Inference via Interpolation: Contrastive Representations Provably Enable Planning and Inference
2403.04082
1
0
Abstract
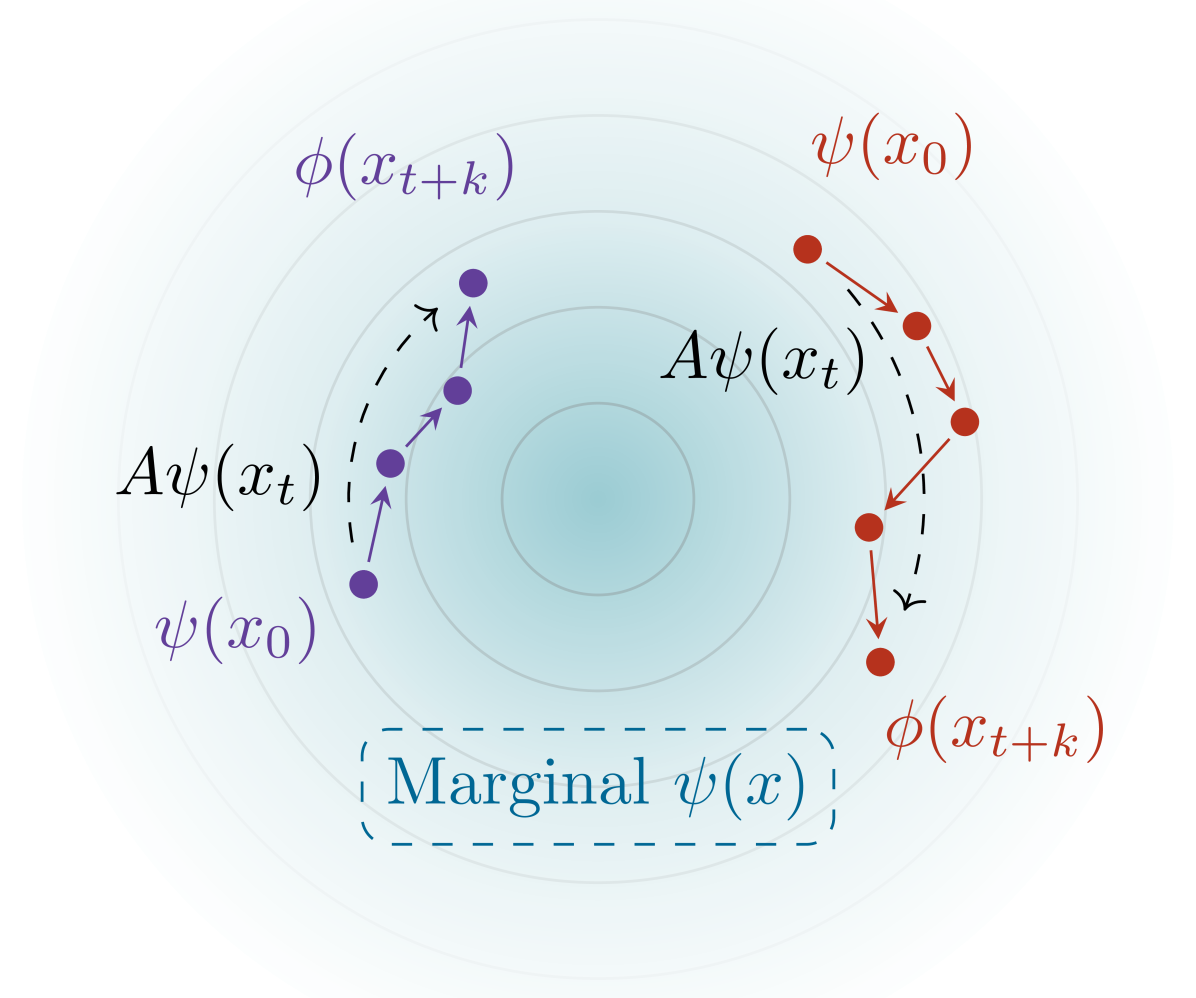
Given time series data, how can we answer questions like what will happen in the future? and how did we get here? These sorts of probabilistic inference questions are challenging when observations are high-dimensional. In this paper, we show how these questions can have compact, closed form solutions in terms of learned representations. The key idea is to apply a variant of contrastive learning to time series data. Prior work already shows that the representations learned by contrastive learning encode a probability ratio. By extending prior work to show that the marginal distribution over representations is Gaussian, we can then prove that joint distribution of representations is also Gaussian. Taken together, these results show that representations learned via temporal contrastive learning follow a Gauss-Markov chain, a graphical model where inference (e.g., prediction, planning) over representations corresponds to inverting a low-dimensional matrix. In one special case, inferring intermediate representations will be equivalent to interpolating between the learned representations. We validate our theory using numerical simulations on tasks up to 46-dimensions.
Create account to get full access
Overview
- This paper proposes a new approach called "Inference via Interpolation" that uses contrastive representation learning to enable planning and inference.
- The key idea is that by learning representations that capture the important structure of the environment, the system can perform tasks like planning and inference by interpolating between known data points, rather than relying on explicit models.
- The authors provide theoretical guarantees that their approach can enable planning and inference, and demonstrate its effectiveness on various benchmark tasks.
Plain English Explanation
The paper presents a new way of learning representations, or "features," from data that can be used for tasks like planning and decision-making. The key insight is that by learning representations that capture the important structure and relationships in the environment, the system can perform these complex tasks by simply "interpolating" or filling in the gaps between the known data points, rather than needing to build an explicit model of how everything works.
For example, imagine you're trying to plan a trip. Traditionally, you might need to build a detailed model of the transportation network, weather patterns, traffic, and so on. But with this new approach, the system could learn a rich representation of the relevant factors and their interactions, allowing it to plan the trip by interpolating between known successful routes, without needing the explicit model.
This contrasts with many existing AI systems that require detailed, hand-crafted models. By learning the right kind of representations through contrastive learning, this new approach can perform sophisticated reasoning and planning in a more flexible, data-driven way.
The paper provides theoretical guarantees that this "Inference via Interpolation" approach can indeed enable effective planning and inference, and demonstrates its practical effectiveness on various benchmark tasks. The key insight is that the right kind of learned representations can capture the essential structure of the environment, allowing complex reasoning to be performed through simple interpolation.
Technical Explanation
The core of the paper's technical approach is a new contrastive representation learning framework that the authors call "Inference via Interpolation." The key idea is to learn representations of the environment that capture its essential structure and dynamics, so that planning and inference can be performed by "interpolating" between known data points, rather than requiring an explicit model.
Formally, the authors show that if the learned representations satisfy certain properties - namely, that they are Lipschitz continuous and have low dimensionality - then they can provably enable effective planning and inference. This is because these properties allow the system to "fill in the gaps" between known data points through interpolation, rather than needing to build a detailed model.
The authors demonstrate the effectiveness of this approach on a range of benchmark tasks, including continuous control, navigation, and symbolic reasoning. They show that their "Inference via Interpolation" system outperforms baselines that rely on explicit dynamics models, especially in settings with sparse rewards or high-dimensional state spaces.
Critical Analysis
The key contribution of this work is the theoretical and empirical demonstration that contrastive representation learning can provably enable effective planning and inference, without requiring complex dynamics models. This represents a notable advance over traditional AI planning and reasoning approaches, which often struggle with the complexity of the real world.
That said, the paper does not address some important caveats and limitations. For example, the theoretical guarantees rely on strong assumptions about the representations, which may be difficult to achieve in practice. The paper also does not explore how sensitive the approach is to imperfect or noisy representations, or how it might scale to extremely large and complex environments.
Additionally, while the paper shows strong empirical results, it is not clear how the approach would generalize to truly open-ended, real-world settings that involve rich sensory input, long-term reasoning, and complex physical and social dynamics. Further research would be needed to understand the practical limitations and potential deployment challenges of this approach.
Overall, this work represents an interesting and promising step towards more flexible, data-driven approaches to planning and reasoning. However, significant further research and development would be needed to fully realize the potential of "Inference via Interpolation" in complex, real-world domains.
Conclusion
This paper proposes a new approach called "Inference via Interpolation" that leverages contrastive representation learning to enable effective planning and inference without requiring explicit dynamics models. The key idea is that by learning the right kind of representations, the system can perform complex reasoning tasks by simply "filling in the gaps" between known data points, rather than needing to build a detailed model of the environment.
The authors provide theoretical guarantees for this approach and demonstrate its effectiveness on a range of benchmark tasks. While this work represents an important step forward, significant further research would be needed to fully understand its practical limitations and potential for real-world deployment. Overall, this paper offers a promising new direction for more flexible, data-driven approaches to planning and reasoning in AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Causal Contrastive Learning for Counterfactual Regression Over Time
Mouad El Bouchattaoui, Myriam Tami, Benoit Lepetit, Paul-Henry Courn`ede
0
0
Estimating treatment effects over time holds significance in various domains, including precision medicine, epidemiology, economy, and marketing. This paper introduces a unique approach to counterfactual regression over time, emphasizing long-term predictions. Distinguishing itself from existing models like Causal Transformer, our approach highlights the efficacy of employing RNNs for long-term forecasting, complemented by Contrastive Predictive Coding (CPC) and Information Maximization (InfoMax). Emphasizing efficiency, we avoid the need for computationally expensive transformers. Leveraging CPC, our method captures long-term dependencies in the presence of time-varying confounders. Notably, recent models have disregarded the importance of invertible representation, compromising identification assumptions. To remedy this, we employ the InfoMax principle, maximizing a lower bound of mutual information between sequence data and its representation. Our method achieves state-of-the-art counterfactual estimation results using both synthetic and real-world data, marking the pioneering incorporation of Contrastive Predictive Encoding in causal inference.
6/4/2024
Causal Representation Learning from Multiple Distributions: A General Setting
Kun Zhang, Shaoan Xie, Ignavier Ng, Yujia Zheng
0
0
In many problems, the measured variables (e.g., image pixels) are just mathematical functions of the hidden causal variables (e.g., the underlying concepts or objects). For the purpose of making predictions in changing environments or making proper changes to the system, it is helpful to recover the hidden causal variables $Z_i$ and their causal relations represented by graph $mathcal{G}_Z$. This problem has recently been known as causal representation learning. This paper is concerned with a general, completely nonparametric setting of causal representation learning from multiple distributions (arising from heterogeneous data or nonstationary time series), without assuming hard interventions behind distribution changes. We aim to develop general solutions in this fundamental case; as a by product, this helps see the unique benefit offered by other assumptions such as parametric causal models or hard interventions. We show that under the sparsity constraint on the recovered graph over the latent variables and suitable sufficient change conditions on the causal influences, interestingly, one can recover the moralized graph of the underlying directed acyclic graph, and the recovered latent variables and their relations are related to the underlying causal model in a specific, nontrivial way. In some cases, each latent variable can even be recovered up to component-wise transformations. Experimental results verify our theoretical claims.
4/11/2024
🤯
From latent dynamics to meaningful representations
Dedi Wang, Yihang Wang, Luke Evans, Pratyush Tiwary
0
0
While representation learning has been central to the rise of machine learning and artificial intelligence, a key problem remains in making the learned representations meaningful. For this, the typical approach is to regularize the learned representation through prior probability distributions. However, such priors are usually unavailable or are ad hoc. To deal with this, recent efforts have shifted towards leveraging the insights from physical principles to guide the learning process. In this spirit, we propose a purely dynamics-constrained representation learning framework. Instead of relying on predefined probabilities, we restrict the latent representation to follow overdamped Langevin dynamics with a learnable transition density - a prior driven by statistical mechanics. We show this is a more natural constraint for representation learning in stochastic dynamical systems, with the crucial ability to uniquely identify the ground truth representation. We validate our framework for different systems including a real-world fluorescent DNA movie dataset. We show that our algorithm can uniquely identify orthogonal, isometric and meaningful latent representations.
4/11/2024
Representations as Language: An Information-Theoretic Framework for Interpretability
Henry Conklin, Kenny Smith
0
0
Large scale neural models show impressive performance across a wide array of linguistic tasks. Despite this they remain, largely, black-boxes - inducing vector-representations of their input that prove difficult to interpret. This limits our ability to understand what they learn, and when the learn it, or describe what kinds of representations generalise well out of distribution. To address this we introduce a novel approach to interpretability that looks at the mapping a model learns from sentences to representations as a kind of language in its own right. In doing so we introduce a set of information-theoretic measures that quantify how structured a model's representations are with respect to its input, and when during training that structure arises. Our measures are fast to compute, grounded in linguistic theory, and can predict which models will generalise best based on their representations. We use these measures to describe two distinct phases of training a transformer: an initial phase of in-distribution learning which reduces task loss, then a second stage where representations becoming robust to noise. Generalisation performance begins to increase during this second phase, drawing a link between generalisation and robustness to noise. Finally we look at how model size affects the structure of the representational space, showing that larger models ultimately compress their representations more than their smaller counterparts.
6/5/2024