STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases

0

Sign in to get full access
Overview
- This paper introduces STaRK, a new benchmark for evaluating the ability of large language models (LLMs) to retrieve information from both textual and relational knowledge bases.
- The benchmark includes a diverse range of tasks, such as question answering, fact checking, and knowledge base completion, to assess the models' performance on different types of knowledge retrieval.
- The authors evaluate several state-of-the-art LLMs on the STaRK benchmark and provide insights into the strengths and limitations of these models when it comes to retrieving knowledge from structured and unstructured sources.
Plain English Explanation
The paper presents a new benchmark called STaRK that is designed to test how well large language models (LLMs) can retrieve information from different types of knowledge sources. These knowledge sources can be either textual, like books and articles, or relational, like databases and knowledge graphs.
The benchmark includes a variety of tasks that assess the models' ability to answer questions, verify facts, and fill in missing information in knowledge bases. By evaluating LLMs on this diverse set of tasks, the researchers can get a more comprehensive understanding of the models' strengths and weaknesses when it comes to retrieving and using different kinds of knowledge.
The authors test several state-of-the-art LLMs on the STaRK benchmark and share their findings. This provides valuable insights into the current capabilities of these models and can help guide future research and development to improve their knowledge retrieval abilities.
Technical Explanation
The paper introduces the STaRK (Structured and Textual Retrieval Benchmark) to assess the performance of large language models (LLMs) on retrieving information from both textual and relational knowledge bases. The benchmark includes a diverse set of tasks, such as question answering, fact checking, and knowledge base completion, to evaluate the models' ability to retrieve knowledge from different sources.
The authors evaluate several state-of-the-art LLMs, including GPT-3, T5, and REALM, on the STaRK benchmark. They analyze the models' performance across the various tasks and provide insights into the strengths and limitations of these models when it comes to retrieving knowledge from structured and unstructured sources. The results highlight the models' ability to leverage semantic textual relatedness and entity linking to improve their knowledge retrieval capabilities.
Critical Analysis
The STaRK benchmark provides a comprehensive and well-designed framework for evaluating the knowledge retrieval capabilities of LLMs. By including a diverse range of tasks and knowledge sources, the benchmark offers a more holistic assessment of the models' performance compared to previous benchmarks that focused on specific domains or task types.
However, the paper does not address certain limitations of the benchmark, such as the potential biases or gaps in the underlying datasets used for the tasks. Additionally, the evaluation is limited to a few state-of-the-art LLMs, and it would be valuable to see how a broader range of models, including those with different architectures or training approaches, perform on the benchmark.
Furthermore, the paper does not delve into the potential societal implications of the findings, such as how the strengths and limitations of these models might impact their real-world applications in areas like information retrieval, question answering, or knowledge-based decision-making.
Conclusion
The STaRK benchmark introduced in this paper represents a significant advancement in the evaluation of large language models' knowledge retrieval capabilities. By assessing the models' performance on a diverse set of tasks involving both textual and relational knowledge, the benchmark provides a more comprehensive understanding of the current state of the art and highlights areas for further research and development.
The findings from the authors' evaluation of state-of-the-art LLMs on the STaRK benchmark suggest that while these models have made substantial progress in knowledge retrieval, there is still room for improvement, particularly when it comes to effectively integrating and leveraging different types of knowledge sources. Continued research and innovation in this area could lead to the development of more robust and versatile knowledge-powered AI systems that can better support a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
Shirley Wu, Shiyu Zhao, Michihiro Yasunaga, Kexin Huang, Kaidi Cao, Qian Huang, Vassilis N. Ioannidis, Karthik Subbian, James Zou, Jure Leskovec
Answering real-world complex queries, such as complex product search, often requires accurate retrieval from semi-structured knowledge bases that involve blend of unstructured (e.g., textual descriptions of products) and structured (e.g., entity relations of products) information. However, previous works have mostly studied textual and relational retrieval tasks as separate topics. To address the gap, we develop STARK, a large-scale Semi-structure retrieval benchmark on Textual and Relational K nowledge Bases. Our benchmark covers three domains/datasets: product search, academic paper search, and queries in precision medicine. We design a novel pipeline to synthesize realistic user queries that integrate diverse relational information and complex textual properties, together with their ground-truth answers (items). We conduct rigorous human evaluation to validate the quality of our synthesized queries. We further enhance the benchmark with high-quality human-generated queries to provide an authentic reference. STARK serves as a comprehensive testbed for evaluating the performance of retrieval systems driven by large language models (LLMs). Our experiments suggest that STARK presents significant challenges to the current retrieval and LLM systems, indicating the demand for building more capable retrieval systems. The benchmark data and code are available on https://github.com/snap-stanford/stark.
Read more5/22/2024
0
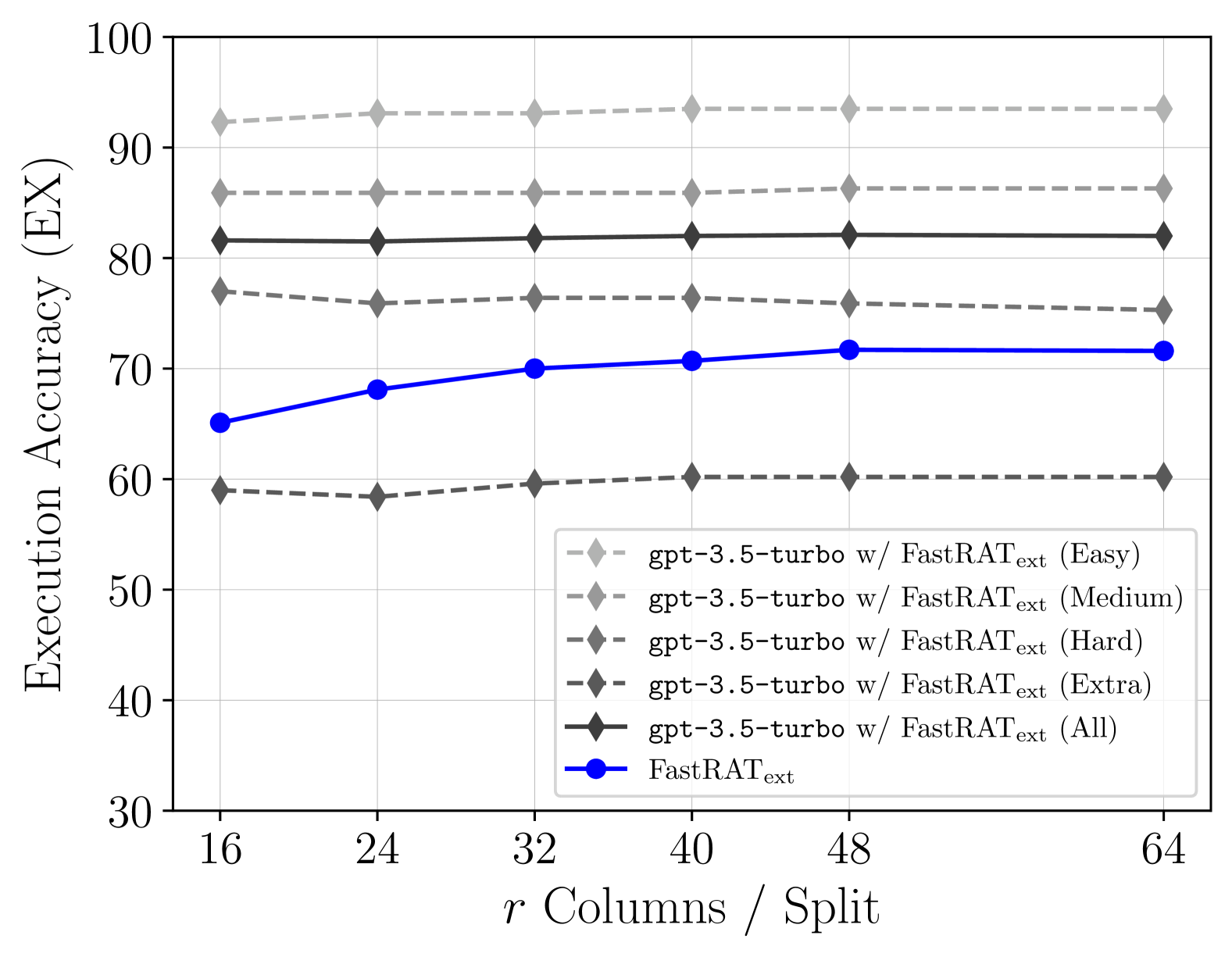
Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning
Zhili Shen, Pavlos Vougiouklis, Chenxin Diao, Kaustubh Vyas, Yuanyi Ji, Jeff Z. Pan
We focus on Text-to-SQL semantic parsing from the perspective of Large Language Models. Motivated by challenges related to the size of commercial database schemata and the deployability of business intelligence solutions, we propose an approach that dynamically retrieves input database information and uses abstract syntax trees to select few-shot examples for in-context learning. Furthermore, we investigate the extent to which an in-parallel semantic parser can be leveraged for generating $textit{approximated}$ versions of the expected SQL queries, to support our retrieval. We take this approach to the extreme--we adapt a model consisting of less than $500$M parameters, to act as an extremely efficient approximator, enhancing it with the ability to process schemata in a parallelised manner. We apply our approach to monolingual and cross-lingual benchmarks for semantic parsing, showing improvements over state-of-the-art baselines. Comprehensive experiments highlight the contribution of modules involved in this retrieval-augmented generation setting, revealing interesting directions for future work.
Read more7/4/2024

0
LitSearch: A Retrieval Benchmark for Scientific Literature Search
Anirudh Ajith, Mengzhou Xia, Alexis Chevalier, Tanya Goyal, Danqi Chen, Tianyu Gao
Literature search questions, such as where can I find research on the evaluation of consistency in generated summaries? pose significant challenges for modern search engines and retrieval systems. These questions often require a deep understanding of research concepts and the ability to reason over entire articles. In this work, we introduce LitSearch, a retrieval benchmark comprising 597 realistic literature search queries about recent ML and NLP papers. LitSearch is constructed using a combination of (1) questions generated by GPT-4 based on paragraphs containing inline citations from research papers and (2) questions about recently published papers, manually written by their authors. All LitSearch questions were manually examined or edited by experts to ensure high quality. We extensively benchmark state-of-the-art retrieval models and also evaluate two LLM-based reranking pipelines. We find a significant performance gap between BM25 and state-of-the-art dense retrievers, with a 24.8% difference in absolute recall@5. The LLM-based reranking strategies further improve the best-performing dense retriever by 4.4%. Additionally, commercial search engines and research tools like Google Search perform poorly on LitSearch, lagging behind the best dense retriever by 32 points. Taken together, these results show that LitSearch is an informative new testbed for retrieval systems while catering to a real-world use case.
Read more7/30/2024
0
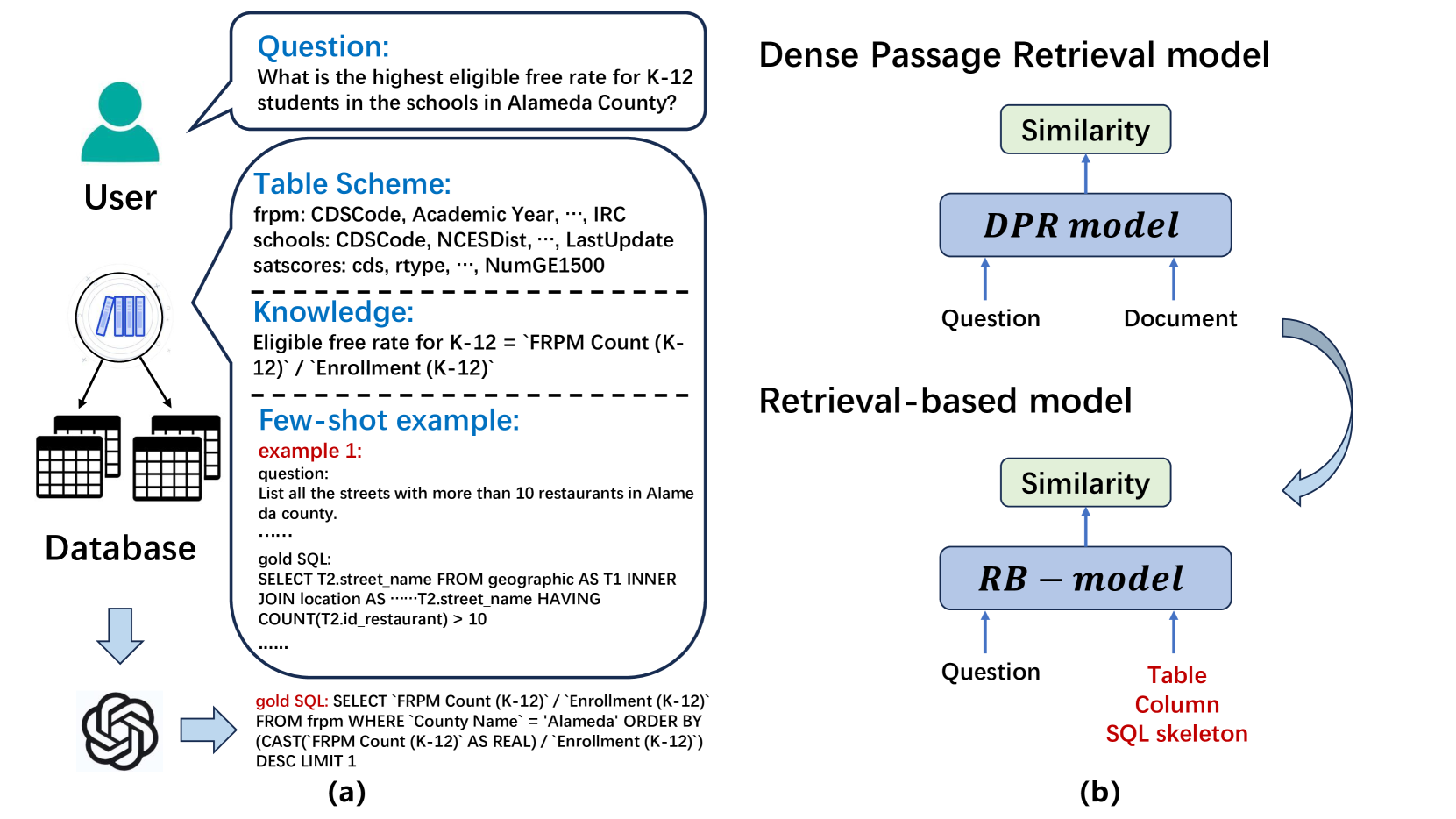
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024