Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache

0

Sign in to get full access
Overview
- Efficient LLM service for long context with DistAttention and Distributed KVCache
- Addresses challenges of scaling LLMs to long contexts
- Proposes novel techniques for efficient inference
Plain English Explanation
The paper presents a system called Infinite-LLM that aims to make large language models (LLMs) more efficient at processing long contexts. LLMs are powerful AI models that can generate human-like text, but they can struggle when given very long input sequences.
The key innovations in Infinite-LLM are:
- DistAttention: A novel attention mechanism that can efficiently process long contexts by distributing the attention computation across multiple GPUs.
- Distributed KVCache: A caching system that stores previously computed key-value pairs and reuses them, reducing the amount of computation needed for subsequent inferences.
These techniques allow Infinite-LLM to handle much longer input sequences than standard LLM models, while maintaining high performance and efficiency.
Technical Explanation
The paper first provides background on the challenges of scaling LLMs to long contexts. LLMs typically have quadratic time and memory complexity with respect to the input length, making them computationally expensive for long sequences.
To address this, the authors propose the Infinite-LLM architecture, which includes two key innovations:
-
DistAttention: This attention mechanism distributes the attention computation across multiple GPUs, allowing for efficient processing of long contexts. It works by partitioning the input sequence and attention computations across the GPUs, and then aggregating the results.
-
Distributed KVCache: This caching system stores previously computed key-value pairs from the attention mechanism, and reuses them for subsequent inferences. This reduces the amount of computation needed, further improving efficiency.
The authors evaluate Infinite-LLM on a variety of long-context tasks, including language modeling and question answering. They show that Infinite-LLM can handle input sequences up to 8192 tokens long, while maintaining high performance and efficiency compared to standard LLM models.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the Infinite-LLM system, exploring its performance on a range of long-context tasks. The authors acknowledge some limitations, such as the need for careful hyperparameter tuning and the potential for increased memory usage due to the caching mechanism.
One potential area for further research could be exploring the generalization of the DistAttention and Distributed KVCache techniques to other types of large-scale AI models, not just LLMs. Additionally, the paper does not address the training process for Infinite-LLM, which could be an interesting area for future work.
Overall, the Infinite-LLM system represents a significant advancement in the field of efficient LLM inference for long contexts, and the techniques presented could have widespread applications in the development of large-scale AI systems.
Conclusion
The Infinite-LLM system proposed in this paper addresses a critical challenge in the field of large language models: efficiently processing long input sequences. By introducing the novel DistAttention and Distributed KVCache techniques, the authors have developed a system that can handle input sequences up to 8192 tokens long, while maintaining high performance and efficiency.
These innovations have the potential to unlock new applications and use cases for LLMs, particularly in domains that require processing of long, complex text. The critical analysis suggests that the techniques could also be applicable to other types of large-scale AI models, further expanding the impact of this research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, Wei Lin
Large Language Models (LLMs) demonstrate substantial potential across a diverse array of domains via request serving. However, as trends continue to push for expanding context sizes, the autoregressive nature of LLMs results in highly dynamic behavior of the attention layers, showcasing significant differences in computational characteristics and memory requirements from the non-attention layers. This presents substantial challenges for resource management and performance optimization in service systems. Existing static model parallelism and resource allocation strategies fall short when dealing with this dynamicity. To address the issue, we propose Infinite-LLM, a novel LLM serving system designed to effectively handle dynamic context lengths. Infinite-LLM disaggregates attention layers from an LLM's inference process, facilitating flexible and independent resource scheduling that optimizes computational performance and enhances memory utilization jointly. By leveraging a pooled GPU memory strategy across a cluster, Infinite-LLM not only significantly boosts system throughput but also supports extensive context lengths. Evaluated on a dataset with context lengths ranging from a few to 2000K tokens across a cluster with 32 A100 GPUs, Infinite-LLM demonstrates throughput improvement of 1.35-3.4x compared to state-of-the-art methods, enabling efficient and elastic LLM deployment.
Read more7/8/2024
🔍
0
InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, Maosong Sun
Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs (e.g., LLM-driven agents). However, existing LLMs, pre-trained on sequences with a restricted maximum length, cannot process longer sequences due to the out-of-domain and distraction issues. Common solutions often involve continual pre-training on longer sequences, which will introduce expensive computational overhead and uncontrollable change in model capabilities. In this paper, we unveil the intrinsic capacity of LLMs for understanding extremely long sequences without any fine-tuning. To this end, we introduce a training-free memory-based method, InfLLM. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences with a limited context window and well capture long-distance dependencies. Without any training, InfLLM enables LLMs that are pre-trained on sequences consisting of a few thousand tokens to achieve comparable performance with competitive baselines that continually train these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies. Our code can be found in url{https://github.com/thunlp/InfLLM}.
Read more5/29/2024
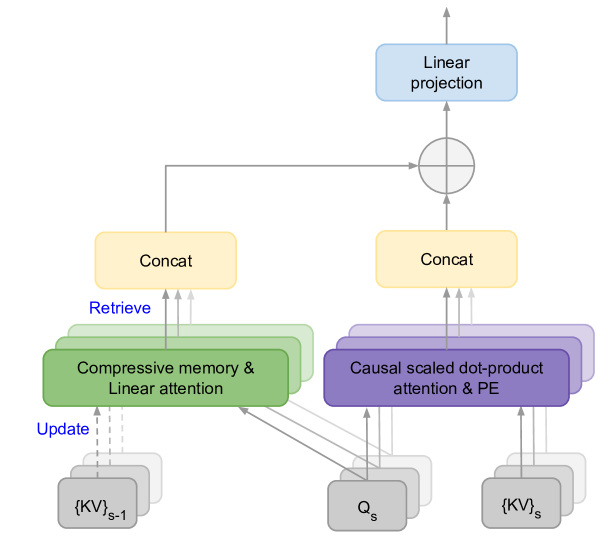
27
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
Read more8/13/2024

0
Farewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
Xiaoran Liu, Qipeng Guo, Yuerong Song, Zhigeng Liu, Kai Lv, Hang Yan, Linlin Li, Qun Liu, Xipeng Qiu
The maximum supported context length is a critical bottleneck limiting the practical application of the Large Language Model (LLM). Although existing length extrapolation methods can extend the context of LLMs to millions of tokens, these methods all have an explicit upper bound. In this work, we propose LongCache, a training-free approach that enables LLM to support an infinite context with finite context scope, through full-context cache selection and training-free integration. This effectively frees LLMs from the length extrapolation issue. We validate LongCache on the LongBench and L-Eval and demonstrate its performance is on par with traditional full-attention mechanisms. Furthermore, we have applied LongCache on mainstream LLMs, including LLaMA3 and Mistral-v0.3, enabling them to support context lengths of at least 400K in Needle-In-A-Haystack tests. We will improve the efficiency of LongCache by GPU-aware optimization soon.
Read more7/23/2024