Improving noisy student training for low-resource languages in End-to-End ASR using CycleGAN and inter-domain losses

0

Sign in to get full access
Overview
- The paper presents a novel approach to improve the performance of end-to-end automatic speech recognition (ASR) models for low-resource languages.
- The key ideas are to use a CycleGAN to generate high-quality noisy speech data from a high-resource language, and an inter-domain loss to bridge the gap between the generated and target language domains.
- The experiments show significant improvements in ASR accuracy for low-resource languages compared to baseline approaches.
Plain English Explanation
Automatic speech recognition (ASR) is the process of converting audio recordings into text. However, building accurate ASR models for low-resource languages (languages with limited training data) can be very challenging.
The researchers in this paper propose a new approach to address this problem. They use a CycleGAN, which is a type of machine learning model that can convert audio from one language into another. The researchers train the CycleGAN to take high-quality audio recordings in a high-resource language (like English) and convert them into noisy, low-quality audio that sounds like the low-resource language they want to improve.
They then use this generated noisy audio, along with the original high-quality audio, to train their end-to-end ASR model for the low-resource language. To help the model learn the differences between the generated and real low-resource language data, they also use an inter-domain loss function.
The key insight is that by combining the high-quality audio from a well-resourced language with the low-quality audio generated by the CycleGAN, the ASR model can learn to recognize speech in the low-resource language much more effectively than if it only had access to the limited real training data.
Technical Explanation
The paper proposes a new approach for improving end-to-end ASR performance in low-resource language scenarios. The key components are:
-
CycleGAN for Noisy Speech Generation: The researchers use a CycleGAN to convert high-quality speech in a high-resource language (e.g., English) into noisy speech that sounds like the target low-resource language. This generated noisy speech is then used to augment the limited training data for the low-resource language.
-
Inter-Domain Loss: To help the ASR model learn the differences between the generated noisy speech and the real low-resource language data, the researchers introduce an inter-domain loss function. This loss encourages the model to capture the distinctive characteristics of the low-resource language domain.
-
End-to-End ASR Training: The researchers train an end-to-end ASR model using a combination of the limited real low-resource language data and the noisy speech generated by the CycleGAN, along with the inter-domain loss.
The experiments show that this approach significantly improves ASR performance on low-resource languages compared to baseline methods that only use the limited real training data. The researchers attribute the success to the CycleGAN's ability to generate high-quality noisy speech samples and the inter-domain loss's effectiveness in helping the ASR model learn the distinctive features of the low-resource language.
Critical Analysis
The paper presents a promising approach to address the challenge of building accurate ASR models for low-resource languages. The key strengths are:
- The CycleGAN-based data augmentation technique is an innovative way to generate realistic-sounding noisy speech data, which can significantly expand the limited training data available for low-resource languages.
- The inter-domain loss function helps the ASR model learn the unique characteristics of the low-resource language, which is crucial for achieving good performance.
- The end-to-end training approach allows the model to jointly optimize the speech recognition and domain adaptation components, leading to improved overall performance.
However, the paper also has some limitations and potential areas for further research:
- The evaluation is limited to a single low-resource language (Javanese). It would be valuable to see how the approach generalizes to a wider range of low-resource languages with different characteristics.
- The paper does not discuss the computational and training complexity of the proposed method, which could be an important practical consideration for real-world deployment.
- The researchers could explore ways to further improve the CycleGAN's ability to generate high-quality noisy speech, perhaps by incorporating additional domain-specific information or using more advanced GAN architectures.
- It would be interesting to see how this approach could be combined with other techniques for improving low-resource ASR, such as sequential editing or anti-spoofing countermeasures.
Overall, the paper presents a compelling and well-executed approach to a important problem in the field of end-to-end ASR. The proposed techniques could significantly advance the state of the art in low-resource language ASR and have valuable real-world applications.
Conclusion
This paper introduces a novel approach to improve end-to-end automatic speech recognition (ASR) for low-resource languages. The key ideas are to use a CycleGAN to generate high-quality noisy speech data from a high-resource language, and an inter-domain loss to help the ASR model learn the distinctive characteristics of the low-resource language.
The experimental results show that this approach can significantly boost ASR performance for low-resource languages compared to baseline methods. The paper's innovative data augmentation and domain adaptation techniques could have a significant impact on improving accessibility and inclusivity of speech recognition systems, particularly for underserved languages and communities.
While the paper has some limitations, it presents a compelling and well-executed approach that opens up promising directions for future research in the field of low-resource language ASR.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving noisy student training for low-resource languages in End-to-End ASR using CycleGAN and inter-domain losses
Chia-Yu Li, Ngoc Thang Vu
Training a semi-supervised end-to-end speech recognition system using noisy student training has significantly improved performance. However, this approach requires a substantial amount of paired speech-text and unlabeled speech, which is costly for low-resource languages. Therefore, this paper considers a more extreme case of semi-supervised end-to-end automatic speech recognition where there are limited paired speech-text, unlabeled speech (less than five hours), and abundant external text. Firstly, we observe improved performance by training the model using our previous work on semi-supervised learning CycleGAN and inter-domain losses solely with external text. Secondly, we enhance CycleGAN and inter-domain losses by incorporating automatic hyperparameter tuning, calling it enhanced CycleGAN inter-domain losses. Thirdly, we integrate it into the noisy student training approach pipeline for low-resource scenarios. Our experimental results, conducted on six non-English languages from Voxforge and Common Voice, show a 20% word error rate reduction compared to the baseline teacher model and a 10% word error rate reduction compared to the baseline best student model, highlighting the significant improvements achieved through our proposed method.
Read more8/1/2024

0
Effective Noise-aware Data Simulation for Domain-adaptive Speech Enhancement Leveraging Dynamic Stochastic Perturbation
Chien-Chun Wang, Li-Wei Chen, Hung-Shin Lee, Berlin Chen, Hsin-Min Wang
Cross-domain speech enhancement (SE) is often faced with severe challenges due to the scarcity of noise and background information in an unseen target domain, leading to a mismatch between training and test conditions. This study puts forward a novel data simulation method to address this issue, leveraging noise-extractive techniques and generative adversarial networks (GANs) with only limited target noisy speech data. Notably, our method employs a noise encoder to extract noise embeddings from target-domain data. These embeddings aptly guide the generator to synthesize utterances acoustically fitted to the target domain while authentically preserving the phonetic content of the input clean speech. Furthermore, we introduce the notion of dynamic stochastic perturbation, which can inject controlled perturbations into the noise embeddings during inference, thereby enabling the model to generalize well to unseen noise conditions. Experiments on the VoiceBank-DEMAND benchmark dataset demonstrate that our domain-adaptive SE method outperforms an existing strong baseline based on data simulation.
Read more9/4/2024

0
Self-Train Before You Transcribe
Robert Flynn, Anton Ragni
When there is a mismatch between the training and test domains, current speech recognition systems show significant performance degradation. Self-training methods, such as noisy student teacher training, can help address this and enable the adaptation of models under such domain shifts. However, self-training typically requires a collection of unlabelled target domain data. For settings where this is not practical, we investigate the benefit of performing noisy student teacher training on recordings in the test set as a test-time adaptation approach. Similarly to the dynamic evaluation approach in language modelling, this enables the transfer of information across utterance boundaries and functions as a method of domain adaptation. A range of in-domain and out-of-domain datasets are used for experiments demonstrating large relative gains of up to 32.2%. Interestingly, our method showed larger gains than the typical self-training setup that utilises separate adaptation data.
Read more6/21/2024
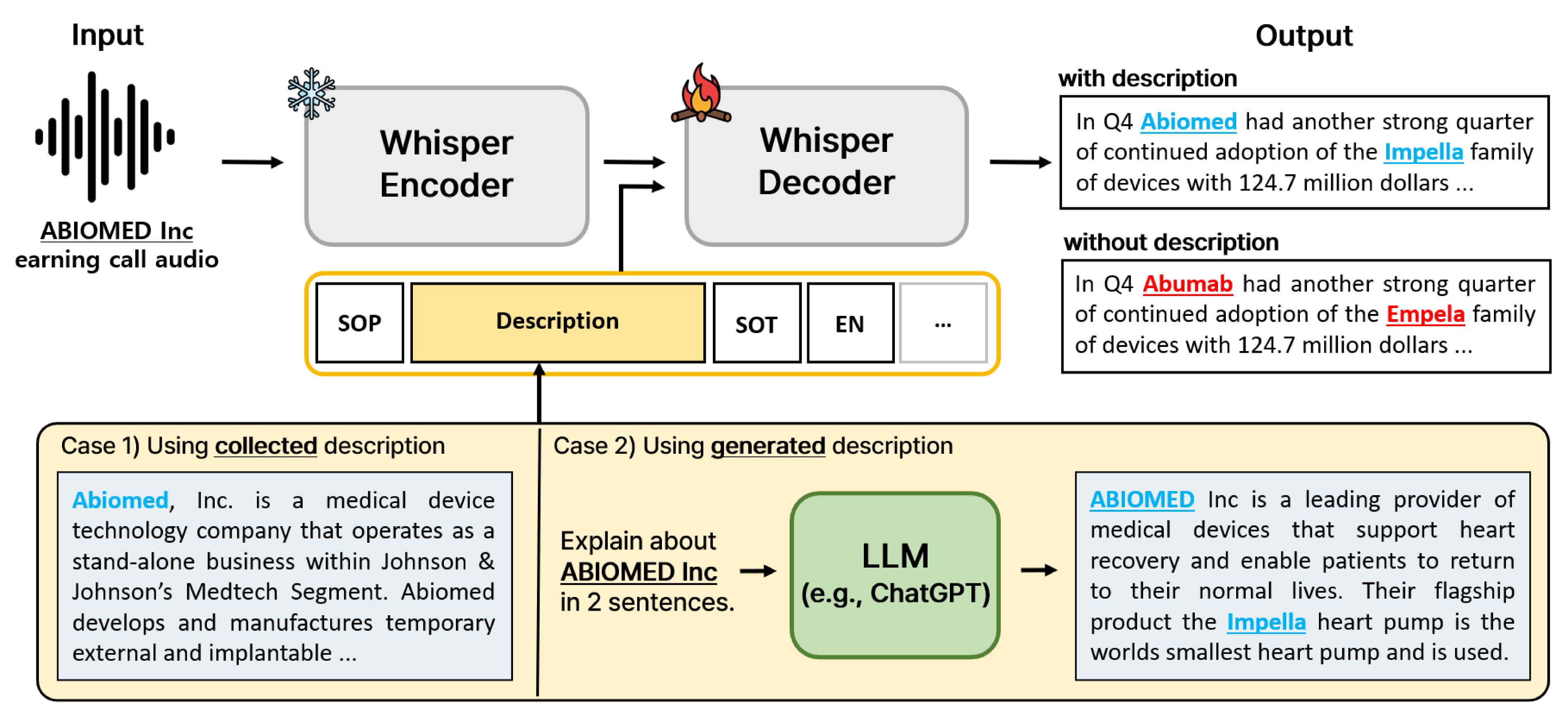
0
Improving Domain-Specific ASR with LLM-Generated Contextual Descriptions
Jiwon Suh, Injae Na, Woohwan Jung
End-to-end automatic speech recognition (E2E ASR) systems have significantly improved speech recognition through training on extensive datasets. Despite these advancements, they still struggle to accurately recognize domain specific words, such as proper nouns and technical terminologies. To address this problem, we propose a method to utilize the state-of-the-art Whisper without modifying its architecture, preserving its generalization performance while enabling it to leverage descriptions effectively. Moreover, we propose two additional training techniques to improve the domain specific ASR: decoder fine-tuning, and context perturbation. We also propose a method to use a Large Language Model (LLM) to generate descriptions with simple metadata, when descriptions are unavailable. Our experiments demonstrate that proposed methods notably enhance domain-specific ASR accuracy on real-life datasets, with LLM-generated descriptions outperforming human-crafted ones in effectiveness.
Read more7/26/2024