INDUS: Effective and Efficient Language Models for Scientific Applications

0
Sign in to get full access
Overview
- The paper discusses the development of "indus", a language model designed for scientific applications that is effective and efficient.
- The model is trained on a large corpus of scientific literature to improve its performance on tasks relevant to scientific research.
- The paper evaluates the model's performance on various benchmarks and compares it to other state-of-the-art language models.
Plain English Explanation
The researchers have created a new language model called "indus" that is particularly well-suited for scientific applications. Language models are artificial intelligence systems that can understand and generate human language. The researchers trained indus on a vast collection of scientific papers and articles, which allows it to better comprehend and work with the specialized language and concepts used in scientific fields.
[This research builds on recent advancements in large language models, such as those described in the paper "Unraveling Dominance in Large Language Models over Transformer" (https://aimodels.fyi/papers/arxiv/unraveling-dominance-large-language-models-over-transformer).] The researchers evaluated indus on a variety of benchmarks, which are standardized tests designed to measure the performance of language models on different tasks. They found that indus outperformed other leading language models, particularly on scientific and technical applications.
The development of indus is an important step forward, as it demonstrates how language models can be tailored to specific domains, in this case the field of science. This could lead to more effective and efficient tools for scientists and researchers to utilize in their work, such as [the healthcare language model discussed in "Developing Healthcare Language Model Embedding Spaces" (https://aimodels.fyi/papers/arxiv/developing-healthcare-language-model-embedding-spaces)]. By focusing on the unique needs and requirements of the scientific community, the indus model can potentially enhance productivity, facilitate collaboration, and accelerate scientific discovery.
Technical Explanation
The researchers trained the indus language model on a large corpus of scientific literature, including journal articles, preprints, and other technical documents. This allowed the model to develop a deep understanding of scientific terminology, concepts, and discourse patterns. [The researchers note that this approach builds on the insights from "Large Language Models for Expansion of Spoken Language Understanding" (https://aimodels.fyi/papers/arxiv/large-language-models-expansion-spoken-language-understanding), which explored how language models can be expanded to new domains.]
The indus model was evaluated on a range of benchmarks, including tasks such as scientific text summarization, question answering, and knowledge extraction. The researchers found that indus outperformed other state-of-the-art language models, including domain-general models like GPT-3 and specialized scientific models, on these scientific-focused tasks. [This aligns with the findings of "Supervised Knowledge Makes Large Language Models Better" (https://aimodels.fyi/papers/arxiv/supervised-knowledge-makes-large-language-models-better), which demonstrated the benefits of incorporating domain-specific knowledge into language models.]
One key aspect of the indus model is its efficiency, both in terms of training time and inference speed. The researchers used techniques like parameter sharing and model distillation to reduce the model's size and computational requirements without significantly impacting its performance. This makes indus a more practical and accessible option for researchers and scientists who may have limited computational resources.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. For example, the indus model was trained on a primarily English-language corpus, so its performance on non-English scientific literature may be less robust. Additionally, the benchmarks used to evaluate the model, while representative of common scientific tasks, may not capture the full breadth of real-world scientific applications.
[While the indus model represents an important advancement in scientific language modeling, as discussed in "GeoGalactica: A Scientific Large Language Model for Geoscience" (https://aimodels.fyi/papers/arxiv/geogalactica-scientific-large-language-model-geoscience), further research is needed to address the unique challenges and requirements of different scientific domains. Incorporating domain-specific knowledge and adaptations may be necessary to fully unlock the potential of language models in various scientific fields.]
Conclusion
The indus language model developed by the researchers represents a significant step forward in creating effective and efficient language models for scientific applications. By training the model on a large corpus of scientific literature, the researchers were able to improve its performance on a range of scientific tasks, making it a valuable tool for researchers and scientists.
The development of indus highlights the potential for language models to be tailored to specific domains, and the researchers' emphasis on efficiency and accessibility ensures that the model can be widely adopted and utilized. As the field of natural language processing continues to advance, models like indus will play an increasingly important role in accelerating scientific discovery and innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
INDUS: Effective and Efficient Language Models for Scientific Applications
Bishwaranjan Bhattacharjee, Aashka Trivedi, Masayasu Muraoka, Muthukumaran Ramasubramanian, Takuma Udagawa, Iksha Gurung, Rong Zhang, Bharath Dandala, Rahul Ramachandran, Manil Maskey, Kaylin Bugbee, Mike Little, Elizabeth Fancher, Lauren Sanders, Sylvain Costes, Sergi Blanco-Cuaresma, Kelly Lockhart, Thomas Allen, Felix Grezes, Megan Ansdell, Alberto Accomazzi, Yousef El-Kurdi, Davis Wertheimer, Birgit Pfitzmann, Cesar Berrospi Ramis, Michele Dolfi, Rafael Teixeira de Lima, Panagiotis Vagenas, S. Karthik Mukkavilli, Peter Staar, Sanaz Vahidinia, Ryan McGranaghan, Armin Mehrabian, Tsendgar Lee
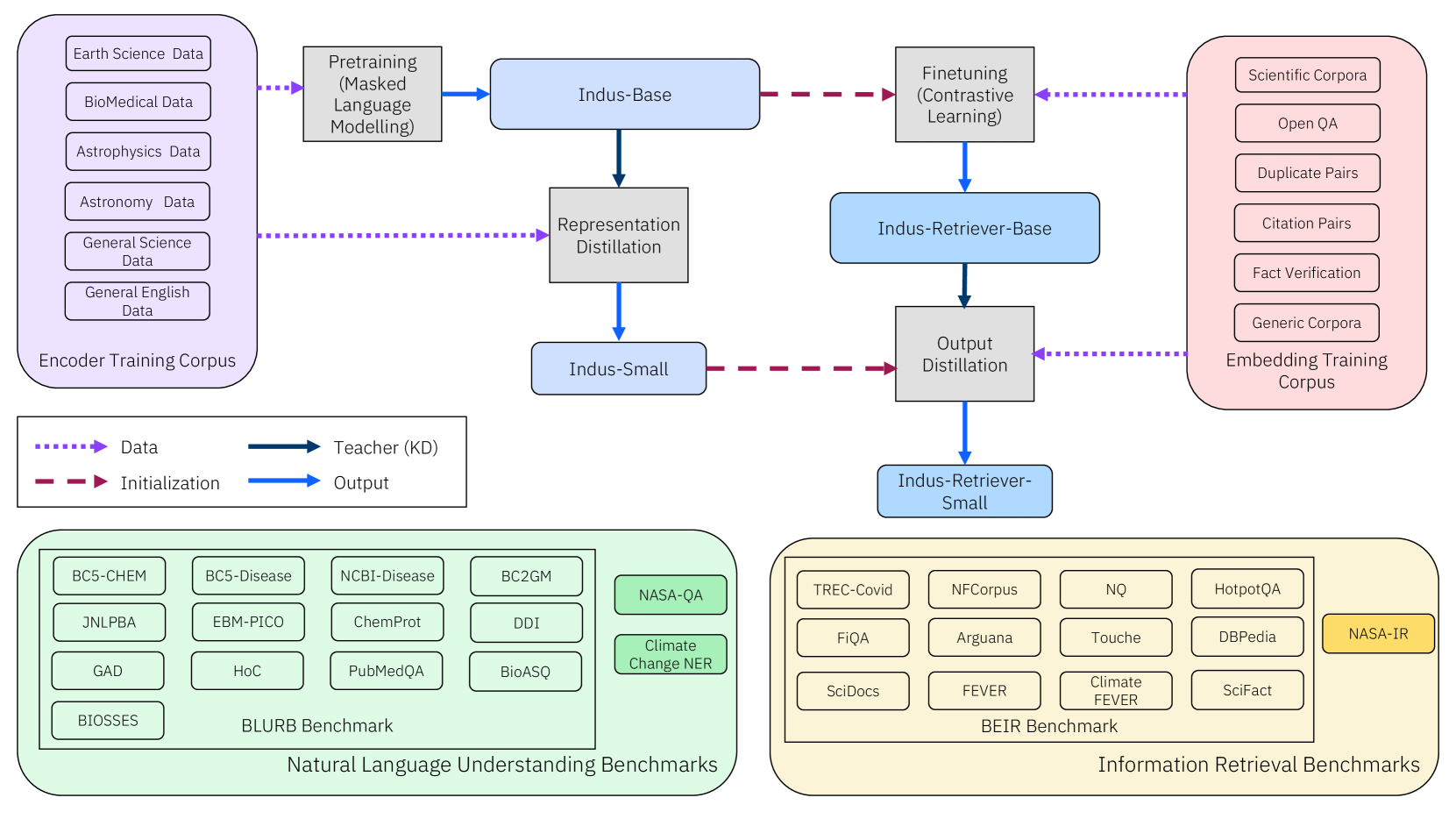
Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Read more5/22/2024
0
Towards Efficient Large Language Models for Scientific Text: A Review
Huy Quoc To, Ming Liu, Guangyan Huang
Large language models (LLMs) have ushered in a new era for processing complex information in various fields, including science. The increasing amount of scientific literature allows these models to acquire and understand scientific knowledge effectively, thus improving their performance in a wide range of tasks. Due to the power of LLMs, they require extremely expensive computational resources, intense amounts of data, and training time. Therefore, in recent years, researchers have proposed various methodologies to make scientific LLMs more affordable. The most well-known approaches align in two directions. It can be either focusing on the size of the models or enhancing the quality of data. To date, a comprehensive review of these two families of methods has not yet been undertaken. In this paper, we (I) summarize the current advances in the emerging abilities of LLMs into more accessible AI solutions for science, and (II) investigate the challenges and opportunities of developing affordable solutions for scientific domains using LLMs.
Read more8/21/2024

0
A Comprehensive Survey of Scientific Large Language Models and Their Applications in Scientific Discovery
Yu Zhang, Xiusi Chen, Bowen Jin, Sheng Wang, Shuiwang Ji, Wei Wang, Jiawei Han
In many scientific fields, large language models (LLMs) have revolutionized the way text and other modalities of data (e.g., molecules and proteins) are handled, achieving superior performance in various applications and augmenting the scientific discovery process. Nevertheless, previous surveys on scientific LLMs often concentrate on one or two fields or a single modality. In this paper, we aim to provide a more holistic view of the research landscape by unveiling cross-field and cross-modal connections between scientific LLMs regarding their architectures and pre-training techniques. To this end, we comprehensively survey over 250 scientific LLMs, discuss their commonalities and differences, as well as summarize pre-training datasets and evaluation tasks for each field and modality. Moreover, we investigate how LLMs have been deployed to benefit scientific discovery. Resources related to this survey are available at https://github.com/yuzhimanhua/Awesome-Scientific-Language-Models.
Read more8/27/2024
💬
0
Efficient Large Language Models: A Survey
Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, Mosharaf Chowdhury, Mi Zhang
Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding and language generation, and thus have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we organize the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey. We will actively maintain the repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of efficient LLMs research and inspire them to contribute to this important and exciting field.
Read more5/24/2024