Inference Optimization of Foundation Models on AI Accelerators

0
Sign in to get full access
Overview
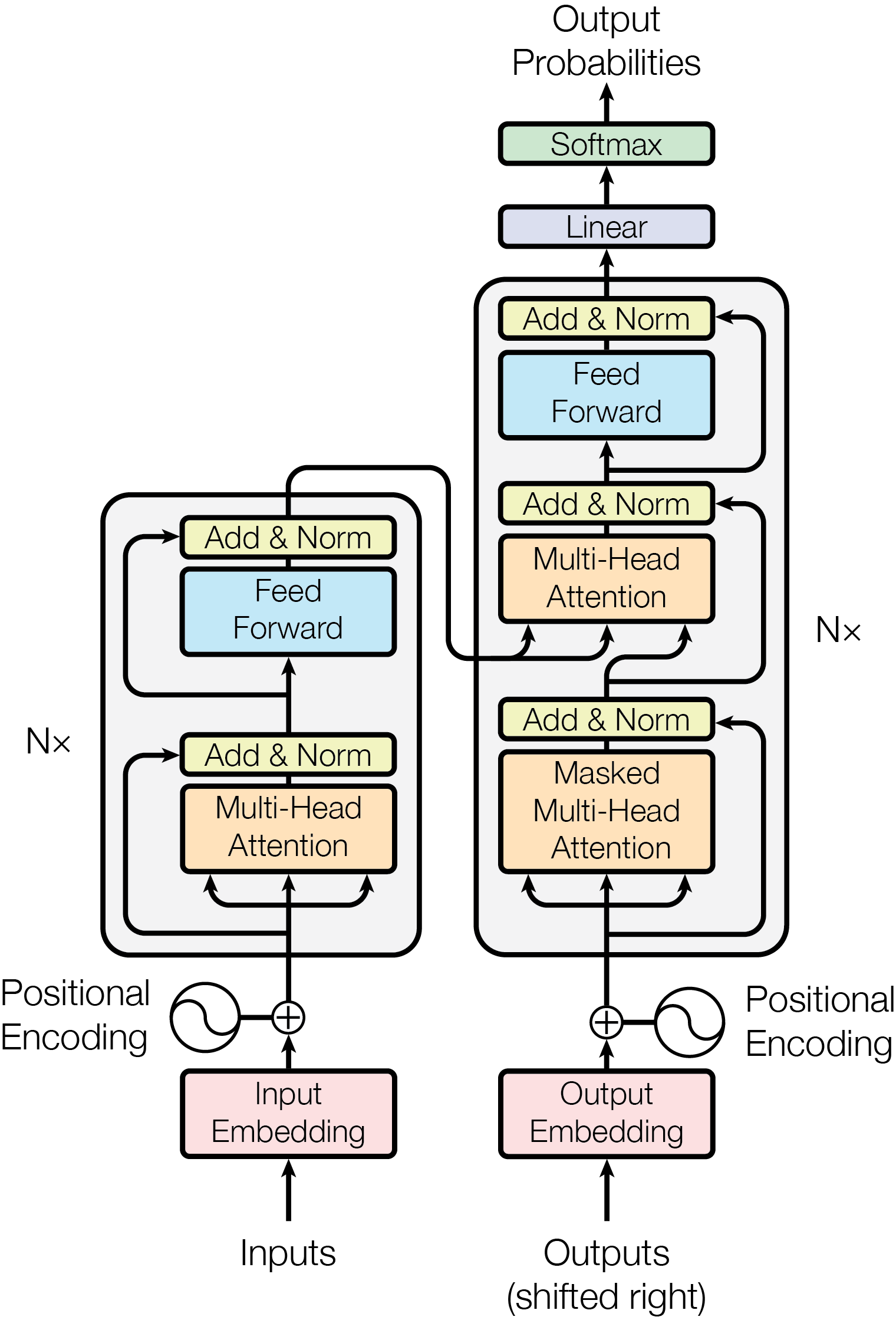
- Inference optimization of large language models (LLMs) and foundation models on AI accelerators
- Importance of efficient inference for real-world applications of these powerful AI models
- Challenges in achieving high performance on diverse hardware
- Potential solutions explored in the research paper
Plain English Explanation
The paper discusses the challenge of efficiently running inference (the process of using a trained AI model to make predictions or decisions) for large language models (LLMs) and foundation models on different types of AI hardware accelerators. LLMs and foundation models are powerful AI systems that can perform a wide variety of tasks, from answering questions to generating human-like text. However, running these models to make predictions in real-world applications can be computationally intensive and requires optimizing the inference process to get the best performance.
The researchers explore various techniques to optimize the inference of LLMs and foundation models on different AI accelerators, such as graphics processing units (GPUs) and specialized AI chips. This is important because these models need to work efficiently on diverse hardware to be deployed in practical applications like chatbots, digital assistants, and content generation tools.
The paper investigates strategies like memory-efficient architectures, model compression, and optimizing for many small AI cores to improve the inference performance of these large and complex models on different types of hardware. The goal is to make the deployment and use of LLMs and foundation models more practical and accessible for a wide range of real-world applications.
Technical Explanation
The paper explores various techniques to optimize the inference of large language models (LLMs) and foundation models on different AI accelerators, such as GPUs and specialized AI chips. The researchers investigate strategies like:
-
Memory-efficient architectures: Exploring model architectures that are more memory-efficient during inference, reducing the overall memory footprint and allowing for faster processing on hardware with limited memory resources.
-
Model compression: Applying techniques like quantization and pruning to compress the size of the models, enabling faster inference without significant loss in accuracy.
-
Optimizing for many small AI cores: Investigating ways to efficiently utilize the many small processing cores found in some specialized AI hardware, rather than relying solely on a few powerful cores.
The paper presents experiments and analysis to understand the trade-offs and performance characteristics of these different optimization approaches across a range of AI accelerator hardware. The findings aim to provide insights and guidance for practitioners working on deploying large, powerful AI models in real-world applications.
Critical Analysis
The paper provides a comprehensive exploration of inference optimization techniques for LLMs and foundation models, addressing the important challenge of making these powerful AI systems more accessible and practical for real-world deployment. The researchers have carefully designed experiments to evaluate the trade-offs between different optimization strategies and hardware configurations.
However, the paper does not address potential limitations or caveats of the proposed approaches. For example, it does not discuss the impact of model compression on the model's performance or the long-term reliability of the optimized models. Additionally, the paper could have explored the energy efficiency and environmental impact of the different inference optimization strategies, as this is an increasingly important consideration in the development of AI systems.
Further research could also investigate the generalization of these optimization techniques to a wider range of AI models and applications, as well as the potential for combining multiple optimization strategies to achieve even greater inference performance.
Conclusion
This research paper makes a valuable contribution to the field of efficient inference for large language models and foundation models. By exploring various optimization techniques and evaluating their performance on different AI accelerators, the researchers provide insights and guidance that can help make these powerful AI systems more practical and accessible for real-world applications.
The findings from this work could have significant implications for the development and deployment of advanced AI technologies, enabling more efficient and widespread use of LLMs and foundation models in areas such as natural language processing, content generation, and decision-making. As the demand for these AI models continues to grow, the optimization strategies discussed in this paper will become increasingly important for ensuring the scalability and practicality of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Inference Optimization of Foundation Models on AI Accelerators
Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kubler, Jiaji Huang, Matthaus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis
Powerful foundation models, including large language models (LLMs), with Transformer architectures have ushered in a new era of Generative AI across various industries. Industry and research community have witnessed a large number of new applications, based on those foundation models. Such applications include question and answer, customer services, image and video generation, and code completions, among others. However, as the number of model parameters reaches to hundreds of billions, their deployment incurs prohibitive inference costs and high latency in real-world scenarios. As a result, the demand for cost-effective and fast inference using AI accelerators is ever more higher. To this end, our tutorial offers a comprehensive discussion on complementary inference optimization techniques using AI accelerators. Beginning with an overview of basic Transformer architectures and deep learning system frameworks, we deep dive into system optimization techniques for fast and memory-efficient attention computations and discuss how they can be implemented efficiently on AI accelerators. Next, we describe architectural elements that are key for fast transformer inference. Finally, we examine various model compression and fast decoding strategies in the same context.
Read more7/15/2024
🤯
0
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
Read more4/10/2024

0
Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference
Christopher Wolters, Xiaoxuan Yang, Ulf Schlichtmann, Toyotaro Suzumura
Large language models (LLMs) have recently transformed natural language processing, enabling machines to generate human-like text and engage in meaningful conversations. This development necessitates speed, efficiency, and accessibility in LLM inference as the computational and memory requirements of these systems grow exponentially. Meanwhile, advancements in computing and memory capabilities are lagging behind, exacerbated by the discontinuation of Moore's law. With LLMs exceeding the capacity of single GPUs, they require complex, expert-level configurations for parallel processing. Memory accesses become significantly more expensive than computation, posing a challenge for efficient scaling, known as the memory wall. Here, compute-in-memory (CIM) technologies offer a promising solution for accelerating AI inference by directly performing analog computations in memory, potentially reducing latency and power consumption. By closely integrating memory and compute elements, CIM eliminates the von Neumann bottleneck, reducing data movement and improving energy efficiency. This survey paper provides an overview and analysis of transformer-based models, reviewing various CIM architectures and exploring how they can address the imminent challenges of modern AI computing systems. We discuss transformer-related operators and their hardware acceleration schemes and highlight challenges, trends, and insights in corresponding CIM designs.
Read more6/13/2024
🛠️
0
Efficiency optimization of large-scale language models based on deep learning in natural language processing tasks
Taiyuan Mei, Yun Zi, Xiaohan Cheng, Zijun Gao, Qi Wang, Haowei Yang
The internal structure and operation mechanism of large-scale language models are analyzed theoretically, especially how Transformer and its derivative architectures can restrict computing efficiency while capturing long-term dependencies. Further, we dig deep into the efficiency bottleneck of the training phase, and evaluate in detail the contribution of adaptive optimization algorithms (such as AdamW), massively parallel computing techniques, and mixed precision training strategies to accelerate convergence and reduce memory footprint. By analyzing the mathematical principles and implementation details of these algorithms, we reveal how they effectively improve training efficiency in practice. In terms of model deployment and inference optimization, this paper systematically reviews the latest advances in model compression techniques, focusing on strategies such as quantification, pruning, and knowledge distillation. By comparing the theoretical frameworks of these techniques and their effects in different application scenarios, we demonstrate their ability to significantly reduce model size and inference delay while maintaining model prediction accuracy. In addition, this paper critically examines the limitations of current efficiency optimization methods, such as the increased risk of overfitting, the control of performance loss after compression, and the problem of algorithm generality, and proposes some prospects for future research. In conclusion, this study provides a comprehensive theoretical framework for understanding the efficiency optimization of large-scale language models.
Read more5/21/2024