Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
2406.08463
0
0
Abstract
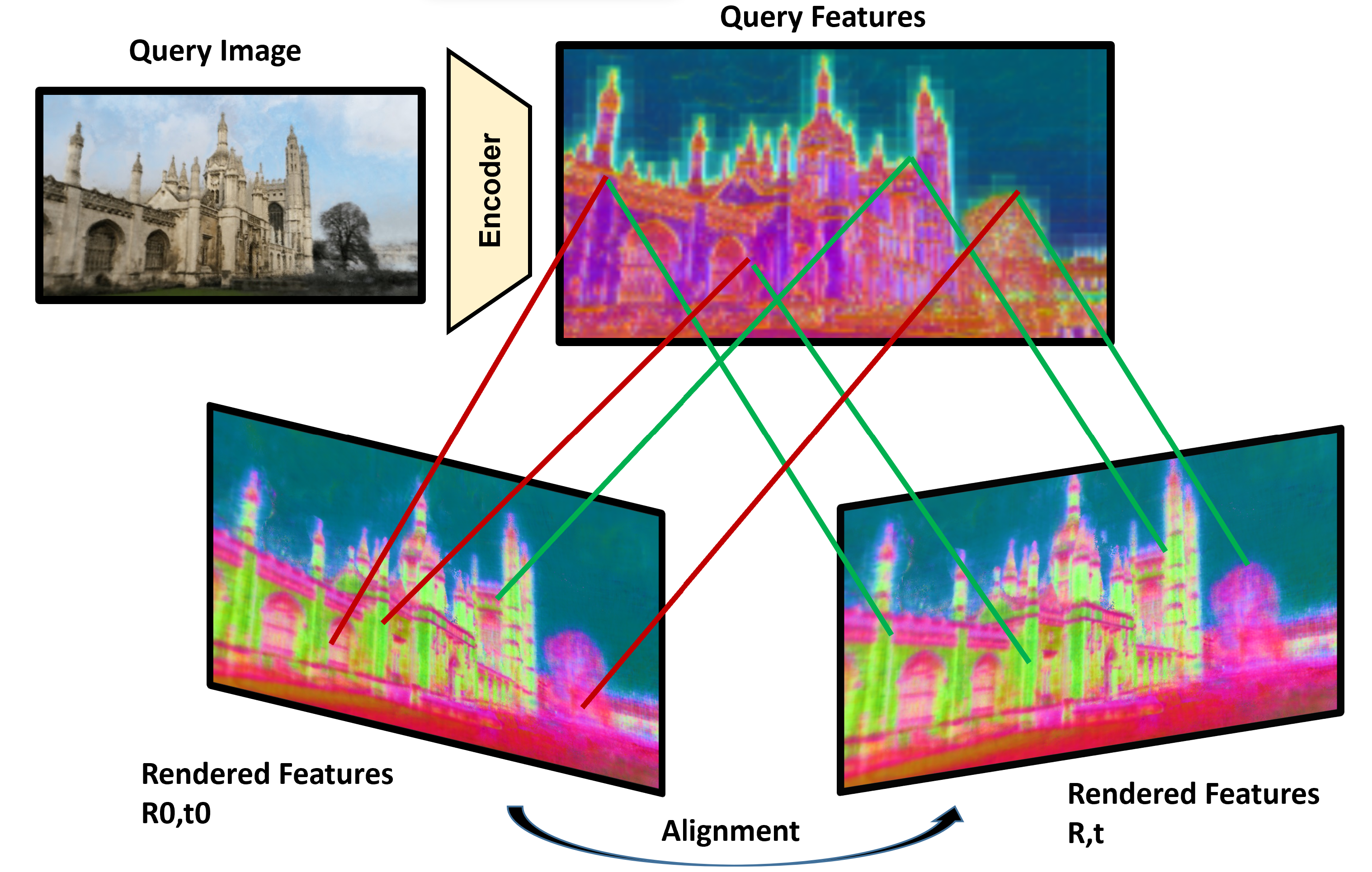
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
Create account to get full access
Overview
- The paper presents a self-supervised learning approach for refining camera pose estimation using neural implicit feature fields.
- It introduces a novel method to learn a neural feature field that captures the underlying scene structure, which is then used to refine the camera pose.
- The approach is demonstrated to outperform existing methods for camera pose refinement on various benchmark datasets.
Plain English Explanation
The paper describes a new way to improve the accuracy of camera pose estimation, which is the process of determining the position and orientation of a camera in a 3D scene. This is an important task in computer vision and augmented reality applications.
The key idea is to use a neural network to learn a "feature field" that captures the underlying structure of the 3D scene. This feature field is learned in a self-supervised way, meaning the network trains itself on the data without the need for human-labeled annotations.
Once the feature field is learned, it can be used to refine the estimated camera pose. The feature field contains information about the 3D scene that can help correct errors in the initial pose estimate. This results in more accurate camera poses compared to existing methods.
The approach is demonstrated to work well on several benchmark datasets, showing improvements over prior state-of-the-art techniques for camera pose refinement. This suggests the method could be useful for a variety of applications that rely on accurate 3D camera pose estimation.
Technical Explanation
The paper introduces a self-supervised learning approach for refining camera pose estimation using neural implicit feature fields. The method learns a neural feature field that captures the underlying 3D scene structure, which is then used to refine the estimated camera pose.
The architecture consists of a neural network that takes in the observed scene and outputs a feature field representing the 3D structure. This feature field is "implicit" in the sense that it is represented compactly using a neural network, rather than an explicit 3D mesh or point cloud.
The network is trained in a self-supervised manner, using the camera pose and observed scene as input, but without any human-labeled 3D annotations. The network learns to predict a feature field that is consistent with the input data, enabling it to capture the underlying scene structure.
During the pose refinement stage, the learned feature field is used to correct errors in the initial camera pose estimate. The network evaluates the feature field at the predicted 3D points to assess the consistency with the observed scene, and then updates the pose accordingly.
The proposed approach is evaluated on several benchmark datasets for camera pose estimation and refinement, and is shown to outperform existing state-of-the-art methods. The authors attribute this improvement to the ability of the neural feature field to capture rich scene-level information that helps correct errors in the initial pose estimate.
Critical Analysis
The paper presents a promising approach for camera pose refinement, with the key strength being the ability to learn a rich 3D feature representation in a self-supervised manner. This avoids the need for expensive 3D annotations, which can be a bottleneck for many 3D vision tasks.
However, the paper does not provide a detailed analysis of the limitations or failure cases of the proposed method. For example, it is unclear how the approach would perform in scenes with significant occlusions or dynamic elements, which could pose challenges for the feature field representation.
Additionally, the paper does not compare the computational efficiency of the method to other pose refinement techniques. This is an important consideration, as the added complexity of the neural feature field could potentially offset the performance gains in some real-world applications with strict latency requirements.
Further research could also explore ways to make the feature field representation more interpretable, perhaps by incorporating insights from [Internal Link: scene-coordinate-reconstruction-posing-image-collections-via] or [Internal Link: 3qfp-efficient-neural-implicit-surface-reconstruction-using]. This could lead to a better understanding of how the method works and ways to improve it.
Conclusion
The paper presents a novel self-supervised approach for camera pose refinement that learns a neural implicit feature field to capture the underlying 3D scene structure. This feature field is then used to correct errors in the initial pose estimate, resulting in improved performance on benchmark datasets.
The key contribution of the work is the ability to learn a rich 3D representation in a scalable, self-supervised manner, avoiding the need for expensive 3D annotations. This suggests the method could be widely applicable in various computer vision and augmented reality applications that rely on accurate camera pose estimation.
While the paper demonstrates promising results, further research is needed to better understand the method's limitations and explore ways to improve its efficiency and interpretability. Overall, the work represents an important step forward in the field of 3D scene understanding and camera pose refinement.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Incremental Joint Learning of Depth, Pose and Implicit Scene Representation on Monocular Camera in Large-scale Scenes
Tianchen Deng, Nailin Wang, Chongdi Wang, Shenghai Yuan, Jingchuan Wang, Danwei Wang, Weidong Chen
0
0
Dense scene reconstruction for photo-realistic view synthesis has various applications, such as VR/AR, autonomous vehicles. However, most existing methods have difficulties in large-scale scenes due to three core challenges: textit{(a) inaccurate depth input.} Accurate depth input is impossible to get in real-world large-scale scenes. textit{(b) inaccurate pose estimation.} Most existing approaches rely on accurate pre-estimated camera poses. textit{(c) insufficient scene representation capability.} A single global radiance field lacks the capacity to effectively scale to large-scale scenes. To this end, we propose an incremental joint learning framework, which can achieve accurate depth, pose estimation, and large-scale scene reconstruction. A vision transformer-based network is adopted as the backbone to enhance performance in scale information estimation. For pose estimation, a feature-metric bundle adjustment (FBA) method is designed for accurate and robust camera tracking in large-scale scenes. In terms of implicit scene representation, we propose an incremental scene representation method to construct the entire large-scale scene as multiple local radiance fields to enhance the scalability of 3D scene representation. Extended experiments have been conducted to demonstrate the effectiveness and accuracy of our method in depth estimation, pose estimation, and large-scale scene reconstruction.
4/10/2024
🖼️
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, 'Aron Monszpart, Daniyar Turmukhambetov, Victor Adrian Prisacariu
0
0
We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
4/23/2024

3QFP: Efficient neural implicit surface reconstruction using Tri-Quadtrees and Fourier feature Positional encoding
Shuo Sun, Malcolm Mielle, Achim J. Lilienthal, Martin Magnusson
0
0
Neural implicit surface representations are currently receiving a lot of interest as a means to achieve high-fidelity surface reconstruction at a low memory cost, compared to traditional explicit representations.However, state-of-the-art methods still struggle with excessive memory usage and non-smooth surfaces. This is particularly problematic in large-scale applications with sparse inputs, as is common in robotics use cases. To address these issues, we first introduce a sparse structure, emph{tri-quadtrees}, which represents the environment using learnable features stored in three planar quadtree projections. Secondly, we concatenate the learnable features with a Fourier feature positional encoding. The combined features are then decoded into signed distance values through a small multi-layer perceptron. We demonstrate that this approach facilitates smoother reconstruction with a higher completion ratio with fewer holes. Compared to two recent baselines, one implicit and one explicit, our approach requires only 10%--50% as much memory, while achieving competitive quality.
4/9/2024
MVSBoost: An Efficient Point Cloud-based 3D Reconstruction
Umair Haroon, Ahmad AlMughrabi, Ricardo Marques, Petia Radeva
0
0
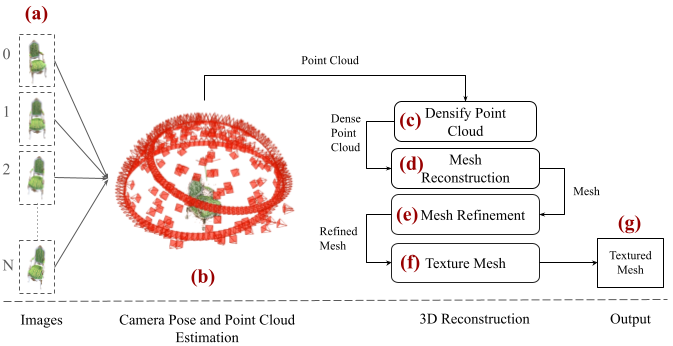
Efficient and accurate 3D reconstruction is crucial for various applications, including augmented and virtual reality, medical imaging, and cinematic special effects. While traditional Multi-View Stereo (MVS) systems have been fundamental in these applications, using neural implicit fields in implicit 3D scene modeling has introduced new possibilities for handling complex topologies and continuous surfaces. However, neural implicit fields often suffer from computational inefficiencies, overfitting, and heavy reliance on data quality, limiting their practical use. This paper presents an enhanced MVS framework that integrates multi-view 360-degree imagery with robust camera pose estimation via Structure from Motion (SfM) and advanced image processing for point cloud densification, mesh reconstruction, and texturing. Our approach significantly improves upon traditional MVS methods, offering superior accuracy and precision as validated using Chamfer distance metrics on the Realistic Synthetic 360 dataset. The developed MVS technique enhances the detail and clarity of 3D reconstructions and demonstrates superior computational efficiency and robustness in complex scene reconstruction, effectively handling occlusions and varying viewpoints. These improvements suggest that our MVS framework can compete with and potentially exceed current state-of-the-art neural implicit field methods, especially in scenarios requiring real-time processing and scalability.
6/21/2024