Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning

0
Sign in to get full access
Overview
- The paper proposes improvements to retrieval-augmented text-to-SQL systems, which use a retrieval step to find relevant database schema information before generating SQL queries.
- The key innovations are an AST-based ranking approach to better match the retrieved schema elements to the input text, and a schema pruning technique to reduce the search space.
- The proposed methods are evaluated on the SQL-to-schema and STAR-schema benchmarks, showing performance improvements over existing retrieval-augmented approaches.
Plain English Explanation
The paper focuses on improving a type of AI system that translates natural language questions into SQL queries to be executed on database tables. These systems first retrieve relevant information about the database schema (the structure and organization of the tables and columns) before generating the SQL query.
The key innovations are:
-
AST-based ranking: The system ranks the relevance of retrieved schema elements (like table and column names) to the input question by analyzing the structure of the SQL queries, rather than just looking at keyword matches. This helps it better understand how the schema elements fit with the semantics of the question.
-
Schema pruning: The system prunes (removes) irrelevant parts of the database schema, reducing the search space that the query generation model has to consider. This makes the overall process more efficient.
These improvements are evaluated on benchmark datasets, showing that they outperform previous retrieval-augmented text-to-SQL systems. The goal is to make these systems more accurate and practical for real-world applications that require translating natural language into database queries.
Technical Explanation
The paper proposes two key innovations to improve retrieval-augmented text-to-SQL systems:
-
AST-based ranking: The system ranks the relevance of retrieved schema elements (tables, columns, etc.) by analyzing the Abstract Syntax Tree (AST) of the candidate SQL queries. This allows it to better understand how the schema elements fit with the semantic structure of the input question, beyond just keyword matching. The AST-based ranking is integrated into the retrieval and ranking module of the system.
-
Schema pruning: The system prunes irrelevant parts of the database schema before generating the SQL query. This reduces the search space that the query generation model has to consider, making the overall process more efficient. The pruning is done by analyzing the structure of the SQL queries generated for the training data, and identifying schema elements that are consistently unused.
The proposed methods are evaluated on the SQL-to-schema and STAR-schema benchmarks, which test the ability to translate natural language questions into SQL queries. The results show that the AST-based ranking and schema pruning techniques improve performance over existing retrieval-augmented approaches.
Critical Analysis
The paper presents a thoughtful approach to improving retrieval-augmented text-to-SQL systems, addressing key limitations of previous work. The AST-based ranking technique is a novel contribution that goes beyond simple keyword matching to better understand the semantic fit between the retrieved schema elements and the input question.
However, the paper does not delve deeply into the limitations of the proposed methods. For example, the schema pruning technique relies on analyzing the training data, which may not generalize well to unseen databases or questions. Additionally, the paper does not discuss how the system would handle edge cases, such as ambiguous or underspecified natural language questions.
Furthermore, the evaluation is limited to the SQL-to-schema and STAR-schema benchmarks, which may not be representative of real-world text-to-SQL tasks. It would be valuable to see the system tested on a broader range of databases and question types to better understand its practical applicability.
Despite these limitations, the paper presents a promising direction for improving the performance and efficiency of retrieval-augmented text-to-SQL systems, which are an important building block for enabling natural language access to structured data. Further research in this area, addressing the limitations mentioned, could lead to significant advancements in the field.
Conclusion
The paper proposes two key innovations to improve retrieval-augmented text-to-SQL systems: an AST-based ranking approach to better match retrieved schema elements to the input text, and a schema pruning technique to reduce the search space. These methods are evaluated on benchmark datasets, showing performance improvements over existing approaches.
The work contributes to the broader goal of enabling natural language access to structured data, which is an important capability for a wide range of applications. While the paper has some limitations, it presents a valuable step forward in this research direction and suggests promising avenues for further exploration and refinement of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning
Zhili Shen, Pavlos Vougiouklis, Chenxin Diao, Kaustubh Vyas, Yuanyi Ji, Jeff Z. Pan
We focus on Text-to-SQL semantic parsing from the perspective of Large Language Models. Motivated by challenges related to the size of commercial database schemata and the deployability of business intelligence solutions, we propose an approach that dynamically retrieves input database information and uses abstract syntax trees to select few-shot examples for in-context learning. Furthermore, we investigate the extent to which an in-parallel semantic parser can be leveraged for generating $textit{approximated}$ versions of the expected SQL queries, to support our retrieval. We take this approach to the extreme--we adapt a model consisting of less than $500$M parameters, to act as an extremely efficient approximator, enhancing it with the ability to process schemata in a parallelised manner. We apply our approach to monolingual and cross-lingual benchmarks for semantic parsing, showing improvements over state-of-the-art baselines. Comprehensive experiments highlight the contribution of modules involved in this retrieval-augmented generation setting, revealing interesting directions for future work.
Read more7/4/2024

0
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, Amin Saberi
Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
Read more6/28/2024
0
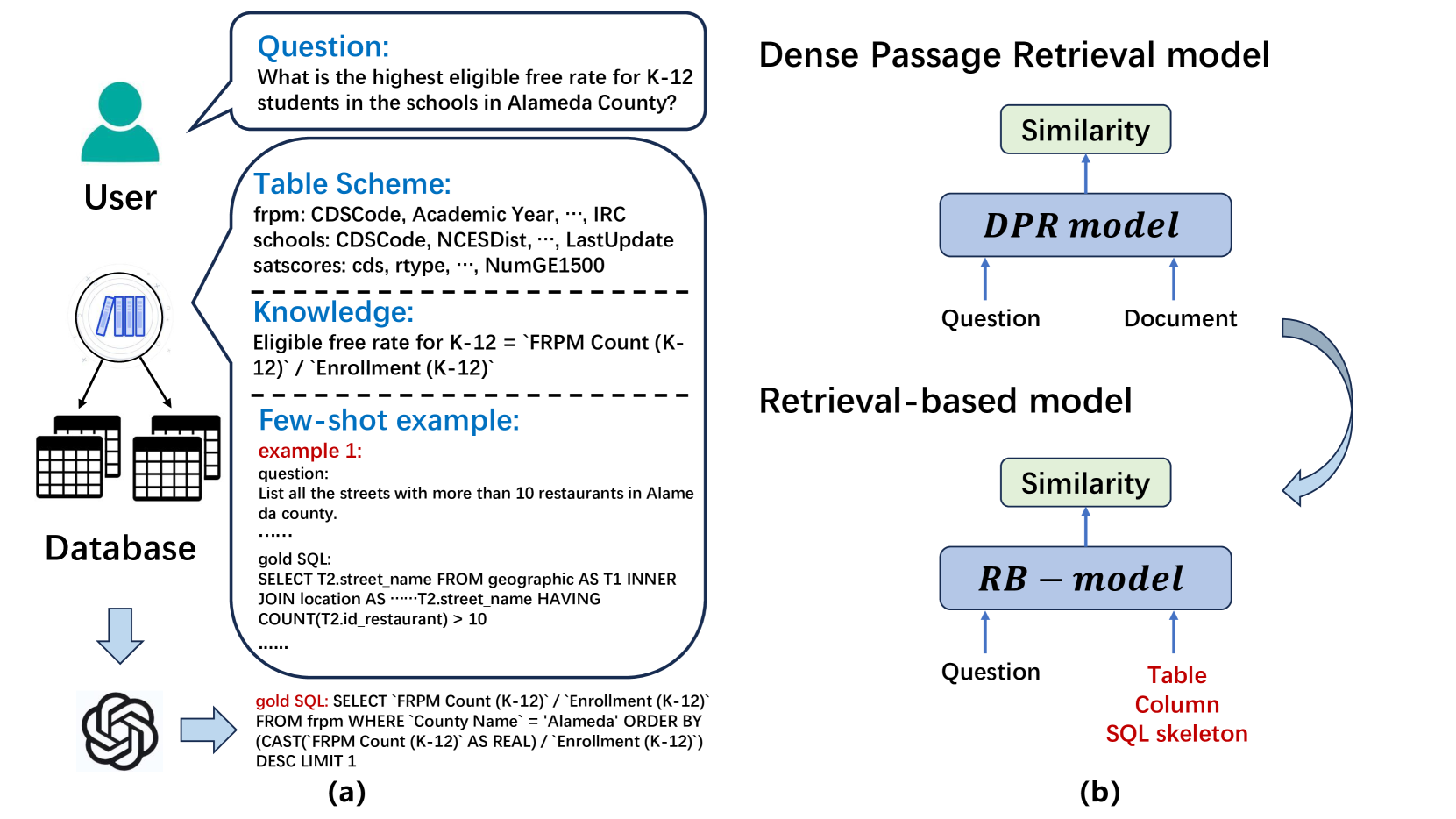
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024

0
Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models
Guanming Xiong, Junwei Bao, Hongfei Jiang, Yang Song, Wen Zhao
This study explores text-to-SQL parsing by leveraging the powerful reasoning capabilities of large language models (LLMs). Despite recent advancements, existing LLM-based methods have not adequately addressed scalability, leading to inefficiencies when processing wide tables. Furthermore, current interaction-based approaches either lack a step-by-step, interpretable SQL generation process or fail to provide an efficient and universally applicable interaction design. To address these challenges, we introduce Interactive-T2S, a framework that generates SQL queries through direct interactions with databases. This framework includes four general tools that facilitate proactive and efficient information retrieval by the LLM. Additionally, we have developed detailed exemplars to demonstrate the step-wise reasoning processes within our framework. Our experiments on the BIRD-Dev dataset, employing a setting without oracle knowledge, reveal that our method achieves state-of-the-art results with only two exemplars, underscoring the effectiveness and robustness of our framework.
Read more8/22/2024