Improving Retrieval in Sponsored Search by Leveraging Query Context Signals

0
Sign in to get full access
Overview
- The paper proposes a new method called "Augmented Unity" for improving retrieval in sponsored search by leveraging query context signals.
- The key idea is to use additional contextual information, such as user browsing history and current webpage content, to enhance the relevance of search results.
- The authors conduct experiments on real-world sponsored search data and demonstrate improvements in click-through rate and other relevant metrics.
Plain English Explanation
When you search for something online, the search engine not only looks at the words in your query, but also tries to understand the context around your search. This can include things like your browsing history, the current webpage you're on, and other signals. The paper explores a new approach called "Augmented Unity" that leverages this additional contextual information to improve the relevance of sponsored search results - the ads and links you see at the top or side of the search page.
The key idea is that by understanding more about the
The authors tested their "Augmented Unity" approach on real data from sponsored search campaigns and found that it did in fact boost the relevance of the results, leading to better performance. While the technical details get a bit complex, the core concept is fairly straightforward - using context to understand search intent and improve the match between queries and results.
Technical Explanation
The paper introduces a new method called "Augmented Unity" that aims to improve retrieval in sponsored search by leveraging query context signals. The key idea is to incorporate additional contextual information, such as user browsing history and current webpage content, to enhance the relevance of search results.
The proposed approach consists of two main components:
-
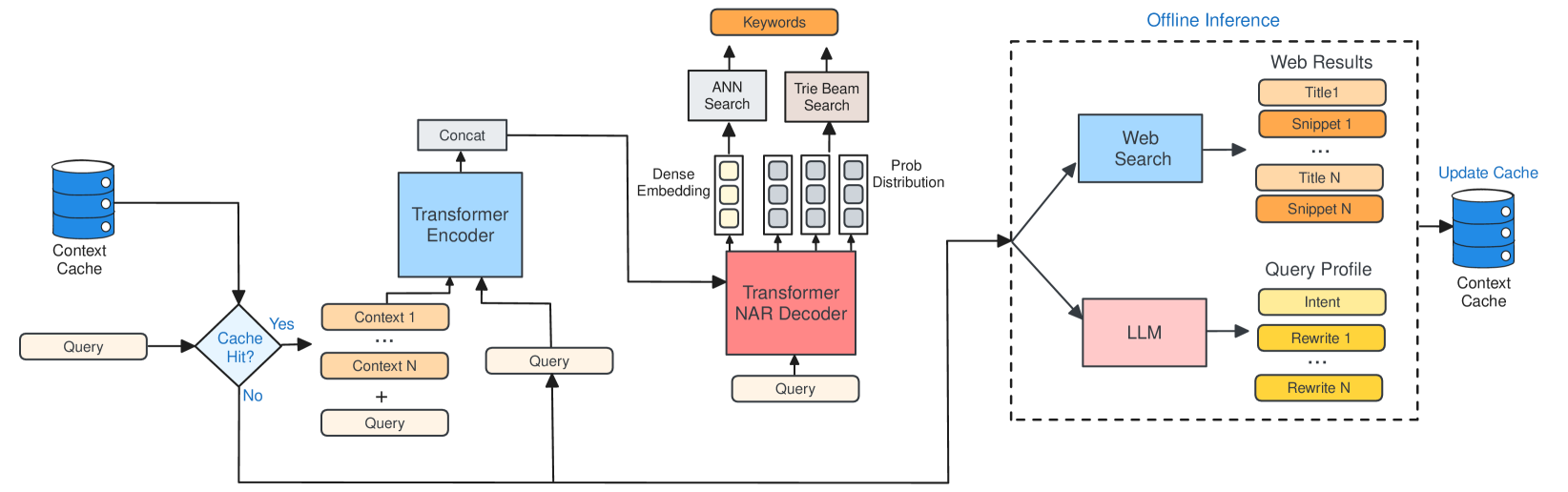
Query Contextualization: This module takes the user's search query and enriches it with relevant contextual signals, such as the user's browsing history, location, and the content of the current webpage. The goal is to better capture the user's search intent.
-
Augmented Retrieval: The enriched query is then used to retrieve and rank the sponsored search results. The retrieval model is trained to optimize for relevance by considering both the query and the associated contextual signals.
The authors evaluate their approach on real-world sponsored search data and report improvements in click-through rate and other relevant metrics compared to baseline methods that only use the search query. The results suggest that leveraging query context can indeed lead to more relevant and useful search results.
Critical Analysis
The paper presents a promising approach for improving sponsored search retrieval by incorporating contextual signals beyond the search query itself. However, there are a few potential limitations and areas for further research:
-
Data Availability and Privacy: The effectiveness of the proposed method relies on the availability of rich contextual data, such as user browsing history and webpage content. Collecting and using such data raises privacy concerns that need to be carefully addressed.
-
Contextual Signal Selection: The paper does not provide a detailed analysis of which contextual signals are the most informative for improving retrieval. Further research could explore different types of contextual data and their relative importance.
-
Generalization to Other Domains: The experiments were conducted on sponsored search data, which has its own unique characteristics. It would be valuable to investigate the performance of the "Augmented Unity" approach in other search domains, such as general web search or question answering.
-
Interpretability and Explainability: The paper does not provide much insight into how the contextual signals are used by the retrieval model to improve relevance. Improving the interpretability and explainability of the model could be an important direction for future work.
Conclusion
The "Augmented Unity" approach proposed in this paper represents an interesting step towards leveraging query context to improve the relevance of sponsored search results. By incorporating additional signals beyond the search query itself, the method can better capture user intent and deliver more useful and engaging results. While the technical details are complex, the core idea is fairly straightforward and could have broader implications for enhancing search and information retrieval more generally. Further research is needed to address the limitations and explore the generalizability of the approach, but the results presented in this paper are certainly promising.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Retrieval in Sponsored Search by Leveraging Query Context Signals
Akash Kumar Mohankumar, Gururaj K, Gagan Madan, Amit Singh
Accurately retrieving relevant bid keywords for user queries is critical in Sponsored Search but remains challenging, particularly for short, ambiguous queries. Existing dense and generative retrieval models often fail to capture nuanced user intent in these cases. To address this, we propose an approach to enhance query understanding by augmenting queries with rich contextual signals derived from web search results and large language models, stored in an online cache. Specifically, we use web search titles and snippets to ground queries in real-world information and utilize GPT-4 to generate query rewrites and explanations that clarify user intent. These signals are efficiently integrated through a Fusion-in-Decoder based Unity architecture, enabling both dense and generative retrieval with serving costs on par with traditional context-free models. To address scenarios where context is unavailable in the cache, we introduce context glancing, a curriculum learning strategy that improves model robustness and performance even without contextual signals during inference. Extensive offline experiments demonstrate that our context-aware approach substantially outperforms context-free models. Furthermore, online A/B testing on a prominent search engine across 160+ countries shows significant improvements in user engagement and revenue.
Read more7/22/2024

0
Enhancing Knowledge Retrieval with In-Context Learning and Semantic Search through Generative AI
Mohammed-Khalil Ghali, Abdelrahman Farrag, Daehan Won, Yu Jin
Retrieving and extracting knowledge from extensive research documents and large databases presents significant challenges for researchers, students, and professionals in today's information-rich era. Existing retrieval systems, which rely on general-purpose Large Language Models (LLMs), often fail to provide accurate responses to domain-specific inquiries. Additionally, the high cost of pretraining or fine-tuning LLMs for specific domains limits their widespread adoption. To address these limitations, we propose a novel methodology that combines the generative capabilities of LLMs with the fast and accurate retrieval capabilities of vector databases. This advanced retrieval system can efficiently handle both tabular and non-tabular data, understand natural language user queries, and retrieve relevant information without fine-tuning. The developed model, Generative Text Retrieval (GTR), is adaptable to both unstructured and structured data with minor refinement. GTR was evaluated on both manually annotated and public datasets, achieving over 90% accuracy and delivering truthful outputs in 87% of cases. Our model achieved state-of-the-art performance with a Rouge-L F1 score of 0.98 on the MSMARCO dataset. The refined model, Generative Tabular Text Retrieval (GTR-T), demonstrated its efficiency in large database querying, achieving an Execution Accuracy (EX) of 0.82 and an Exact-Set-Match (EM) accuracy of 0.60 on the Spider dataset, using an open-source LLM. These efforts leverage Generative AI and In-Context Learning to enhance human-text interaction and make advanced AI capabilities more accessible. By integrating robust retrieval systems with powerful LLMs, our approach aims to democratize access to sophisticated AI tools, improving the efficiency, accuracy, and scalability of AI-driven information retrieval and database querying.
Read more6/17/2024
0
Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
Zhuo Chen, Xinyu Wang, Yong Jiang, Pengjun Xie, Fei Huang, Kewei Tu
In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Read more7/2/2024

0
CHESS: Contextual Harnessing for Efficient SQL Synthesis
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, Amin Saberi
Utilizing large language models (LLMs) for transforming natural language questions into SQL queries (text-to-SQL) is a promising yet challenging approach, particularly when applied to real-world databases with complex and extensive schemas. In particular, effectively incorporating data catalogs and database values for SQL generation remains an obstacle, leading to suboptimal solutions. We address this problem by proposing a new pipeline that effectively retrieves relevant data and context, selects an efficient schema, and synthesizes correct and efficient SQL queries. To increase retrieval precision, our pipeline introduces a hierarchical retrieval method leveraging model-generated keywords, locality-sensitive hashing indexing, and vector databases. Additionally, we have developed an adaptive schema pruning technique that adjusts based on the complexity of the problem and the model's context size. Our approach generalizes to both frontier proprietary models like GPT-4 and open-source models such as Llama-3-70B. Through a series of ablation studies, we demonstrate the effectiveness of each component of our pipeline and its impact on the end-to-end performance. Our method achieves new state-of-the-art performance on the cross-domain challenging BIRD dataset.
Read more6/28/2024