InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification
2401.16475
3
0

Abstract
Text simplification aims to make technical texts more accessible to laypeople but often results in deletion of information and vagueness. This work proposes InfoLossQA, a framework to characterize and recover simplification-induced information loss in form of question-and-answer (QA) pairs. Building on the theory of Question Under Discussion, the QA pairs are designed to help readers deepen their knowledge of a text. We conduct a range of experiments with this framework. First, we collect a dataset of 1,000 linguist-curated QA pairs derived from 104 LLM simplifications of scientific abstracts of medical studies. Our analyses of this data reveal that information loss occurs frequently, and that the QA pairs give a high-level overview of what information was lost. Second, we devise two methods for this task: end-to-end prompting of open-source and commercial language models, and a natural language inference pipeline. With a novel evaluation framework considering the correctness of QA pairs and their linguistic suitability, our expert evaluation reveals that models struggle to reliably identify information loss and applying similar standards as humans at what constitutes information loss.
Create account to get full access
Overview
- This paper introduces the InfoLossQA task, which aims to characterize and recover information loss in text simplification.
- Text simplification is the process of making complex text easier to understand, but it can result in the loss of important information.
- The InfoLossQA task involves evaluating how much information is lost during text simplification and developing methods to recover that lost information.
Plain English Explanation
The paper discusses a new task called InfoLossQA that looks at the problem of information loss when simplifying text. When we try to make complex text easier to understand, sometimes important details or facts can get lost in the process. The goal of InfoLossQA is to measure how much information is lost during text simplification and then find ways to recover that lost information.
For example, if you took a complex scientific article and rewrote it in simpler language, you might end up leaving out some key details or nuances that were in the original. The InfoLossQA task would try to identify those missing details and figure out how to preserve them even in the simplified version. This could be useful for things like scientific summarization or health question answering, where it's important to maintain the accuracy and completeness of information.
Technical Explanation
The InfoLossQA task involves two main components: characterizing information loss and recovering lost information. For characterizing information loss, the authors propose evaluating simplification models on their ability to preserve answers to a set of questions about the original text. This allows them to quantify the amount of information lost during simplification.
To recover lost information, the authors explore different architectures that combine the simplified text with additional signals, such as the original complex text or a set of related documents. These models are trained to predict the answers to the same set of questions, with the goal of recovering the information lost in the simplification process.
The authors evaluate their approaches on a new dataset of complex-simple text pairs, along with associated questions and answers. Their results show that the combined models can effectively recover a significant portion of the information lost during simplification, outperforming simpler baselines.
Critical Analysis
The InfoLossQA task and the proposed approaches represent an important step in understanding and addressing the information loss problem in text simplification. By providing a standardized way to measure information loss, the authors enable more rigorous evaluation of simplification models and the development of techniques to mitigate this issue.
However, the paper also acknowledges some limitations of the current work. The dataset used is relatively small, and the questions and answers may not cover all the nuanced information that could be lost during simplification. Additionally, the recovery models rely on having access to the original complex text, which may not always be available in real-world applications.
Future research could explore ways to prune text efficiently during simplification to better preserve important information, or to generalize the recovery models to work with limited context. Broader adoption of the InfoLossQA framework could also lead to insights into the types of information that are most vulnerable to loss during simplification and how to better protect them.
Conclusion
The InfoLossQA task introduced in this paper represents an important advancement in the field of text simplification. By providing a systematic way to measure and recover information loss, the authors have laid the groundwork for developing more robust and reliable simplification systems. This has significant implications for applications like scientific summarization, health question answering, and other domains where preserving the accuracy and completeness of information is crucial. As this area of research continues to evolve, we can expect to see further advancements in our ability to simplify text while maintaining its informative content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Accurate and Nuanced Open-QA Evaluation Through Textual Entailment
Peiran Yao, Denilson Barbosa
0
0
Open-domain question answering (Open-QA) is a common task for evaluating large language models (LLMs). However, current Open-QA evaluations are criticized for the ambiguity in questions and the lack of semantic understanding in evaluators. Complex evaluators, powered by foundation models or LLMs and pertaining to semantic equivalence, still deviate from human judgments by a large margin. We propose to study the entailment relations of answers to identify more informative and more general system answers, offering a much closer evaluation to human judgment on both NaturalQuestions and TriviaQA while being learning-free. The entailment-based evaluation we propose allows the assignment of bonus or partial marks by quantifying the inference gap between answers, enabling a nuanced ranking of answer correctness that has higher AUC than current methods.
5/28/2024
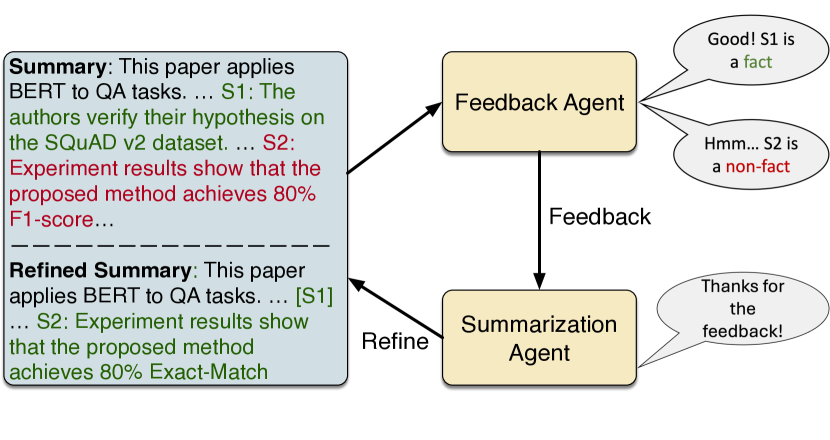
ISQA: Informative Factuality Feedback for Scientific Summarization
Zekai Li, Yanxia Qin, Qian Liu, Min-Yen Kan
0
0
We propose Iterative Facuality Refining on Informative Scientific Question-Answering (ISQA) feedbackfootnote{Code is available at url{https://github.com/lizekai-richard/isqa}}, a method following human learning theories that employs model-generated feedback consisting of both positive and negative information. Through iterative refining of summaries, it probes for the underlying rationale of statements to enhance the factuality of scientific summarization. ISQA does this in a fine-grained manner by asking a summarization agent to reinforce validated statements in positive feedback and fix incorrect ones in negative feedback. Our findings demonstrate that the ISQA feedback mechanism significantly improves the factuality of various open-source LLMs on the summarization task, as evaluated across multiple scientific datasets.
4/23/2024
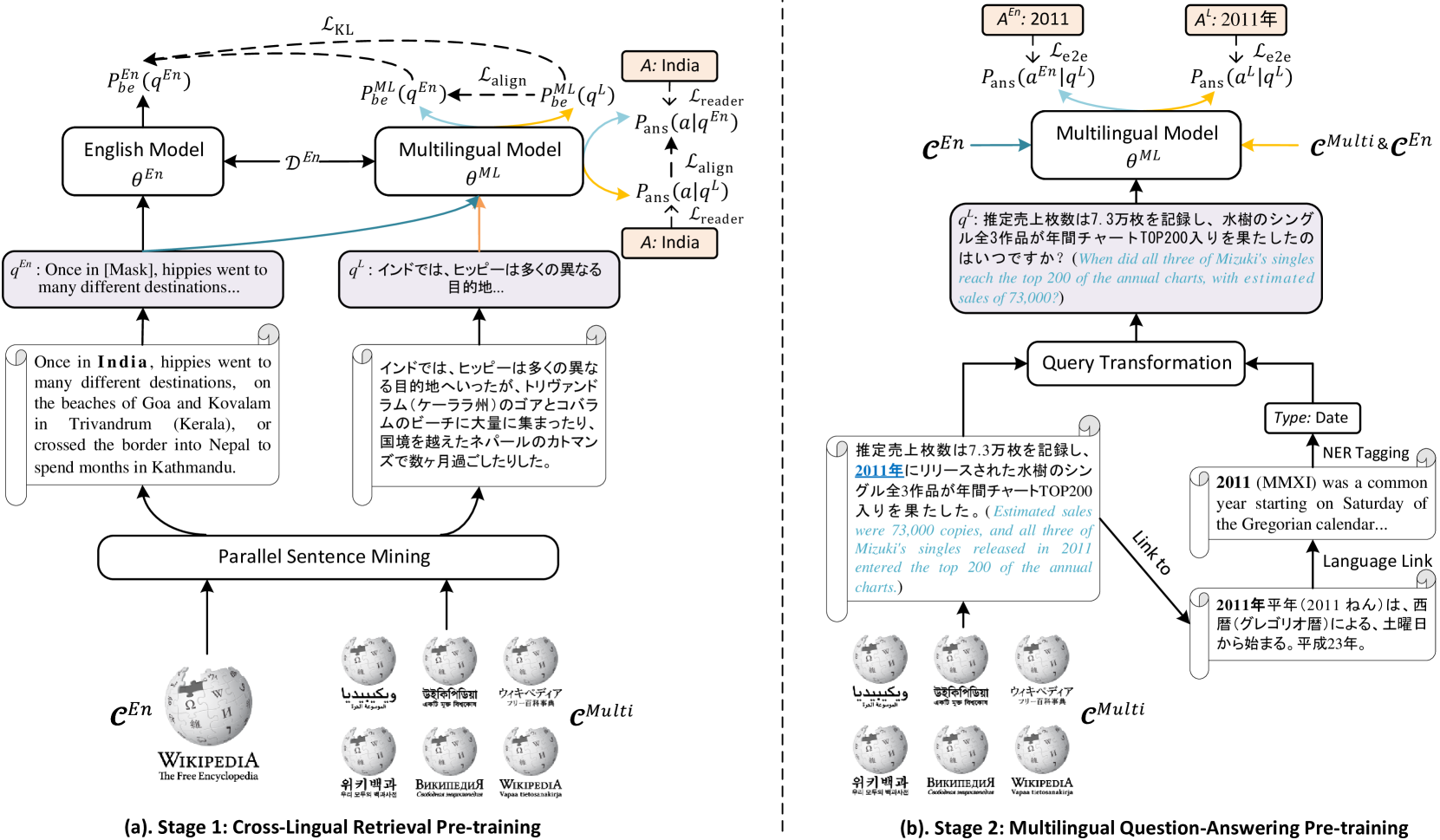
Pre-training Cross-lingual Open Domain Question Answering with Large-scale Synthetic Supervision
Fan Jiang, Tom Drummond, Trevor Cohn
0
0
Cross-lingual open domain question answering (CLQA) is a complex problem, comprising cross-lingual retrieval from a multilingual knowledge base, followed by answer generation in the query language. Both steps are usually tackled by separate models, requiring substantial annotated datasets, and typically auxiliary resources, like machine translation systems to bridge between languages. In this paper, we show that CLQA can be addressed using a single encoder-decoder model. To effectively train this model, we propose a self-supervised method based on exploiting the cross-lingual link structure within Wikipedia. We demonstrate how linked Wikipedia pages can be used to synthesise supervisory signals for cross-lingual retrieval, through a form of cloze query, and generate more natural questions to supervise answer generation. Together, we show our approach, texttt{CLASS}, outperforms comparable methods on both supervised and zero-shot language adaptation settings, including those using machine translation.
6/18/2024

FinTruthQA: A Benchmark Dataset for Evaluating the Quality of Financial Information Disclosure
Ziyue Xu, Peilin Zhou, Xinyu Shi, Jiageng Wu, Yikang Jiang, Bin Ke, Jie Yang
0
0
Accurate and transparent financial information disclosure is crucial in the fields of accounting and finance, ensuring market efficiency and investor confidence. Among many information disclosure platforms, the Chinese stock exchanges' investor interactive platform provides a novel and interactive way for listed firms to disclose information of interest to investors through an online question-and-answer (Q&A) format. However, it is common for listed firms to respond to questions with limited or no substantive information, and automatically evaluating the quality of financial information disclosure on large amounts of Q&A pairs is challenging. This paper builds a benchmark FinTruthQA, that can evaluate advanced natural language processing (NLP) techniques for the automatic quality assessment of information disclosure in financial Q&A data. FinTruthQA comprises 6,000 real-world financial Q&A entries and each Q&A was manually annotated based on four conceptual dimensions of accounting. We benchmarked various NLP techniques on FinTruthQA, including statistical machine learning models, pre-trained language model and their fine-tuned versions, as well as the large language model GPT-4. Experiments showed that existing NLP models have strong predictive ability for real question identification and question relevance tasks, but are suboptimal for answer relevance and answer readability tasks. By establishing this benchmark, we provide a robust foundation for the automatic evaluation of information disclosure, significantly enhancing the transparency and quality of financial reporting. FinTruthQA can be used by auditors, regulators, and financial analysts for real-time monitoring and data-driven decision-making, as well as by researchers for advanced studies in accounting and finance, ultimately fostering greater trust and efficiency in the financial markets.
6/19/2024