Improving Neural Topic Models with Wasserstein Knowledge Distillation
2303.15350
0
0
🧠
Abstract
Topic modeling is a dominant method for exploring document collections on the web and in digital libraries. Recent approaches to topic modeling use pretrained contextualized language models and variational autoencoders. However, large neural topic models have a considerable memory footprint. In this paper, we propose a knowledge distillation framework to compress a contextualized topic model without loss in topic quality. In particular, the proposed distillation objective is to minimize the cross-entropy of the soft labels produced by the teacher and the student models, as well as to minimize the squared 2-Wasserstein distance between the latent distributions learned by the two models. Experiments on two publicly available datasets show that the student trained with knowledge distillation achieves topic coherence much higher than that of the original student model, and even surpasses the teacher while containing far fewer parameters than the teacher's. The distilled model also outperforms several other competitive topic models on topic coherence.
Create account to get full access
Overview
- This paper explores a method to compress large neural topic models without losing topic quality.
- The proposed approach uses knowledge distillation to train a smaller "student" model to match the behavior of a larger "teacher" model.
- The distillation objective minimizes the cross-entropy between the teacher and student's soft outputs, as well as the distance between their latent distributions.
- Experiments show the distilled student model achieves higher topic coherence than the original student, and even outperforms the larger teacher model, while having far fewer parameters.
Plain English Explanation
Topic modeling is a popular technique for exploring and understanding document collections, such as web pages or digital library materials. Recent advancements in topic modeling have used powerful language models and variational autoencoders, but these large neural models require a lot of memory to run.
The researchers in this paper propose a way to "squeeze" a large, complex topic model into a smaller, more efficient model without losing the quality of the topics it identifies. They use a technique called knowledge distillation to train a compact "student" model to match the behavior of a larger "teacher" model.
The key idea is to have the student model learn not just the final topic assignments, but also the more nuanced "soft" probabilities the teacher model generates. This helps the student model capture the same underlying patterns and relationships in the data, even though it's a much simpler model.
The researchers find that the distilled student model not only performs better than the original student on evaluating topic quality, but it can even outperform the larger teacher model. This shows the power of knowledge distillation to extract the essential knowledge from a complex model and pack it into a more efficient form.
Technical Explanation
The paper presents a knowledge distillation framework to compress a large, pretrained contextualized topic model into a smaller, more memory-efficient student model. The proposed distillation objective has two components:
-
Minimizing the cross-entropy between the "soft" topic probability distributions produced by the teacher and student models. This encourages the student to mimic the teacher's fine-grained uncertainty about topic assignments.
-
Minimizing the squared 2-Wasserstein distance between the latent topic distributions learned by the teacher and student. This helps the student capture the same underlying topic representations as the teacher.
The researchers evaluate their approach on two public datasets, comparing the distilled student model to the original student as well as other competitive topic models. They find that the distilled student achieves significantly higher topic coherence than the original student, and even outperforms the larger teacher model, while containing far fewer parameters.
This demonstrates the effectiveness of knowledge distillation for compressing complex topic models without losing their ability to discover high-quality topics. The distilled model can therefore be deployed in memory-constrained settings like mobile devices or embedded systems, while still providing the benefits of advanced neural topic modeling.
Critical Analysis
The paper provides a well-designed study that rigorously evaluates the proposed knowledge distillation approach for topic modeling. The use of both cross-entropy and Wasserstein distance in the distillation objective is a thoughtful way to capture different aspects of the teacher's behavior.
One potential limitation is that the experiments only consider two datasets. Additional testing on a wider range of corpora would help further validate the generalizability of the findings. The authors also do not explore the impact of different hyperparameter settings or architectural choices for the student model.
While the results show the distilled student outperforming the teacher on topic coherence, it would be interesting to see how the models compare on other downstream tasks, such as document classification or information retrieval. This could provide a more holistic assessment of the student model's capabilities.
Additionally, the paper does not discuss the training time or inference speed of the distilled model compared to the teacher. These efficiency metrics would be important considerations for real-world deployments, especially in resource-constrained environments.
Overall, this is a well-executed study that demonstrates the potential of knowledge distillation to create compact, high-performing topic models. Further research exploring a wider range of applications and efficiency tradeoffs would be valuable.
Conclusion
This paper presents a novel knowledge distillation approach to compress large neural topic models while preserving topic quality. By training a smaller "student" model to match the behavior of a larger "teacher" model, the researchers are able to create a compact topic model that outperforms the original student and even the teacher itself on topic coherence.
The findings highlight the power of knowledge distillation to extract the essential knowledge from a complex model and transfer it to a more efficient form. This has important implications for deploying advanced topic modeling capabilities in memory-constrained settings, such as mobile devices or edge computing systems.
The research contributes to the growing body of work on model compression and knowledge distillation, demonstrating their applicability to the important task of topic modeling. As the volume of digital content continues to grow, tools like this that can efficiently explore and understand document collections will become increasingly valuable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024

MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
0
0
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
4/11/2024
💬
Sentence-Level or Token-Level? A Comprehensive Study on Knowledge Distillation
Jingxuan Wei, Linzhuang Sun, Yichong Leng, Xu Tan, Bihui Yu, Ruifeng Guo
0
0
Knowledge distillation, transferring knowledge from a teacher model to a student model, has emerged as a powerful technique in neural machine translation for compressing models or simplifying training targets. Knowledge distillation encompasses two primary methods: sentence-level distillation and token-level distillation. In sentence-level distillation, the student model is trained to align with the output of the teacher model, which can alleviate the training difficulty and give student model a comprehensive understanding of global structure. Differently, token-level distillation requires the student model to learn the output distribution of the teacher model, facilitating a more fine-grained transfer of knowledge. Studies have revealed divergent performances between sentence-level and token-level distillation across different scenarios, leading to the confusion on the empirical selection of knowledge distillation methods. In this study, we argue that token-level distillation, with its more complex objective (i.e., distribution), is better suited for ``simple'' scenarios, while sentence-level distillation excels in ``complex'' scenarios. To substantiate our hypothesis, we systematically analyze the performance of distillation methods by varying the model size of student models, the complexity of text, and the difficulty of decoding procedure. While our experimental results validate our hypothesis, defining the complexity level of a given scenario remains a challenging task. So we further introduce a novel hybrid method that combines token-level and sentence-level distillation through a gating mechanism, aiming to leverage the advantages of both individual methods. Experiments demonstrate that the hybrid method surpasses the performance of token-level or sentence-level distillation methods and the previous works by a margin, demonstrating the effectiveness of the proposed hybrid method.
4/24/2024
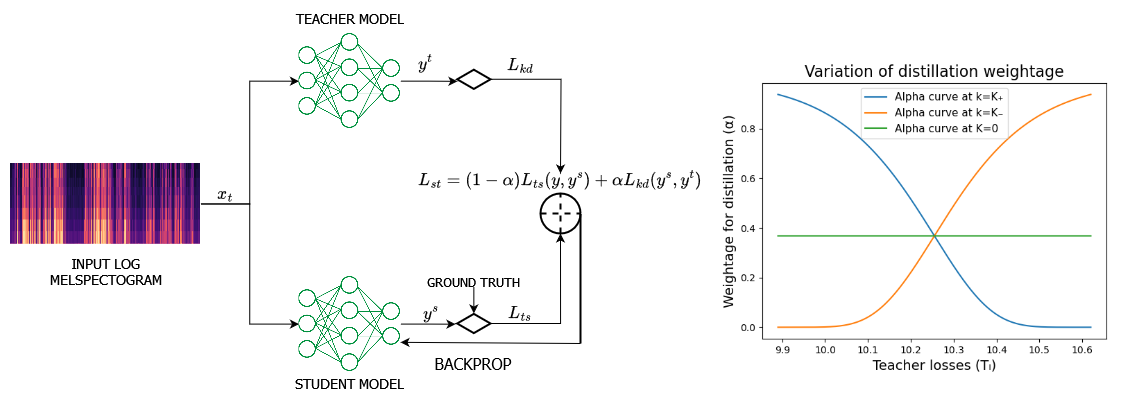
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
0
0
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
5/15/2024