Inducing Group Fairness in LLM-Based Decisions
2406.16738
0
0
Abstract
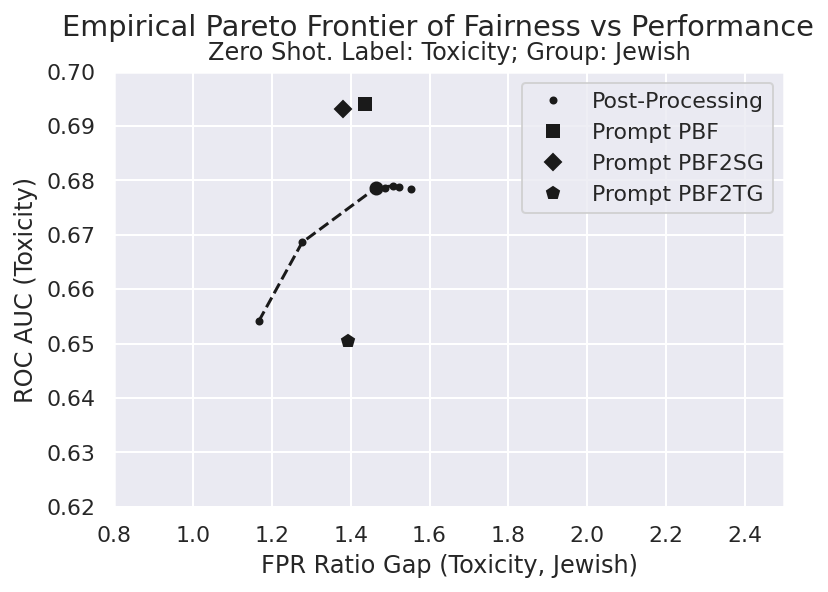
Prompting Large Language Models (LLMs) has created new and interesting means for classifying textual data. While evaluating and remediating group fairness is a well-studied problem in classifier fairness literature, some classical approaches (e.g., regularization) do not carry over, and some new opportunities arise (e.g., prompt-based remediation). We measure fairness of LLM-based classifiers on a toxicity classification task, and empirically show that prompt-based classifiers may lead to unfair decisions. We introduce several remediation techniques and benchmark their fairness and performance trade-offs. We hope our work encourages more research on group fairness in LLM-based classifiers.
Create account to get full access
Overview
- This paper explores techniques for inducing group fairness in decisions made by large language models (LLMs).
- The authors propose a framework for incorporating group fairness constraints into LLM-based decision-making processes.
- They demonstrate the effectiveness of their approach through experiments on real-world datasets.
Plain English Explanation
Large language models (LLMs) like ChatGPT have become increasingly prominent in a wide range of applications, from text generation to decision-making. However, these models can exhibit biases that lead to unfair outcomes for certain groups of people.
The authors of this paper aim to address this issue by developing techniques to make LLM-based decisions more fair. They propose a framework that allows you to specify the desired level of fairness for different groups, and then incorporates these fairness constraints into the decision-making process.
Imagine you're using an LLM to help make hiring decisions. You might want to ensure that the model's recommendations are equally fair for applicants from different racial or gender backgrounds. The authors' framework would allow you to define these fairness constraints and then apply them to the LLM's decision-making, helping to mitigate any biases that might otherwise creep in.
Through experiments on real-world datasets, the authors demonstrate that their approach can effectively induce group fairness in LLM-based decisions, while still maintaining the models' overall performance. This is an important step towards developing more equitable AI systems that can be deployed in sensitive applications.
Technical Explanation
The key elements of the paper are:
-
Fairness Constraints: The authors define a set of group fairness constraints that can be incorporated into the LLM decision-making process. These constraints specify the desired level of fairness for different demographic groups.
-
Optimization Formulation: The authors formulate the problem of inducing group fairness as an optimization problem, where the goal is to find the LLM parameters that minimize the overall decision loss while satisfying the fairness constraints.
-
Optimization Approach: To solve this optimization problem, the authors use a constrained optimization technique that alternates between updating the LLM parameters and adjusting the Lagrange multipliers associated with the fairness constraints.
-
Experimental Evaluation: The authors evaluate their approach on real-world datasets, including a job applicant dataset and a credit risk assessment dataset. They compare the performance and fairness of their approach to baseline methods and demonstrate its effectiveness in inducing group fairness.
Critical Analysis
The authors acknowledge several limitations and areas for future research:
- The proposed framework relies on the availability of sensitive demographic attributes, which may not always be present or accurately recorded in real-world datasets.
- The authors focus on group-level fairness, but individual-level fairness is also an important consideration that is not explicitly addressed in this work.
- The optimization approach used in the paper may not scale well to very large LLMs or complex decision tasks, and further research is needed to improve its computational efficiency.
Additionally, one could argue that the authors' approach, while effective in improving group fairness, may come at the cost of overall model performance. In some applications, there may be a difficult tradeoff between fairness and accuracy that needs to be carefully considered.
Conclusion
This paper presents an important contribution to the growing field of fair AI, offering a practical framework for inducing group fairness in LLM-based decision-making. By incorporating fairness constraints into the optimization process, the authors demonstrate a way to mitigate biases in LLM outputs and work towards more equitable AI systems.
As LLMs continue to be deployed in high-stakes applications, such as hiring, lending, and healthcare, the ability to ensure fairness will be crucial. The techniques described in this paper provide a promising step in that direction, though further research is needed to address the limitations and scale the approach to more complex real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
The Impossibility of Fair LLMs
Jacy Anthis, Kristian Lum, Michael Ekstrand, Avi Feller, Alexander D'Amour, Chenhao Tan
0
0
The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
6/6/2024
💬
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
4/3/2024
🐍
Fairness of ChatGPT
Yunqi Li, Lanjing Zhang, Yongfeng Zhang
0
0
Understanding and addressing unfairness in LLMs are crucial for responsible AI deployment. However, there is a limited number of quantitative analyses and in-depth studies regarding fairness evaluations in LLMs, especially when applying LLMs to high-stakes fields. This work aims to fill this gap by providing a systematic evaluation of the effectiveness and fairness of LLMs using ChatGPT as a study case. We focus on assessing ChatGPT's performance in high-takes fields including education, criminology, finance and healthcare. To conduct a thorough evaluation, we consider both group fairness and individual fairness metrics. We also observe the disparities in ChatGPT's outputs under a set of biased or unbiased prompts. This work contributes to a deeper understanding of LLMs' fairness performance, facilitates bias mitigation and fosters the development of responsible AI systems.
5/7/2024
💬
Confronting LLMs with Traditional ML: Rethinking the Fairness of Large Language Models in Tabular Classifications
Yanchen Liu, Srishti Gautam, Jiaqi Ma, Himabindu Lakkaraju
0
0
Recent literature has suggested the potential of using large language models (LLMs) to make classifications for tabular tasks. However, LLMs have been shown to exhibit harmful social biases that reflect the stereotypes and inequalities present in society. To this end, as well as the widespread use of tabular data in many high-stake applications, it is important to explore the following questions: what sources of information do LLMs draw upon when making classifications for tabular tasks; whether and to what extent are LLM classifications for tabular data influenced by social biases and stereotypes; and what are the consequential implications for fairness? Through a series of experiments, we delve into these questions and show that LLMs tend to inherit social biases from their training data which significantly impact their fairness in tabular classification tasks. Furthermore, our investigations show that in the context of bias mitigation, though in-context learning and finetuning have a moderate effect, the fairness metric gap between different subgroups is still larger than that in traditional machine learning models, such as Random Forest and shallow Neural Networks. This observation emphasizes that the social biases are inherent within the LLMs themselves and inherited from their pretraining corpus, not only from the downstream task datasets. Besides, we demonstrate that label-flipping of in-context examples can significantly reduce biases, further highlighting the presence of inherent bias within LLMs.
4/4/2024