Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models

0

Sign in to get full access
Overview
- The paper presents "Interactive-T2S", a system that enables multi-turn interactions for text-to-SQL (T2S) tasks using large language models (LLMs).
- The system allows users to iteratively refine their SQL queries through natural language conversations, leading to more accurate and useful results.
- The authors explore different approaches for incorporating context and history in the multi-turn interaction, and evaluate the performance of their system on existing T2S benchmarks.
Plain English Explanation
The paper introduces a new system called "Interactive-T2S" that helps people work with databases using natural language. Normally, when someone wants to get information from a database, they have to write complex SQL queries. With Interactive-T2S, they can instead have a conversation with the system, asking questions and refining their requests over multiple rounds.
This is useful because it allows people to gradually build up their SQL query, rather than having to get it right on the first try. The system uses large language models, which are AI models trained on a vast amount of text data, to understand the user's natural language requests and translate them into the appropriate SQL queries.
The researchers explored different ways of incorporating the conversation context and history into the system, to help it better understand the user's intent and provide more useful results over time. They evaluated the performance of their system on existing benchmarks for text-to-SQL tasks, and found that it outperformed other approaches.
Technical Explanation
The Approach section describes the key components of the Interactive-T2S system:
- Context Modeling: The system maintains a context representation that summarizes the conversation history, which is used to inform the generation of the SQL query.
- SQL Query Generation: The system uses a large language model to generate the SQL query based on the user's natural language input and the conversation context.
- Result Presentation: The system presents the results of the SQL query execution back to the user, and solicits feedback to guide the next round of interaction.
The authors experiment with different approaches for encoding the conversation context, including concatenating the user's current input with the previous inputs, and using a separate context encoder module.
The Experiments section details the evaluation of the Interactive-T2S system on text-to-SQL benchmarks like Spider and SParC. The results show that the system outperforms other state-of-the-art approaches, particularly in multi-turn scenarios where the conversational context is important.
Critical Analysis
The paper presents a compelling approach for enabling more natural and interactive text-to-SQL interfaces using large language models. Some potential limitations and areas for further research include:
- The system is evaluated on existing text-to-SQL benchmarks, which may not fully capture the nuances of real-world multi-turn interactions. Further user studies would be helpful to understand the system's performance in more realistic settings.
- The authors mention that the system's performance can degrade over long conversations, as the context representation may become too complex. Techniques for more effectively summarizing and maintaining the conversation context could be an area for improvement.
- The current system assumes the user's intent can be accurately captured in a single SQL query. In practice, users may have more complex information needs that require the composition of multiple queries or the consideration of additional data sources.
Overall, the Interactive-T2S system represents an important step forward in making database interfaces more accessible and user-friendly through the use of large language models and multi-turn interactions.
Conclusion
The Interactive-T2S paper presents a novel approach for enabling more natural and interactive text-to-SQL interfaces using large language models. By allowing users to refine their requests through multi-turn conversations, the system can generate more accurate and useful SQL queries to retrieve information from databases.
The authors' experiments demonstrate the effectiveness of their approach on existing text-to-SQL benchmarks, particularly in scenarios where the conversational context is important. While the system has some limitations, it represents an important step towards making database interfaces more accessible and user-friendly for a wide range of users.
The research in this paper could have significant implications for the development of next-generation database interfaces, as well as the broader field of natural language interaction with complex information systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Interactive-T2S: Multi-Turn Interactions for Text-to-SQL with Large Language Models
Guanming Xiong, Junwei Bao, Hongfei Jiang, Yang Song, Wen Zhao
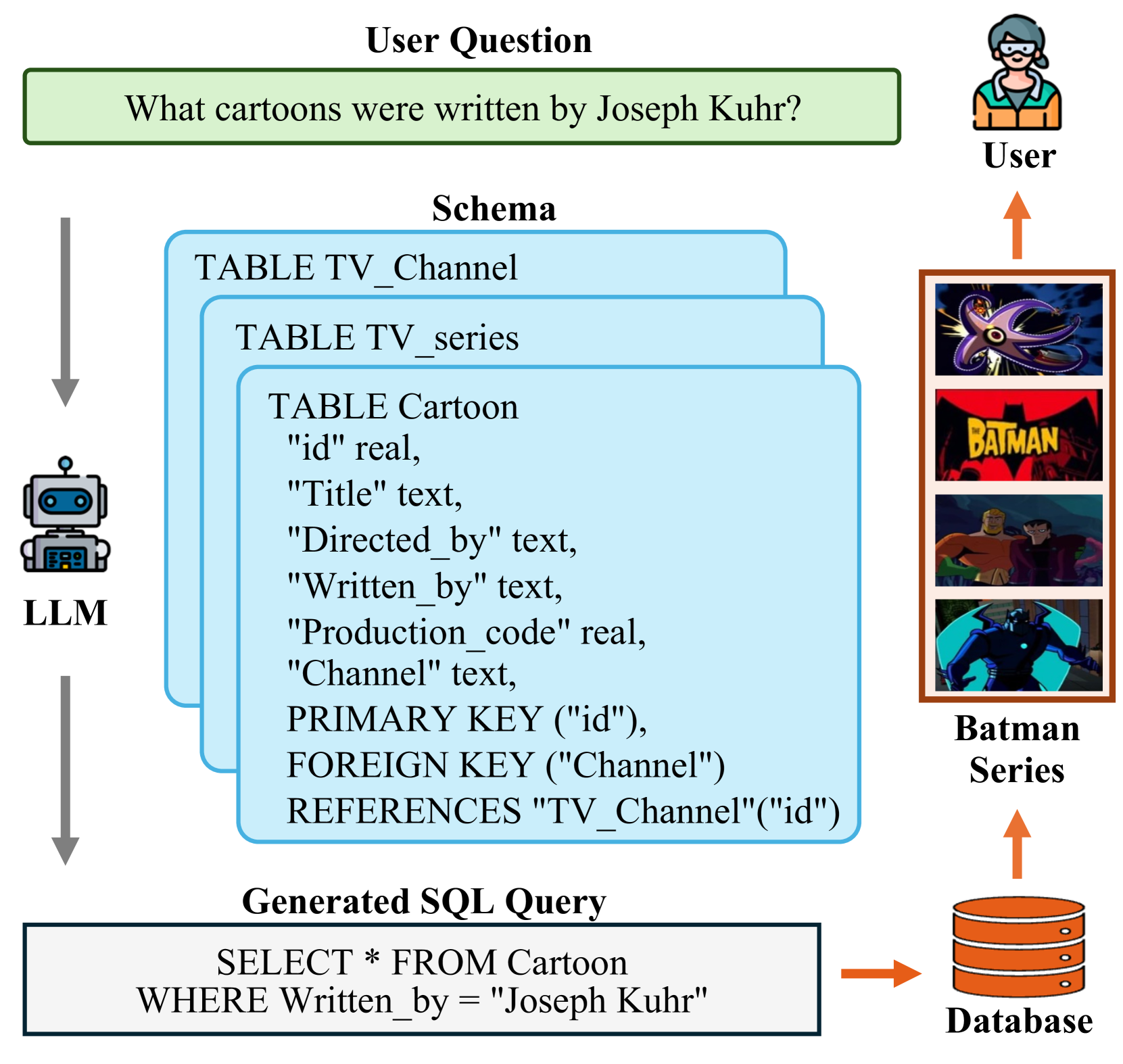
This study explores text-to-SQL parsing by leveraging the powerful reasoning capabilities of large language models (LLMs). Despite recent advancements, existing LLM-based methods have not adequately addressed scalability, leading to inefficiencies when processing wide tables. Furthermore, current interaction-based approaches either lack a step-by-step, interpretable SQL generation process or fail to provide an efficient and universally applicable interaction design. To address these challenges, we introduce Interactive-T2S, a framework that generates SQL queries through direct interactions with databases. This framework includes four general tools that facilitate proactive and efficient information retrieval by the LLM. Additionally, we have developed detailed exemplars to demonstrate the step-wise reasoning processes within our framework. Our experiments on the BIRD-Dev dataset, employing a setting without oracle knowledge, reveal that our method achieves state-of-the-art results with only two exemplars, underscoring the effectiveness and robustness of our framework.
Read more8/22/2024
0
Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, Xiao Huang
Generating accurate SQL from natural language questions (text-to-SQL) is a long-standing challenge due to the complexities in user question understanding, database schema comprehension, and SQL generation. Conventional text-to-SQL systems, comprising human engineering and deep neural networks, have made substantial progress. Subsequently, pre-trained language models (PLMs) have been developed and utilized for text-to-SQL tasks, achieving promising performance. As modern databases become more complex, the corresponding user questions also grow more challenging, causing PLMs with parameter constraints to produce incorrect SQL. This necessitates more sophisticated and tailored optimization methods, which, in turn, restricts the applications of PLM-based systems. Recently, large language models (LLMs) have demonstrated significant capabilities in natural language understanding as the model scale increases. Therefore, integrating LLM-based implementation can bring unique opportunities, improvements, and solutions to text-to-SQL research. In this survey, we present a comprehensive review of LLM-based text-to-SQL. Specifically, we propose a brief overview of the technical challenges and the evolutionary process of text-to-SQL. Then, we provide a detailed introduction to the datasets and metrics designed to evaluate text-to-SQL systems. After that, we present a systematic analysis of recent advances in LLM-based text-to-SQL. Finally, we discuss the remaining challenges in this field and propose expectations for future research directions.
Read more7/17/2024

0
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024
0
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
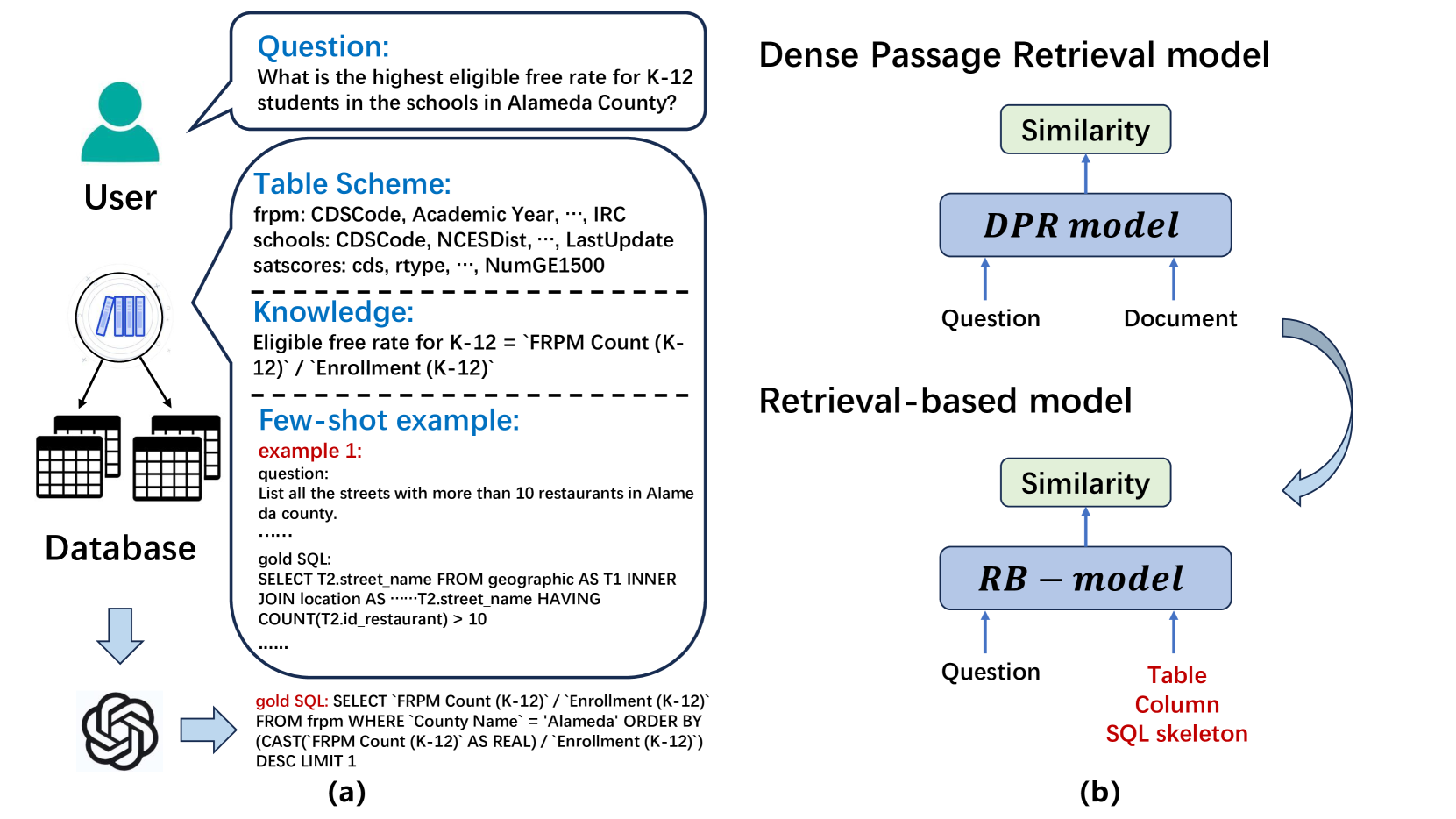
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024