User Intent Recognition and Semantic Cache Optimization-Based Query Processing Framework using CFLIS and MGR-LAU

0
👁️
Sign in to get full access
Overview
- The paper explores how to optimize Query Processing (QP) in cloud-based systems by considering user intent in queries.
- The researchers use a Contextual Fuzzy Linguistic Inference System (CFLIS) to analyze informational, navigational, and transactional intents in user queries.
- The goal is to enhance QP and improve the accuracy and efficiency of retrieving information from a semantic cache database.
Plain English Explanation
When users search for information online, the process of interpreting and responding to their queries is called query processing (QP). Cloud-based systems can optimize QP by storing frequently accessed data closer to users in a cache, reducing the time it takes to retrieve that information.
However, previous approaches have lacked focus on the actual intentions behind user queries. Some queries may be seeking general information (informational), trying to navigate to a specific website (navigational), or looking to complete a transaction (transactional).
This research uses a Contextual Fuzzy Linguistic Inference System (CFLIS) to analyze the intent behind user queries. By understanding whether a query is seeking information, navigation, or a transaction, the system can enhance question answering in enterprise knowledge bases and more accurately process the query.
The researchers also use techniques like named entity recognition and semantic structuring of data to better understand the context and meaning of the user's query. This allows the system to quickly retrieve relevant information from a semantic cache database of previously interpreted queries.
By considering user intent and employing these advanced natural language processing techniques, the researchers aim to make query processing more efficient and accurate, ultimately providing users with better search experiences.
Technical Explanation
The key steps in the researchers' approach are:
-
Query Parsing: The user's query is processed using techniques like tokenization, normalization, stop word removal, stemming, and part-of-speech (POS) tagging. The query is then expanded using the WordNet technique to improve understanding.
-
Named Entity Recognition: The Bidirectional Encoder UnispecNorm Representations from Transformers (BEUNRT) model is used to identify named entities in the expanded query.
-
Data Structuring: The query-related data is structured using the Epanechnikov Kernel-Ordering Points To Identify the Clustering Structure (EK-OPTICS) technique to facilitate efficient processing and retrieval.
-
Intent Identification: The processed query is analyzed to identify the user's informational, navigational, or transactional intent.
-
Semantic Cache Processing: The structured data, extracted features, and detected intents are input to a Multi-head Gated Recurrent Learnable Attention Unit (MGR-LAU), which processes the query using a semantic cache database of previously interpreted queries.
-
Semantic Similarity Evaluation: The semantic similarity between the retrieved query and the user's input query is analyzed, and the process continues until the similarity reaches 0.9 or higher.
By considering user intent and employing these advanced techniques, the researchers aim to achieve more efficient and accurate query processing with a minimum latency of 12,856 milliseconds.
Critical Analysis
The paper presents a promising approach to improving query processing by incorporating user intent analysis. However, some potential limitations and areas for further research include:
- The performance evaluation focused on latency, but additional metrics like precision, recall, and F1-score could provide a more comprehensive assessment of the system's effectiveness.
- The researchers did not discuss the computational and storage overhead of maintaining the semantic cache database and running the various natural language processing models.
- The study was conducted in a controlled lab environment, and the researchers acknowledge the need for real-world testing to validate the system's performance in diverse, dynamic user scenarios.
- The paper does not address potential privacy concerns related to storing user query history and intent data in the semantic cache.
Overall, the research offers a valuable contribution to the field of query processing, but further investigation and refinement may be needed to address these potential limitations and ensure the scalability and robustness of the proposed solution.
Conclusion
This research explores a novel approach to optimizing query processing in cloud-based systems by incorporating user intent analysis using a Contextual Fuzzy Linguistic Inference System (CFLIS). By understanding whether a user's query is seeking information, navigation, or a transaction, the system can more accurately process the query and retrieve relevant information from a semantic cache database.
The researchers employ advanced natural language processing techniques, such as named entity recognition and semantic data structuring, to enhance the understanding and processing of user queries. This combination of intent analysis and contextual understanding aims to improve the efficiency and accuracy of query processing, ultimately providing users with better search experiences.
While the paper presents promising results, further research is needed to address potential limitations and ensure the scalability and robustness of the proposed solution. Nonetheless, this work contributes to the growing body of research on enhancing query processing and information retrieval in the era of cloud computing and big data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
User Intent Recognition and Semantic Cache Optimization-Based Query Processing Framework using CFLIS and MGR-LAU
Sakshi Mahendru
Query Processing (QP) is optimized by a Cloud-based cache by storing the frequently accessed data closer to users. Nevertheless, the lack of focus on user intention type in queries affected the efficiency of QP in prevailing works. Thus, by using a Contextual Fuzzy Linguistic Inference System (CFLIS), this work analyzed the informational, navigational, and transactional-based intents in queries for enhanced QP. Primarily, the user query is parsed using tokenization, normalization, stop word removal, stemming, and POS tagging and then expanded using the WordNet technique. After expanding the queries, to enhance query understanding and to facilitate more accurate analysis and retrieval in query processing, the named entity is recognized using Bidirectional Encoder UnispecNorm Representations from Transformers (BEUNRT). Next, for efficient QP and retrieval of query information from the semantic cache database, the data is structured using Epanechnikov Kernel-Ordering Points To Identify the Clustering Structure (EK-OPTICS). The features are extracted from the structured data. Now, sentence type is identified and intent keywords are extracted from the parsed query. Next, the extracted features, detected intents and structured data are inputted to the Multi-head Gated Recurrent Learnable Attention Unit (MGR-LAU), which processes the query based on a semantic cache database (stores previously interpreted queries to expedite effective future searches). Moreover, the query is processed with a minimum latency of 12856ms. Lastly, the Semantic Similarity (SS) is analyzed between the retrieved query and the inputted user query, which continues until the similarity reaches 0.9 and above. Thus, the proposed work surpassed the previous methodologies.
Read more6/10/2024
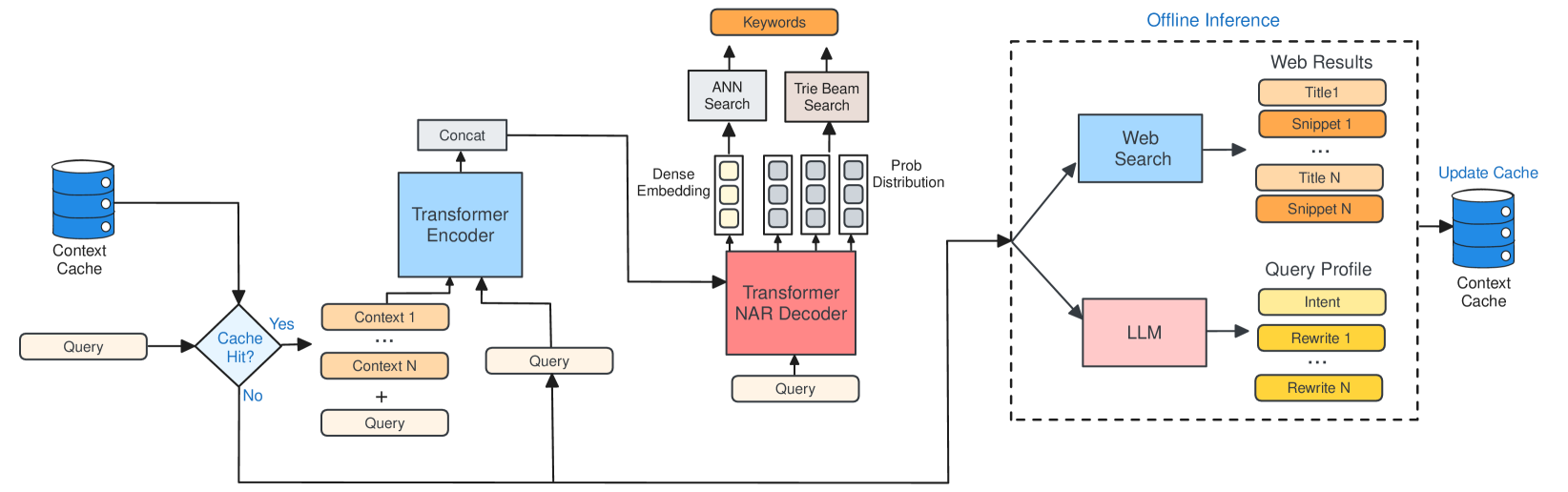
0
Improving Retrieval in Sponsored Search by Leveraging Query Context Signals
Akash Kumar Mohankumar, Gururaj K, Gagan Madan, Amit Singh
Accurately retrieving relevant bid keywords for user queries is critical in Sponsored Search but remains challenging, particularly for short, ambiguous queries. Existing dense and generative retrieval models often fail to capture nuanced user intent in these cases. To address this, we propose an approach to enhance query understanding by augmenting queries with rich contextual signals derived from web search results and large language models, stored in an online cache. Specifically, we use web search titles and snippets to ground queries in real-world information and utilize GPT-4 to generate query rewrites and explanations that clarify user intent. These signals are efficiently integrated through a Fusion-in-Decoder based Unity architecture, enabling both dense and generative retrieval with serving costs on par with traditional context-free models. To address scenarios where context is unavailable in the cache, we introduce context glancing, a curriculum learning strategy that improves model robustness and performance even without contextual signals during inference. Extensive offline experiments demonstrate that our context-aware approach substantially outperforms context-free models. Furthermore, online A/B testing on a prominent search engine across 160+ countries shows significant improvements in user engagement and revenue.
Read more7/22/2024

0
Leveraging Large Language Models for Semantic Query Processing in a Scholarly Knowledge Graph
Runsong Jia, Bowen Zhang, Sergio J. Rodr'iguez M'endez, Pouya G. Omran
The proposed research aims to develop an innovative semantic query processing system that enables users to obtain comprehensive information about research works produced by Computer Science (CS) researchers at the Australian National University (ANU). The system integrates Large Language Models (LLMs) with the ANU Scholarly Knowledge Graph (ASKG), a structured repository of all research-related artifacts produced at ANU in the CS field. Each artifact and its parts are represented as textual nodes stored in a Knowledge Graph (KG). To address the limitations of traditional scholarly KG construction and utilization methods, which often fail to capture fine-grained details, we propose a novel framework that integrates the Deep Document Model (DDM) for comprehensive document representation and the KG-enhanced Query Processing (KGQP) for optimized complex query handling. DDM enables a fine-grained representation of the hierarchical structure and semantic relationships within academic papers, while KGQP leverages the KG structure to improve query accuracy and efficiency with LLMs. By combining the ASKG with LLMs, our approach enhances knowledge utilization and natural language understanding capabilities. The proposed system employs an automatic LLM-SPARQL fusion to retrieve relevant facts and textual nodes from the ASKG. Initial experiments demonstrate that our framework is superior to baseline methods in terms of accuracy retrieval and query efficiency. We showcase the practical application of our framework in academic research scenarios, highlighting its potential to revolutionize scholarly knowledge management and discovery. This work empowers researchers to acquire and utilize knowledge from documents more effectively and provides a foundation for developing precise and reliable interactions with LLMs.
Read more5/27/2024
💬
0
IQLS: Framework for leveraging Metadata to enable Large Language Model based queries to complex, versatile Data
Sami Azirar, Hossam A. Gabbar, Chaouki Regoui
As the amount and complexity of data grows, retrieving it has become a more difficult task that requires greater knowledge and resources. This is especially true for the logistics industry, where new technologies for data collection provide tremendous amounts of interconnected real-time data. The Intelligent Query and Learning System (IQLS) simplifies the process by allowing natural language use to simplify data retrieval . It maps structured data into a framework based on the available metadata and available data models. This framework creates an environment for an agent powered by a Large Language Model. The agent utilizes the hierarchical nature of the data to filter iteratively by making multiple small context-aware decisions instead of one-shot data retrieval. After the Data filtering, the IQLS enables the agent to fulfill tasks given by the user query through interfaces. These interfaces range from multimodal transportation information retrieval to route planning under multiple constraints. The latter lets the agent define a dynamic object, which is determined based on the query parameters. This object represents a driver capable of navigating a road network. The road network is depicted as a graph with attributes based on the data. Using a modified version of the Dijkstra algorithm, the optimal route under the given constraints can be determined. Throughout the entire process, the user maintains the ability to interact and guide the system. The IQLS is showcased in a case study on the Canadian logistics sector, allowing geospatial, visual, tabular and text data to be easily queried semantically in natural language.
Read more5/28/2024