Investigating Automatic Scoring and Feedback using Large Language Models
2405.00602
0
0

Abstract
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates the use of large language models (LLMs) for automatic scoring and feedback generation in educational settings.
- It explores the potential of LLMs to assess student proficiency and provide personalized feedback, which could enhance the efficiency and scalability of assessment and learning processes.
- The research builds on recent advancements in LLM capabilities, including their ability to generate human-like text and understand complex language.
Plain English Explanation
Large language models (LLMs) are artificial intelligence systems that can understand and generate human-like text. Researchers are exploring how these powerful models could be used to automatically assess student work and provide personalized feedback, which could make the assessment and learning process more efficient and scalable.
In this paper, the researchers investigate different approaches for using LLMs to score student responses and generate feedback. For example, they explore how LLMs can be fine-tuned to provide more granular, nuanced scoring and how feedback models can be used to guide LLMs to provide more helpful and actionable comments.
By leveraging the language understanding and generation capabilities of LLMs, the researchers aim to create assessment and feedback systems that are more consistent, scalable, and personalized than traditional manual approaches. This could help educators save time and resources while providing students with more targeted and effective support.
However, the researchers also acknowledge some of the potential challenges and limitations of using LLMs in this context, such as increased vulnerabilities from fine-tuning and quantization. Careful consideration and further research will be needed to ensure the responsible and ethical deployment of these technologies in educational settings.
Technical Explanation
The paper presents several approaches for using large language models (LLMs) to automate the scoring and feedback processes in educational assessments.
One approach explores how LLMs can be fine-tuned to provide more granular, nuanced scoring of student responses. The researchers demonstrate that by training LLMs on large datasets of scored responses, the models can learn to assess proficiency at a more fine-grained level than traditional scoring rubrics.
Another approach investigates the use of feedback models to guide LLMs in providing more helpful and actionable comments to students. These feedback models are trained to recognize the characteristics of effective feedback and use that knowledge to steer the LLMs towards generating more useful and constructive comments.
The researchers also explore the potential of LLMs to provide a holistic assessment of student proficiency, going beyond simple scoring to generate a more comprehensive evaluation of a student's skills and understanding.
Additionally, the paper discusses the potential vulnerabilities that can arise from fine-tuning and quantization of LLMs, highlighting the need for careful consideration and evaluation of these techniques when deploying LLMs in high-stakes educational settings.
Overall, the research demonstrates the promising capabilities of LLMs in the context of automated assessment and feedback generation, while also identifying important challenges and areas for further investigation.
Critical Analysis
The paper provides a robust exploration of the potential benefits and limitations of using large language models (LLMs) for automated scoring and feedback in educational settings. The researchers acknowledge the significant challenges that must be addressed, such as ensuring the reliability and fairness of LLM-based assessment systems and mitigating potential vulnerabilities introduced by fine-tuning and quantization.
One area of concern raised in the paper is the potential for increased vulnerabilities from fine-tuning and quantization of LLMs. The researchers highlight the need for careful evaluation and validation of these techniques to ensure the integrity and security of the assessment systems.
Additionally, the paper does not delve deeply into the ethical considerations and potential biases that could arise from the use of LLMs in high-stakes educational contexts. While the researchers acknowledge the need for responsible deployment, further discussion on addressing bias, ensuring fairness, and protecting student privacy would strengthen the critical analysis.
Overall, the paper presents a well-designed and thoughtful investigation into the use of LLMs for automated scoring and feedback. However, the researchers could further strengthen their analysis by exploring the broader societal implications and ethical considerations of deploying these technologies in educational settings.
Conclusion
This paper explores the promising potential of using large language models (LLMs) to automate the scoring and feedback processes in educational assessments. The researchers demonstrate various approaches, such as fine-tuning LLMs for more granular scoring and using feedback models to guide LLMs in providing more helpful comments.
The findings suggest that LLMs could enhance the efficiency, consistency, and personalization of assessment and learning, potentially benefiting both educators and students. However, the paper also highlights important challenges, including the potential vulnerabilities introduced by fine-tuning and quantization, as well as the need for careful consideration of ethical and societal implications.
As the field of educational technology continues to evolve, the insights provided in this paper offer valuable guidance for researchers and practitioners exploring the use of advanced language models in assessment and feedback systems. Ongoing research and responsible deployment of these technologies will be crucial to unlocking their full potential while addressing the associated risks and challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
LoRA Land: 310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
Justin Zhao, Timothy Wang, Wael Abid, Geoffrey Angus, Arnav Garg, Jeffery Kinnison, Alex Sherstinsky, Piero Molino, Travis Addair, Devvret Rishi
0
0
Low Rank Adaptation (LoRA) has emerged as one of the most widely adopted methods for Parameter Efficient Fine-Tuning (PEFT) of Large Language Models (LLMs). LoRA reduces the number of trainable parameters and memory usage while achieving comparable performance to full fine-tuning. We aim to assess the viability of training and serving LLMs fine-tuned with LoRA in real-world applications. First, we measure the quality of LLMs fine-tuned with quantized low rank adapters across 10 base models and 31 tasks for a total of 310 models. We find that 4-bit LoRA fine-tuned models outperform base models by 34 points and GPT-4 by 10 points on average. Second, we investigate the most effective base models for fine-tuning and assess the correlative and predictive capacities of task complexity heuristics in forecasting the outcomes of fine-tuning. Finally, we evaluate the latency and concurrency capabilities of LoRAX, an open-source Multi-LoRA inference server that facilitates the deployment of multiple LoRA fine-tuned models on a single GPU using shared base model weights and dynamic adapter loading. LoRAX powers LoRA Land, a web application that hosts 25 LoRA fine-tuned Mistral-7B LLMs on a single NVIDIA A100 GPU with 80GB memory. LoRA Land highlights the quality and cost-effectiveness of employing multiple specialized LLMs over a single, general-purpose LLM.
5/3/2024
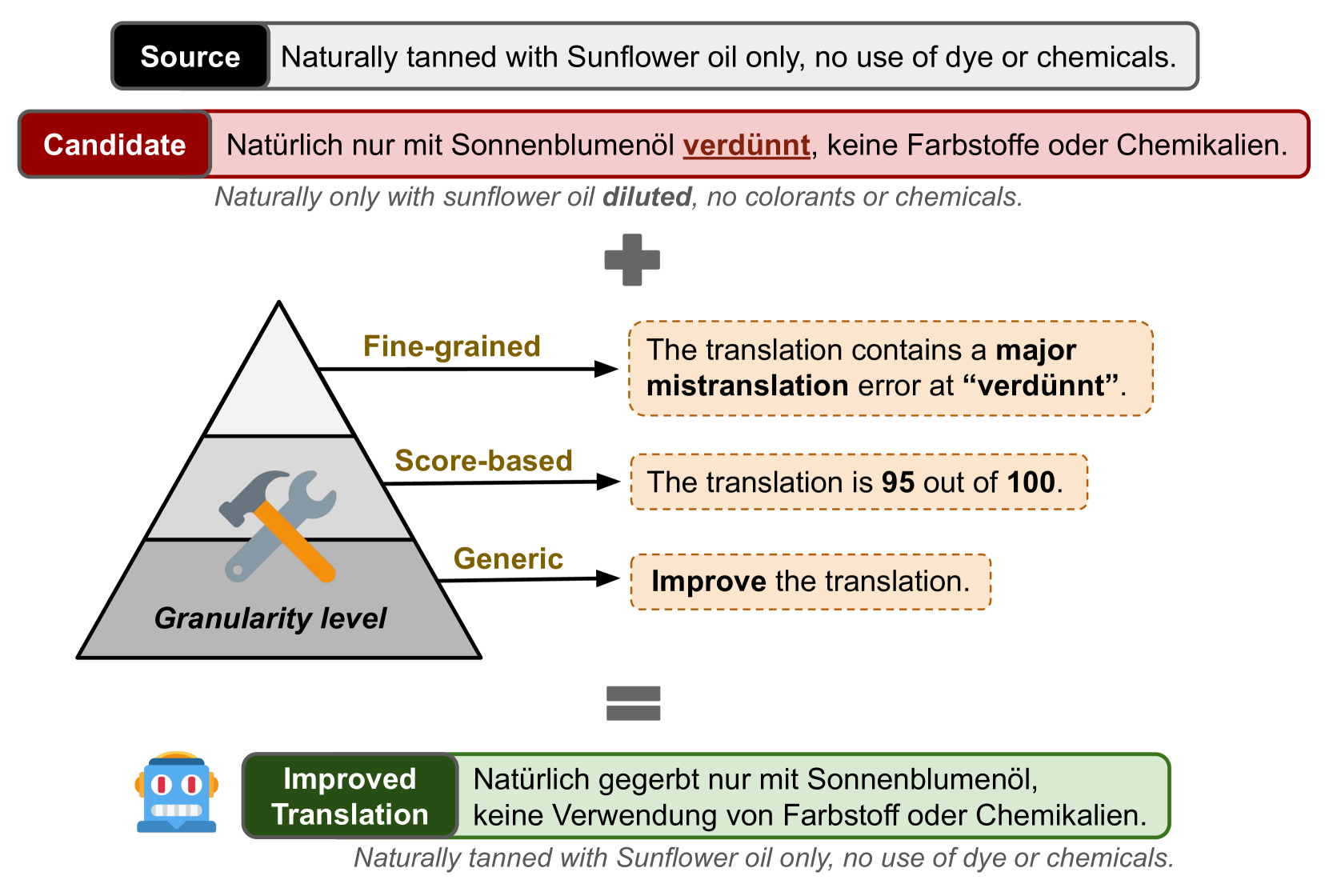
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
0
0
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
4/12/2024

Can Large Language Models Automatically Score Proficiency of Written Essays?
Watheq Mansour, Salam Albatarni, Sohaila Eltanbouly, Tamer Elsayed
0
0
Although several methods were proposed to address the problem of automated essay scoring (AES) in the last 50 years, there is still much to desire in terms of effectiveness. Large Language Models (LLMs) are transformer-based models that demonstrate extraordinary capabilities on various tasks. In this paper, we test the ability of LLMs, given their powerful linguistic knowledge, to analyze and effectively score written essays. We experimented with two popular LLMs, namely ChatGPT and Llama. We aim to check if these models can do this task and, if so, how their performance is positioned among the state-of-the-art (SOTA) models across two levels, holistically and per individual writing trait. We utilized prompt-engineering tactics in designing four different prompts to bring their maximum potential to this task. Our experiments conducted on the ASAP dataset revealed several interesting observations. First, choosing the right prompt depends highly on the model and nature of the task. Second, the two LLMs exhibited comparable average performance in AES, with a slight advantage for ChatGPT. Finally, despite the performance gap between the two LLMs and SOTA models in terms of predictions, they provide feedback to enhance the quality of the essays, which can potentially help both teachers and students.
4/17/2024
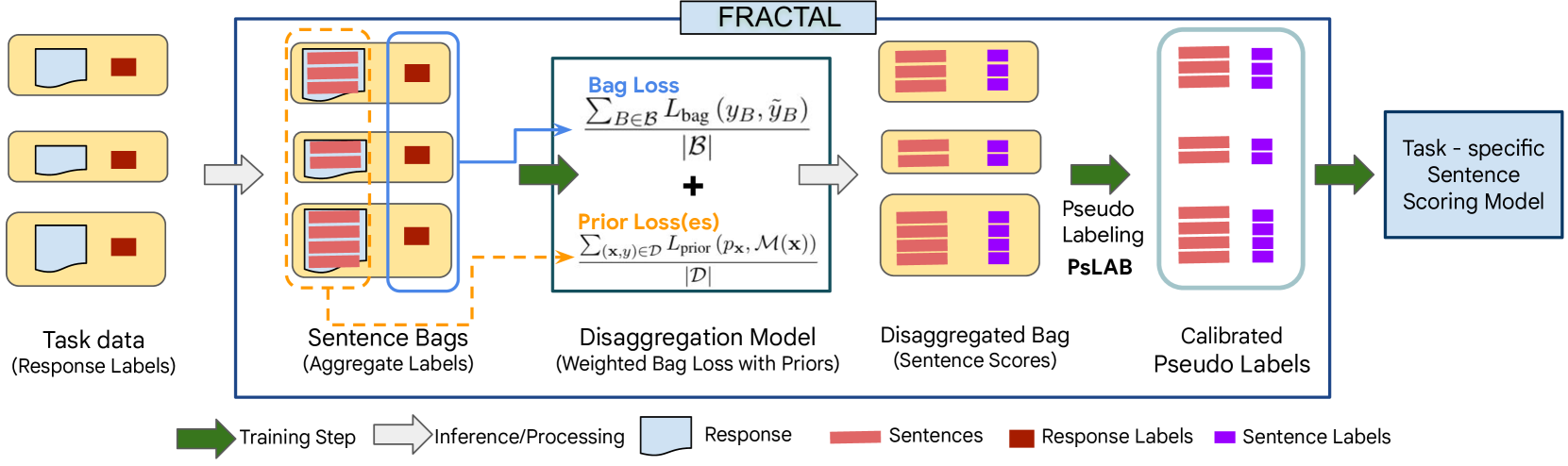
FRACTAL: Fine-Grained Scoring from Aggregate Text Labels
Yukti Makhija, Priyanka Agrawal, Rishi Saket, Aravindan Raghuveer
0
0
Large language models (LLMs) are being increasingly tuned to power complex generation tasks such as writing, fact-seeking, querying and reasoning. Traditionally, human or model feedback for evaluating and further tuning LLM performance has been provided at the response level, enabling faster and more cost-effective assessments. However, recent works (Amplayo et al. [2022], Wu et al. [2023]) indicate that sentence-level labels may provide more accurate and interpretable feedback for LLM optimization. In this work, we introduce methods to disaggregate response-level labels into sentence-level (pseudo-)labels. Our approach leverages multiple instance learning (MIL) and learning from label proportions (LLP) techniques in conjunction with prior information (e.g., document-sentence cosine similarity) to train a specialized model for sentence-level scoring. We also employ techniques which use model predictions to pseudo-label the train-set at the sentence-level for model training to further improve performance. We conduct extensive evaluations of our methods across six datasets and four tasks: retrieval, question answering, summarization, and math reasoning. Our results demonstrate improved performance compared to multiple baselines across most of these tasks. Our work is the first to develop response-level feedback to sentence-level scoring techniques, leveraging sentence-level prior information, along with comprehensive evaluations on multiple tasks as well as end-to-end finetuning evaluation showing performance comparable to a model trained on fine-grained human annotated labels.
4/9/2024