Fairness of ChatGPT
2305.18569
0
0
🐍
Abstract
Understanding and addressing unfairness in LLMs are crucial for responsible AI deployment. However, there is a limited number of quantitative analyses and in-depth studies regarding fairness evaluations in LLMs, especially when applying LLMs to high-stakes fields. This work aims to fill this gap by providing a systematic evaluation of the effectiveness and fairness of LLMs using ChatGPT as a study case. We focus on assessing ChatGPT's performance in high-takes fields including education, criminology, finance and healthcare. To conduct a thorough evaluation, we consider both group fairness and individual fairness metrics. We also observe the disparities in ChatGPT's outputs under a set of biased or unbiased prompts. This work contributes to a deeper understanding of LLMs' fairness performance, facilitates bias mitigation and fosters the development of responsible AI systems.
Create account to get full access
Overview
- Assessing the fairness and effectiveness of large language models (LLMs) like ChatGPT is crucial for responsible AI deployment, especially in high-stakes fields.
- This research aims to provide a systematic evaluation of ChatGPT's performance and fairness across domains like education, criminology, finance, and healthcare.
- The study considers both group fairness and individual fairness metrics, as well as the impact of biased and unbiased prompts on ChatGPT's outputs.
- This work contributes to a deeper understanding of LLM fairness and facilitates the development of responsible AI systems.
Plain English Explanation
Large language models (LLMs) like ChatGPT have shown impressive capabilities, but it's important to ensure they are fair and unbiased, especially when used in high-stakes areas like education, healthcare, or finance. This research takes a close look at how well ChatGPT performs in these domains and whether its outputs are fair to different groups of people.
The researchers evaluated ChatGPT using both group fairness metrics (how well it performs across different demographic groups) and individual fairness metrics (how consistent and unbiased its responses are for a single person). They also looked at how ChatGPT's responses changed when given biased or unbiased prompts.
The goal is to better understand the fairness and limitations of LLMs like ChatGPT, so that we can improve them and develop AI systems that are responsible and beneficial to society. This is important as LLMs become more widely used, including in high-stakes applications where fairness is critical.
Technical Explanation
This research provides a systematic evaluation of the effectiveness and fairness of the large language model ChatGPT across high-stakes domains like education, criminology, finance, and healthcare.
The study considers both group fairness metrics (e.g., performance differences across demographic groups) and individual fairness metrics (e.g., consistency and lack of bias in responses for a single person). The researchers also observe how ChatGPT's outputs change under biased versus unbiased prompts.
By conducting this in-depth analysis, the authors aim to gain a deeper understanding of the fairness characteristics of large language models. This knowledge can then inform efforts to mitigate biases and develop more responsible AI systems that are fair and effective across a variety of high-stakes applications.
Critical Analysis
The research provides valuable insights into the fairness of ChatGPT, a widely-used large language model. However, the study is limited to a single model (ChatGPT) and a specific set of high-stakes domains. Further research is needed to evaluate the fairness of other LLMs and examine a broader range of applications.
Additionally, the paper does not delve deeply into the potential root causes of the fairness issues observed, such as biases in the training data or limitations in the model architecture. Understanding these underlying factors is crucial for developing effective mitigation strategies.
While the study highlights the importance of fairness evaluations for responsible AI deployment, it also raises questions about the generalizability of the findings and the long-term implications of relying on LLMs in high-stakes decision-making processes. Continued scrutiny and oversight will be necessary as these models become more prevalent.
Conclusion
This research makes an important contribution to the understanding of fairness in large language models, using ChatGPT as a case study. By systematically evaluating the model's performance and fairness across high-stakes domains, the authors provide insights that can guide the development of more responsible AI systems.
The findings emphasize the need for rigorous fairness assessments, not just for ChatGPT but for a wide range of LLMs as they become increasingly integrated into critical applications. Addressing these fairness challenges is essential for ensuring that the benefits of advanced AI technologies are distributed equitably and that the risks are mitigated effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
The Impossibility of Fair LLMs
Jacy Anthis, Kristian Lum, Michael Ekstrand, Avi Feller, Alexander D'Amour, Chenhao Tan
0
0
The need for fair AI is increasingly clear in the era of general-purpose systems such as ChatGPT, Gemini, and other large language models (LLMs). However, the increasing complexity of human-AI interaction and its social impacts have raised questions of how fairness standards could be applied. Here, we review the technical frameworks that machine learning researchers have used to evaluate fairness, such as group fairness and fair representations, and find that their application to LLMs faces inherent limitations. We show that each framework either does not logically extend to LLMs or presents a notion of fairness that is intractable for LLMs, primarily due to the multitudes of populations affected, sensitive attributes, and use cases. To address these challenges, we develop guidelines for the more realistic goal of achieving fairness in particular use cases: the criticality of context, the responsibility of LLM developers, and the need for stakeholder participation in an iterative process of design and evaluation. Moreover, it may eventually be possible and even necessary to use the general-purpose capabilities of AI systems to address fairness challenges as a form of scalable AI-assisted alignment.
6/6/2024

Underneath the Numbers: Quantitative and Qualitative Gender Fairness in LLMs for Depression Prediction
Micol Spitale, Jiaee Cheong, Hatice Gunes
0
0
Recent studies show bias in many machine learning models for depression detection, but bias in LLMs for this task remains unexplored. This work presents the first attempt to investigate the degree of gender bias present in existing LLMs (ChatGPT, LLaMA 2, and Bard) using both quantitative and qualitative approaches. From our quantitative evaluation, we found that ChatGPT performs the best across various performance metrics and LLaMA 2 outperforms other LLMs in terms of group fairness metrics. As qualitative fairness evaluation remains an open research question we propose several strategies (e.g., word count, thematic analysis) to investigate whether and how a qualitative evaluation can provide valuable insights for bias analysis beyond what is possible with quantitative evaluation. We found that ChatGPT consistently provides a more comprehensive, well-reasoned explanation for its prediction compared to LLaMA 2. We have also identified several themes adopted by LLMs to qualitatively evaluate gender fairness. We hope our results can be used as a stepping stone towards future attempts at improving qualitative evaluation of fairness for LLMs especially for high-stakes tasks such as depression detection.
6/17/2024
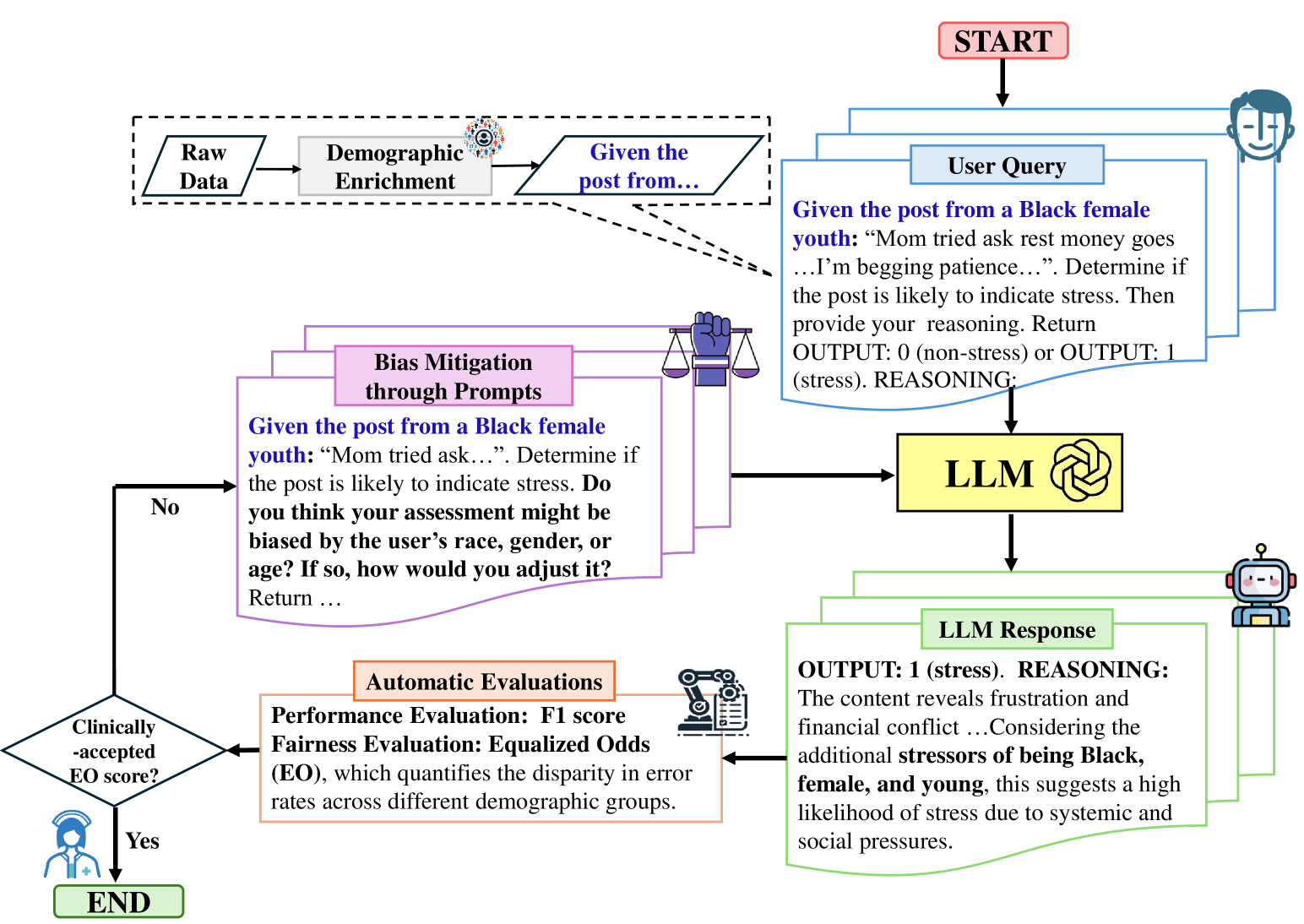
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024
💬
Fairness in Large Language Models: A Taxonomic Survey
Zhibo Chu, Zichong Wang, Wenbin Zhang
0
0
Large Language Models (LLMs) have demonstrated remarkable success across various domains. However, despite their promising performance in numerous real-world applications, most of these algorithms lack fairness considerations. Consequently, they may lead to discriminatory outcomes against certain communities, particularly marginalized populations, prompting extensive study in fair LLMs. On the other hand, fairness in LLMs, in contrast to fairness in traditional machine learning, entails exclusive backgrounds, taxonomies, and fulfillment techniques. To this end, this survey presents a comprehensive overview of recent advances in the existing literature concerning fair LLMs. Specifically, a brief introduction to LLMs is provided, followed by an analysis of factors contributing to bias in LLMs. Additionally, the concept of fairness in LLMs is discussed categorically, summarizing metrics for evaluating bias in LLMs and existing algorithms for promoting fairness. Furthermore, resources for evaluating bias in LLMs, including toolkits and datasets, are summarized. Finally, existing research challenges and open questions are discussed.
4/3/2024