Incorporating dense metric depth into neural 3D representations for view synthesis and relighting

0

Sign in to get full access
Overview
- Explores incorporating dense metric depth into neural 3D representations for view synthesis and relighting
- Provides a method to fuse dense depth maps with neural scene representations for improved rendering
- Demonstrates benefits for applications like view synthesis and relighting
Plain English Explanation
This research paper presents a method for improving neural 3D representations by incorporating dense metric depth information. Neural 3D representations are digital models that can be used to generate realistic 3D images and scenes. By fusing these representations with detailed depth data, the researchers were able to create more accurate and realistic renderings.
The key idea is to combine the strengths of neural scene representations, which can capture complex geometric and appearance details, with the precision of dense depth maps, which provide accurate 3D measurements. This allows the system to produce high-quality novel views and realistic relighting of 3D scenes.
The applications of this work include view synthesis, where the system can generate new perspectives of a scene, and relighting, where the lighting and appearance of a scene can be adjusted. These capabilities are important for virtual reality, gaming, and other 3D content creation domains.
Technical Explanation
The core of the approach is to fuse a neural radiance field (NeRF) representation of the 3D scene with a dense depth map obtained from multi-view stereo or other depth sensing methods. The NeRF model can capture complex appearance and geometry, but lacks precise 3D measurements. By incorporating the dense depth information, the system can better reconstruct the true 3D structure of the scene.
Specifically, the researchers developed a neural network architecture that takes as input the NeRF representation, the dense depth map, and the desired view parameters. It then outputs the rendered image for that view, as well as an estimate of the depth. This depth estimation allows the model to handle view-dependent effects like specularities and transparency.
The model is trained end-to-end using a combination of photometric and geometric loss functions. The photometric loss ensures the rendered images match the ground truth, while the geometric loss encourages consistency between the predicted depth and the input depth map.
Experiments on several 3D scanning and rendering benchmarks demonstrate that this approach outperforms prior methods for both view synthesis and relighting tasks. The fused neural 3D representation is able to generate more detailed and accurate renderings compared to using just the NeRF or depth data alone.
Critical Analysis
A key limitation of this work is the reliance on pre-computed dense depth maps, which may not always be available or easy to obtain. The paper does not explore methods for jointly learning the depth estimation and neural 3D representation, which could make the approach more broadly applicable.
Additionally, the experiments focus on relatively simple synthetic scenes. Applying this technique to more complex, real-world environments with challenging lighting, materials, and occlusions would be an important area for future research.
Finally, the paper does not provide a detailed analysis of the computational and memory requirements of the proposed model. As neural 3D representations become more widely adopted, understanding the efficiency tradeoffs will be crucial for real-world deployment.
Conclusion
This research presents a promising approach for enhancing neural 3D representations by incorporating dense depth information. By fusing the strengths of neural scene models and precise 3D measurements, the system can generate higher-quality novel views and realistic relighting effects. While there are still some limitations to address, this work represents an important step forward in the quest to create truly compelling 3D content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
Arkadeep Narayan Chaudhury, Igor Vasiljevic, Sergey Zakharov, Vitor Guizilini, Rares Ambrus, Srinivasa Narasimhan, Christopher G. Atkeson
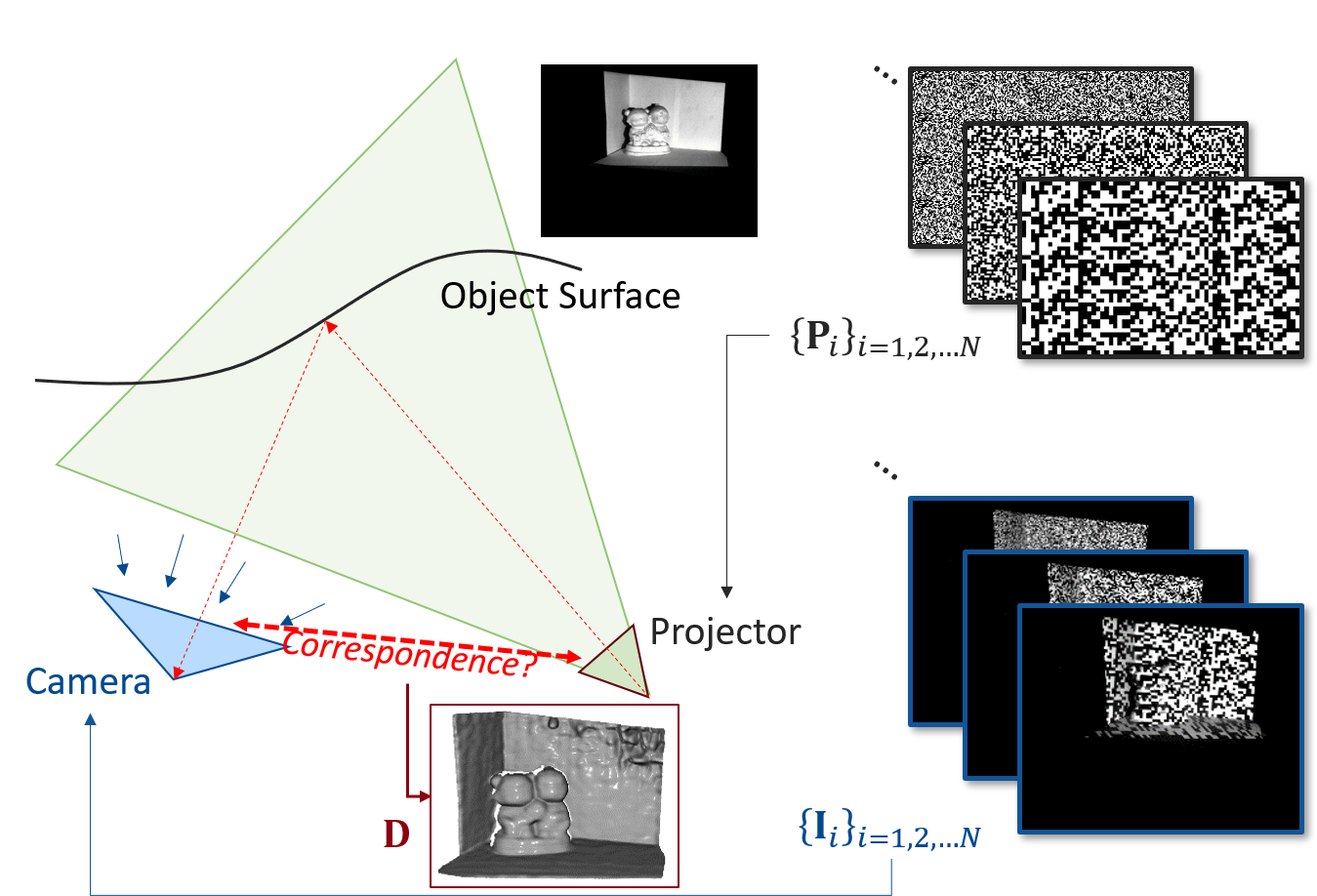
Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
Read more9/6/2024

0
DoubleTake: Geometry Guided Depth Estimation
Mohamed Sayed, Filippo Aleotti, Jamie Watson, Zawar Qureshi, Guillermo Garcia-Hernando, Gabriel Brostow, Sara Vicente, Michael Firman
Estimating depth from a sequence of posed RGB images is a fundamental computer vision task, with applications in augmented reality, path planning etc. Prior work typically makes use of previous frames in a multi view stereo framework, relying on matching textures in a local neighborhood. In contrast, our model leverages historical predictions by giving the latest 3D geometry data as an extra input to our network. This self-generated geometric hint can encode information from areas of the scene not covered by the keyframes and it is more regularized when compared to individual predicted depth maps for previous frames. We introduce a Hint MLP which combines cost volume features with a hint of the prior geometry, rendered as a depth map from the current camera location, together with a measure of the confidence in the prior geometry. We demonstrate that our method, which can run at interactive speeds, achieves state-of-the-art estimates of depth and 3D scene reconstruction in both offline and incremental evaluation scenarios.
Read more7/16/2024
0
Depth Reconstruction with Neural Signed Distance Fields in Structured Light Systems
Rukun Qiao, Hiroshi Kawasaki, Hongbin Zha
We introduce a novel depth estimation technique for multi-frame structured light setups using neural implicit representations of 3D space. Our approach employs a neural signed distance field (SDF), trained through self-supervised differentiable rendering. Unlike passive vision, where joint estimation of radiance and geometry fields is necessary, we capitalize on known radiance fields from projected patterns in structured light systems. This enables isolated optimization of the geometry field, ensuring convergence and network efficacy with fixed device positioning. To enhance geometric fidelity, we incorporate an additional color loss based on object surfaces during training. Real-world experiments demonstrate our method's superiority in geometric performance for few-shot scenarios, while achieving comparable results with increased pattern availability.
Read more5/21/2024

0
All-day Depth Completion
Vadim Ezhov, Hyoungseob Park, Zhaoyang Zhang, Rishi Upadhyay, Howard Zhang, Chethan Chinder Chandrappa, Achuta Kadambi, Yunhao Ba, Julie Dorsey, Alex Wong
We propose a method for depth estimation under different illumination conditions, i.e., day and night time. As photometry is uninformative in regions under low-illumination, we tackle the problem through a multi-sensor fusion approach, where we take as input an additional synchronized sparse point cloud (i.e., from a LiDAR) projected onto the image plane as a sparse depth map, along with a camera image. The crux of our method lies in the use of the abundantly available synthetic data to first approximate the 3D scene structure by learning a mapping from sparse to (coarse) dense depth maps along with their predictive uncertainty - we term this, SpaDe. In poorly illuminated regions where photometric intensities do not afford the inference of local shape, the coarse approximation of scene depth serves as a prior; the uncertainty map is then used with the image to guide refinement through an uncertainty-driven residual learning (URL) scheme. The resulting depth completion network leverages complementary strengths from both modalities - depth is sparse but insensitive to illumination and in metric scale, and image is dense but sensitive with scale ambiguity. SpaDe can be used in a plug-and-play fashion, which allows for 25% improvement when augmented onto existing methods to preprocess sparse depth. We demonstrate URL on the nuScenes dataset where we improve over all baselines by an average 11.65% in all-day scenarios, 11.23% when tested specifically for daytime, and 13.12% for nighttime scenes.
Read more5/28/2024