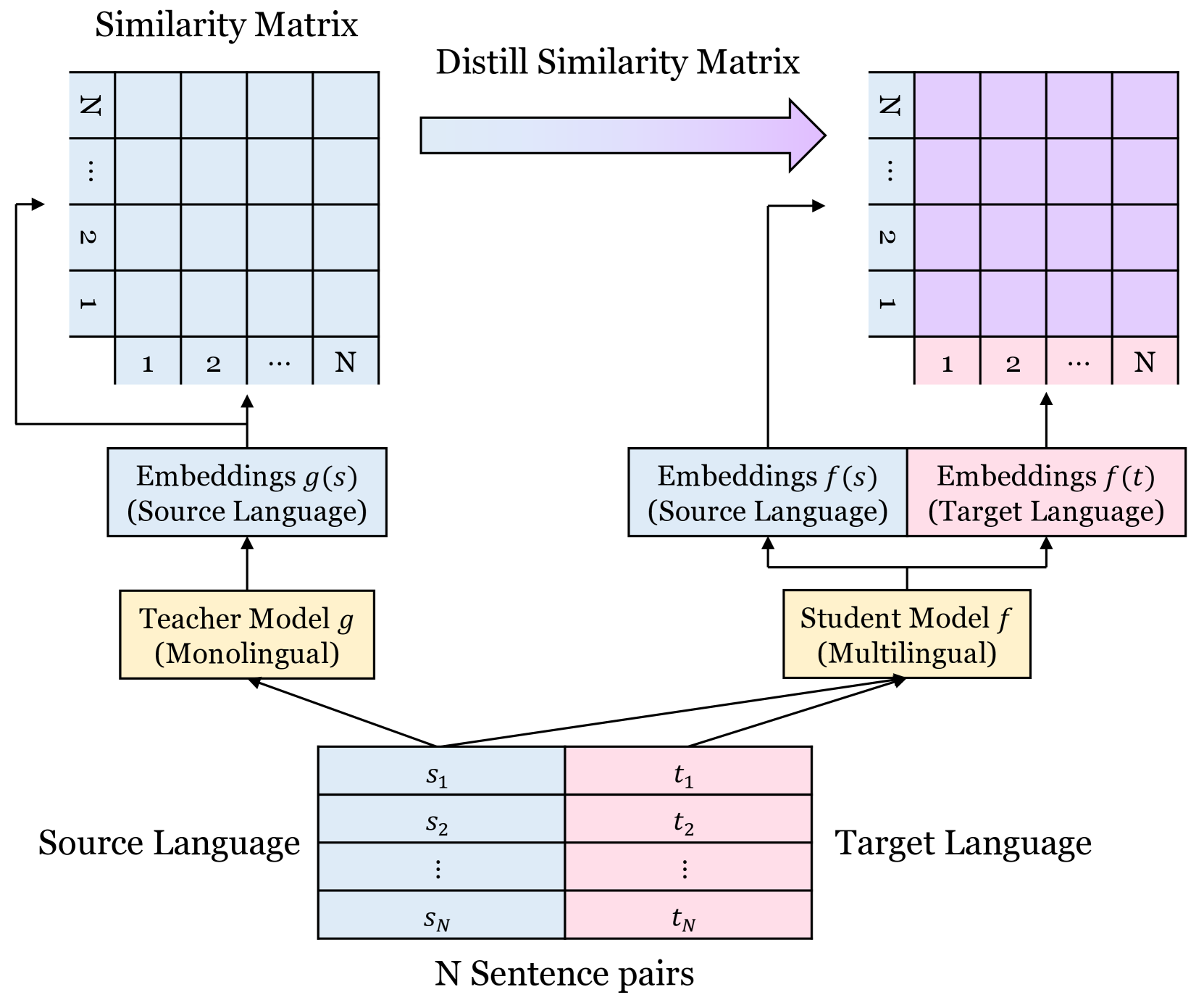
Improving Multi-lingual Alignment Through Soft Contrastive Learning
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Read more5/29/2024

0
Improving In-Context Learning with Prediction Feedback for Sentiment Analysis
Hongling Xu, Qianlong Wang, Yice Zhang, Min Yang, Xi Zeng, Bing Qin, Ruifeng Xu
Large language models (LLMs) have achieved promising results in sentiment analysis through the in-context learning (ICL) paradigm. However, their ability to distinguish subtle sentiments still remains a challenge. Inspired by the human ability to adjust understanding via feedback, this paper enhances ICL by incorporating prior predictions and feedback, aiming to rectify sentiment misinterpretation of LLMs. Specifically, the proposed framework consists of three steps: (1) acquiring prior predictions of LLMs, (2) devising predictive feedback based on correctness, and (3) leveraging a feedback-driven prompt to refine sentiment understanding. Experimental results across nine sentiment analysis datasets demonstrate the superiority of our framework over conventional ICL methods, with an average F1 improvement of 5.95%.
Read more6/6/2024

0
Label-aware Hard Negative Sampling Strategies with Momentum Contrastive Learning for Implicit Hate Speech Detection
Jaehoon Kim, Seungwan Jin, Sohyun Park, Someen Park, Kyungsik Han
Detecting implicit hate speech that is not directly hateful remains a challenge. Recent research has attempted to detect implicit hate speech by applying contrastive learning to pre-trained language models such as BERT and RoBERTa, but the proposed models still do not have a significant advantage over cross-entropy loss-based learning. We found that contrastive learning based on randomly sampled batch data does not encourage the model to learn hard negative samples. In this work, we propose Label-aware Hard Negative sampling strategies (LAHN) that encourage the model to learn detailed features from hard negative samples, instead of naive negative samples in random batch, using momentum-integrated contrastive learning. LAHN outperforms the existing models for implicit hate speech detection both in- and cross-datasets. The code is available at https://github.com/Hanyang-HCC-Lab/LAHN
Read more6/13/2024