InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning

0

Sign in to get full access
Overview
- The paper describes InfiMM-WebMath-40B, a multimodal pre-training model for enhanced mathematical reasoning.
- The model aims to improve performance on a variety of mathematical tasks by leveraging both visual and textual information.
- The authors introduce a large-scale multimodal mathematics dataset and use it to pre-train their InfiMM-WebMath-40B model.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) model called InfiMM-WebMath-40B that is designed to be better at solving mathematical problems. Traditional AI models for math often only use text-based information, but the researchers believe that incorporating visual information as well can lead to better performance.
To train their model, the researchers created a large dataset of mathematical content that includes not just text, but also related images, diagrams, and other visual elements. They then used this dataset to pre-train the InfiMM-WebMath-40B model, which means they exposed the model to a huge amount of this multimodal math data before having it tackle specific math tasks.
The key idea is that by pre-training on this diverse math dataset, the model will be able to learn patterns and connections between the visual and textual aspects of mathematics. This, in turn, should allow the model to reason about math problems in a more comprehensive and effective way compared to models that only consider the text.
The researchers believe that this multimodal approach to pre-training will lead to significant improvements in the model's ability to solve a wide range of mathematical problems, from basic arithmetic to more advanced concepts. By tapping into both the visual and textual components of mathematics, the InfiMM-WebMath-40B model aims to push the boundaries of what's possible in automated mathematical reasoning.
Technical Explanation
The paper introduces InfiMM-WebMath-40B, a large-scale multimodal pre-training model for enhanced mathematical reasoning. The key innovation is the use of a diverse multimodal dataset, called WebMath, which contains not just textual mathematical content, but also related images, diagrams, and other visual elements.
The authors use this dataset to pre-train their InfiMM-WebMath-40B model, exposing it to a vast amount of multimodal math data before fine-tuning it on specific mathematical tasks. This pre-training approach allows the model to learn rich representations that capture the complex relationship between the visual and textual components of mathematics.
The architecture of InfiMM-WebMath-40B consists of a multimodal encoder that jointly processes the textual and visual inputs, as well as task-specific heads for various mathematical reasoning tasks. The authors employ advanced techniques such as cross-modal attention and multimodal fusion to effectively combine the visual and textual information.
Through extensive experiments on a range of mathematical benchmarks, the researchers demonstrate the superior performance of InfiMM-WebMath-40B compared to text-only baselines. The model excels at tasks such as equation solving, mathematical question answering, and mathematical proof generation, showcasing the benefits of the multimodal pre-training approach.
Critical Analysis
The paper presents a compelling approach to enhancing mathematical reasoning through multimodal pre-training. However, the authors acknowledge the limitation of the WebMath dataset, which may not capture the full breadth and diversity of mathematical content available on the web. Expanding the dataset or exploring alternative data sources could further improve the model's performance.
Additionally, the authors do not provide a thorough analysis of the model's interpretability or its ability to explain its reasoning process. As AI systems become more powerful, understanding their inner workings and decision-making processes is crucial for building trust and ensuring their safe deployment.
Furthermore, the paper does not explore the potential biases or fairness implications of the InfiMM-WebMath-40B model. As with any large-scale AI system, there is a risk of perpetuating or amplifying societal biases, which should be carefully examined and addressed.
Conclusion
The InfiMM-WebMath-40B model presented in this paper represents a significant advancement in multimodal pre-training for mathematical reasoning. By leveraging both visual and textual information, the model demonstrates superior performance on a variety of mathematical tasks compared to text-only approaches.
The researchers' work highlights the importance of multimodal learning in domains like mathematics, where visual cues and representations can provide valuable insights and enhance the overall reasoning capabilities of AI systems. As the field of AI continues to evolve, the InfiMM-WebMath-40B model serves as a promising step towards more robust and versatile mathematical reasoning abilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
InfiMM-WebMath-40B: Advancing Multimodal Pre-Training for Enhanced Mathematical Reasoning
Xiaotian Han, Yiren Jian, Xuefeng Hu, Haogeng Liu, Yiqi Wang, Qihang Fan, Yuang Ai, Huaibo Huang, Ran He, Zhenheng Yang, Quanzeng You
Pre-training on large-scale, high-quality datasets is crucial for enhancing the reasoning capabilities of Large Language Models (LLMs), especially in specialized domains such as mathematics. Despite the recognized importance, the Multimodal LLMs (MLLMs) field currently lacks a comprehensive open-source pre-training dataset specifically designed for mathematical reasoning. To address this gap, we introduce InfiMM-WebMath-40B, a high-quality dataset of interleaved image-text documents. It comprises 24 million web pages, 85 million associated image URLs, and 40 billion text tokens, all meticulously extracted and filtered from CommonCrawl. We provide a detailed overview of our data collection and processing pipeline. To demonstrate the robustness of InfiMM-WebMath-40B, we conducted evaluations in both text-only and multimodal settings. Our evaluations on text-only benchmarks show that, despite utilizing only 40 billion tokens, our dataset significantly enhances the performance of our 1.3B model, delivering results comparable to DeepSeekMath-1.3B, which uses 120 billion tokens for the same model size. Nevertheless, with the introduction of our multi-modal math pre-training dataset, our models set a new state-of-the-art among open-source models on multi-modal math benchmarks such as MathVerse and We-Math. We release our data at https://huggingface.co/datasets/Infi-MM/InfiMM-WebMath-40B.
Read more9/20/2024

0
CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
Wentao Liu, Qianjun Pan, Yi Zhang, Zhuo Liu, Ji Wu, Jie Zhou, Aimin Zhou, Qin Chen, Bo Jiang, Liang He
Large language models (LLMs) have obtained promising results in mathematical reasoning, which is a foundational skill for human intelligence. Most previous studies focus on improving and measuring the performance of LLMs based on textual math reasoning datasets (e.g., MATH, GSM8K). Recently, a few researchers have released English multimodal math datasets (e.g., MATHVISTA and MATH-V) to evaluate the effectiveness of large multimodal models (LMMs). In this paper, we release a Chinese multimodal math (CMM-Math) dataset, including benchmark and training parts, to evaluate and enhance the mathematical reasoning of LMMs. CMM-Math contains over 28,000 high-quality samples, featuring a variety of problem types (e.g., multiple-choice, fill-in-the-blank, and so on) with detailed solutions across 12 grade levels from elementary to high school in China. Specifically, the visual context may be present in the questions or opinions, which makes this dataset more challenging. Through comprehensive analysis, we discover that state-of-the-art LMMs on the CMM-Math dataset face challenges, emphasizing the necessity for further improvements in LMM development. We also propose a Multimodal Mathematical LMM (Math-LMM) to handle the problems with mixed input of multiple images and text segments. We train our model using three stages, including foundational pre-training, foundational fine-tuning, and mathematical fine-tuning. The extensive experiments indicate that our model effectively improves math reasoning performance by comparing it with the SOTA LMMs over three multimodal mathematical datasets.
Read more9/9/2024

0
Math-LLaVA: Bootstrapping Mathematical Reasoning for Multimodal Large Language Models
Wenhao Shi, Zhiqiang Hu, Yi Bin, Junhua Liu, Yang Yang, See-Kiong Ng, Lidong Bing, Roy Ka-Wei Lee
Large language models (LLMs) have demonstrated impressive reasoning capabilities, particularly in textual mathematical problem-solving. However, existing open-source image instruction fine-tuning datasets, containing limited question-answer pairs per image, do not fully exploit visual information to enhance the multimodal mathematical reasoning capabilities of Multimodal LLMs (MLLMs). To bridge this gap, we address the lack of high-quality, diverse multimodal mathematical datasets by collecting 40K high-quality images with question-answer pairs from 24 existing datasets and synthesizing 320K new pairs, creating the MathV360K dataset, which enhances both the breadth and depth of multimodal mathematical questions. We introduce Math-LLaVA, a LLaVA-1.5-based model fine-tuned with MathV360K. This novel approach significantly improves the multimodal mathematical reasoning capabilities of LLaVA-1.5, achieving a 19-point increase and comparable performance to GPT-4V on MathVista's minitest split. Furthermore, Math-LLaVA demonstrates enhanced generalizability, showing substantial improvements on the MMMU benchmark. Our research highlights the importance of dataset diversity and synthesis in advancing MLLMs' mathematical reasoning abilities. The code and data are available at: url{https://github.com/HZQ950419/Math-LLaVA}.
Read more6/27/2024
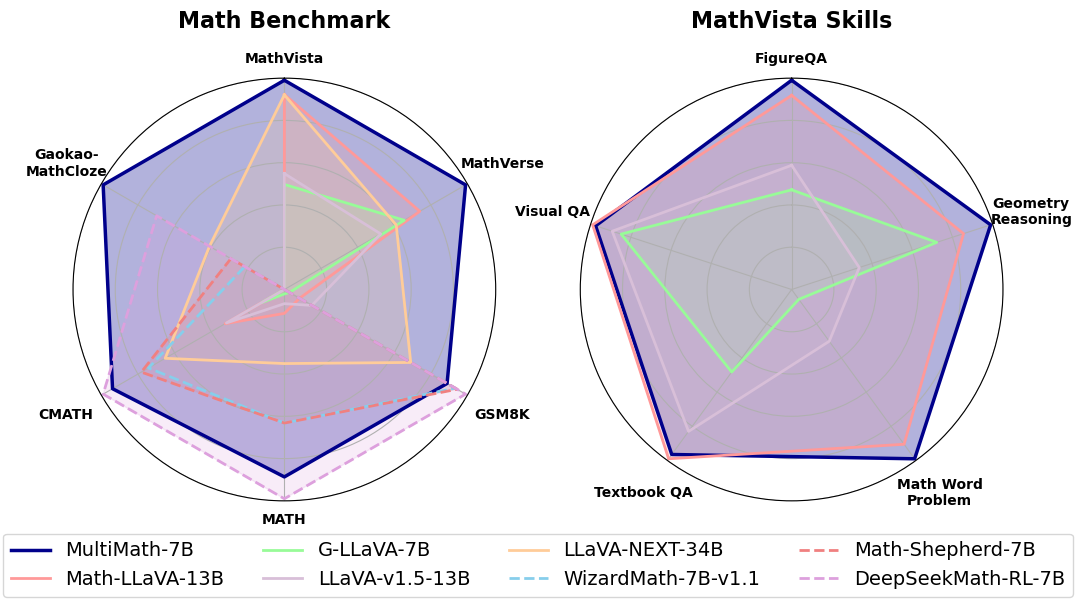
0
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024