ISQA: Informative Factuality Feedback for Scientific Summarization
2404.13246
0
0
Abstract
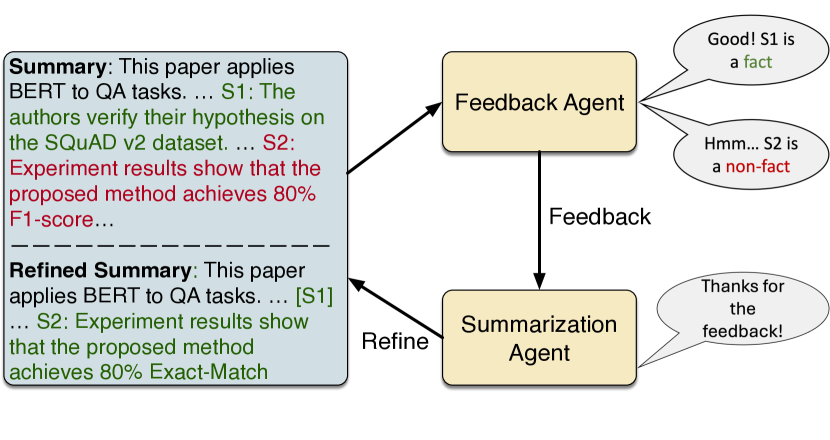
We propose Iterative Facuality Refining on Informative Scientific Question-Answering (ISQA) feedbackfootnote{Code is available at url{https://github.com/lizekai-richard/isqa}}, a method following human learning theories that employs model-generated feedback consisting of both positive and negative information. Through iterative refining of summaries, it probes for the underlying rationale of statements to enhance the factuality of scientific summarization. ISQA does this in a fine-grained manner by asking a summarization agent to reinforce validated statements in positive feedback and fix incorrect ones in negative feedback. Our findings demonstrate that the ISQA feedback mechanism significantly improves the factuality of various open-source LLMs on the summarization task, as evaluated across multiple scientific datasets.
Create account to get full access
Overview
- This paper proposes a new method called ISQA (Informative Factuality Feedback for Scientific Summarization) to provide feedback on the factuality of automatically generated scientific summaries.
- ISQA aims to identify factual inconsistencies and inaccuracies in summaries, and provide informative feedback to help improve the summarization process.
- The paper evaluates ISQA on several publicly available datasets and compares its performance to existing factuality evaluation approaches.
Plain English Explanation
The paper introduces a new system called ISQA that can automatically check the accuracy and factual correctness of computer-generated summaries of scientific papers. Often, these machine-generated summaries can contain inaccuracies or make claims that are not fully supported by the original research. ISQA is designed to identify these kinds of factual problems in the summaries and provide detailed feedback to help improve the summarization process.
The key idea behind ISQA is to compare the claims made in the summary against the information contained in the original research paper. By analyzing the language used and the relationships between concepts, ISQA can pinpoint areas where the summary may be diverging from the facts presented in the source material. This feedback can then be used by researchers and summarization systems to refine the summarization approach and produce more truthful and informative summaries.
The paper evaluates ISQA on several publicly available datasets of scientific papers and their summaries. The results show that ISQA is effective at detecting factual inconsistencies and providing useful feedback, outperforming some existing factuality evaluation methods. This suggests ISQA could be a valuable tool for improving the trustworthiness and reliability of automatically generated scientific summaries.
Technical Explanation
The paper introduces the ISQA (Informative Factuality Feedback for Scientific Summarization) system, which aims to provide detailed feedback on the factual consistency and accuracy of automatically generated scientific summaries. ISQA operates by comparing the claims and information present in a summary against the source research paper to identify any factual inconsistencies or inaccuracies.
The key technical components of ISQA include:
- Factuality Scoring Module: This module analyzes the language used in the summary and paper to assess the factuality of each claim made in the summary.
- Inconsistency Detection Module: This module identifies specific inconsistencies between the information in the summary and the original paper, flagging areas that require correction.
- Feedback Generation Module: This module generates detailed feedback for the summarization system, highlighting the factual issues identified and providing guidance on how to improve the summary.
The paper evaluates ISQA on several publicly available datasets, including SummEval and AMRFact. The results show that ISQA outperforms existing factuality evaluation approaches in terms of identifying inconsistencies and providing informative feedback.
Critical Analysis
The paper presents a robust and well-designed approach to evaluating the factual accuracy of scientific summaries. The use of multiple technical components to analyze the summary content, identify inconsistencies, and provide targeted feedback is a strength of the ISQA system. The evaluation on diverse datasets also demonstrates the broad applicability of the approach.
However, the paper does acknowledge some limitations of ISQA. For example, the system may struggle to detect more nuanced or implicit factual issues, and its performance is still dependent on the quality of the underlying natural language processing models. Additionally, the paper does not explore the potential biases or blindspots that could arise in ISQA's factuality assessments, which is an important area for further research.
Overall, ISQA represents a valuable contribution to the field of scientific summarization, providing a principled way to ensure the factual integrity of automatically generated summaries. The detailed feedback capabilities could be particularly useful for researchers and summarization system developers looking to improve the reliability and trustworthiness of their outputs.
Conclusion
The ISQA system introduced in this paper offers a novel approach to evaluating the factual accuracy of scientific summaries. By comparing the claims made in a summary against the original research paper, ISQA can identify inconsistencies and inaccuracies, and provide detailed feedback to help improve the summarization process.
The evaluation results demonstrate the effectiveness of ISQA in outperforming existing factuality evaluation methods. This suggests ISQA could be a valuable tool for enhancing the trustworthiness and reliability of automatically generated scientific summaries, which is crucial for ensuring the integrity of research dissemination.
While ISQA has some limitations, the core ideas and technical approach presented in this paper represent an important step forward in the quest for more accurate and informative scientific summarization. As the field continues to evolve, further research building on ISQA's foundations could lead to even more robust and comprehensive solutions for factuality assessment and feedback.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering
Sungho Ko, Hyunjin Cho, Hyungjoo Chae, Jinyoung Yeo, Dongha Lee
0
0
Recent studies have investigated utilizing Knowledge Graphs (KGs) to enhance Quesetion Answering (QA) performance of Large Language Models (LLMs), yet structured KG verbalization remains challengin. Existing methods, such as triple-form or free-form textual conversion of triple-form facts, encounter several issues. These include reduced evidence density due to duplicated entities or relationships, and reduced evidence clarity due to an inability to emphasize crucial evidence. To address these issues, we propose EFSum, an Evidence-focused Fact Summarization framework for enhanced QA with knowledge-augmented LLMs. We optimize an open-source LLM as a fact summarizer through distillation and preference alignment. Our extensive experiments show that EFSum improves LLM's zero-shot QA performance, and it is possible to ensure both the helpfulness and faithfulness of the summary.
6/21/2024
🗣️
New!SEMQA: Semi-Extractive Multi-Source Question Answering
Tal Schuster, Adam D. Lelkes, Haitian Sun, Jai Gupta, Jonathan Berant, William W. Cohen, Donald Metzler
0
0
Recently proposed long-form question answering (QA) systems, supported by large language models (LLMs), have shown promising capabilities. Yet, attributing and verifying their generated abstractive answers can be difficult, and automatically evaluating their accuracy remains an ongoing challenge. In this work, we introduce a new QA task for answering multi-answer questions by summarizing multiple diverse sources in a semi-extractive fashion. Specifically, Semi-extractive Multi-source QA (SEMQA) requires models to output a comprehensive answer, while mixing factual quoted spans -- copied verbatim from given input sources -- and non-factual free-text connectors that glue these spans together into a single cohesive passage. This setting bridges the gap between the outputs of well-grounded but constrained extractive QA systems and more fluent but harder to attribute fully abstractive answers. Particularly, it enables a new mode for language models that leverages their advanced language generation capabilities, while also producing fine in-line attributions by-design that are easy to verify, interpret, and evaluate. To study this task, we create the first dataset of this kind, QuoteSum, with human-written semi-extractive answers to natural and generated questions, and define text-based evaluation metrics. Experimenting with several LLMs in various settings, we find this task to be surprisingly challenging, demonstrating the importance of QuoteSum for developing and studying such consolidation capabilities.
7/2/2024

SYNFAC-EDIT: Synthetic Imitation Edit Feedback for Factual Alignment in Clinical Summarization
Prakamya Mishra, Zonghai Yao, Parth Vashisht, Feiyun Ouyang, Beining Wang, Vidhi Dhaval Mody, Hong Yu
0
0
Large Language Models (LLMs) such as GPT & Llama have demonstrated significant achievements in summarization tasks but struggle with factual inaccuracies, a critical issue in clinical NLP applications where errors could lead to serious consequences. To counter the high costs and limited availability of expert-annotated data for factual alignment, this study introduces an innovative pipeline that utilizes >100B parameter GPT variants like GPT-3.5 & GPT-4 to act as synthetic experts to generate high-quality synthetics feedback aimed at enhancing factual consistency in clinical note summarization. Our research primarily focuses on edit feedback generated by these synthetic feedback experts without additional human annotations, mirroring and optimizing the practical scenario in which medical professionals refine AI system outputs. Although such 100B+ parameter GPT variants have proven to demonstrate expertise in various clinical NLP tasks, such as the Medical Licensing Examination, there is scant research on their capacity to act as synthetic feedback experts and deliver expert-level edit feedback for improving the generation quality of weaker (<10B parameter) LLMs like GPT-2 (1.5B) & Llama 2 (7B) in clinical domain. So in this work, we leverage 100B+ GPT variants to act as synthetic feedback experts offering expert-level edit feedback, that is used to reduce hallucinations and align weaker (<10B parameter) LLMs with medical facts using two distinct alignment algorithms (DPO & SALT), endeavoring to narrow the divide between AI-generated content and factual accuracy. This highlights the substantial potential of LLM-based synthetic edits in enhancing the alignment of clinical factuality.
4/19/2024
Factual Dialogue Summarization via Learning from Large Language Models
Rongxin Zhu, Jey Han Lau, Jianzhong Qi
0
0
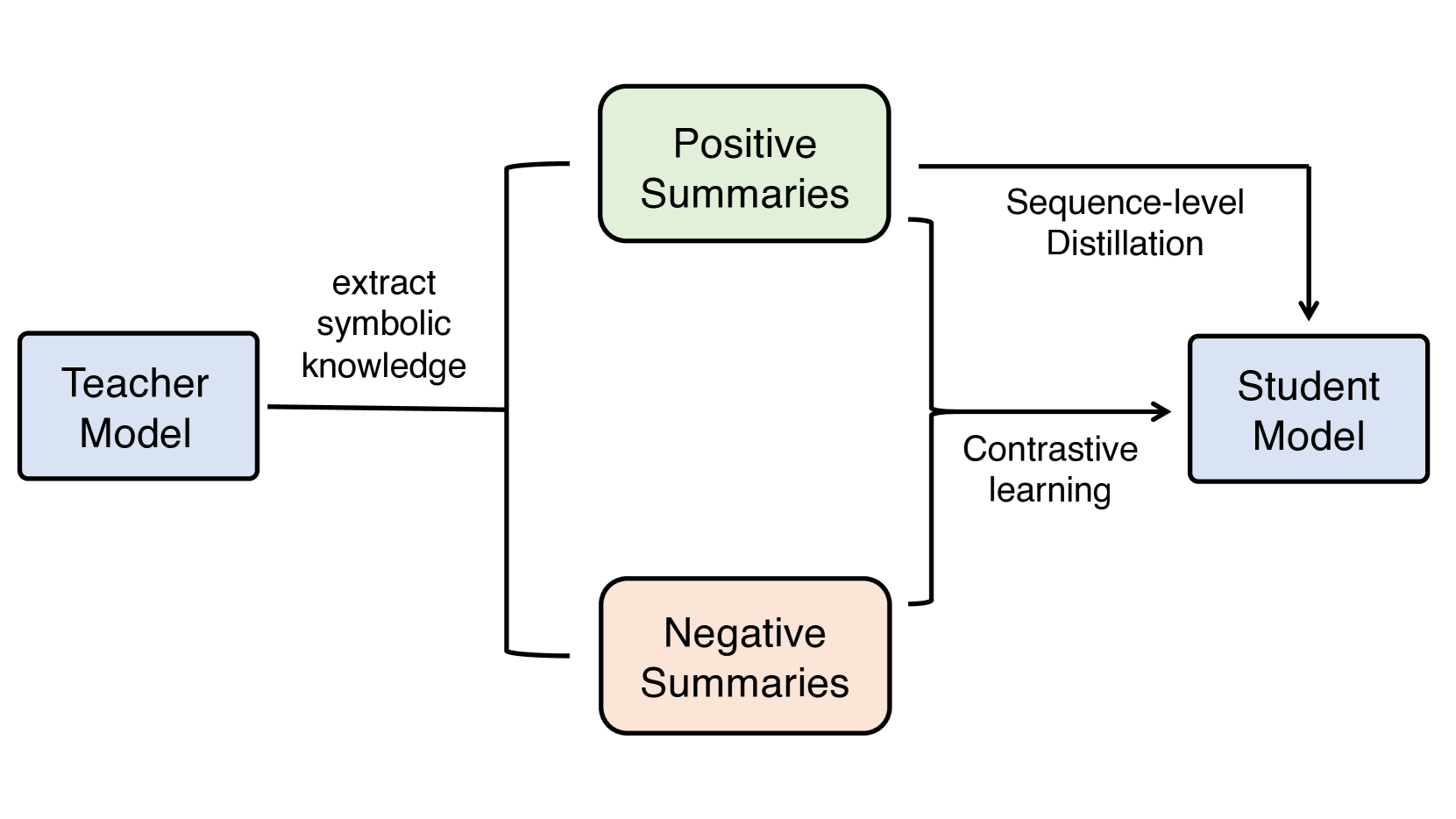
Factual consistency is an important quality in dialogue summarization. Large language model (LLM)-based automatic text summarization models generate more factually consistent summaries compared to those by smaller pretrained language models, but they face deployment challenges in real-world applications due to privacy or resource constraints. In this paper, we investigate the use of symbolic knowledge distillation to improve the factual consistency of smaller pretrained models for dialogue summarization. We employ zero-shot learning to extract symbolic knowledge from LLMs, generating both factually consistent (positive) and inconsistent (negative) summaries. We then apply two contrastive learning objectives on these summaries to enhance smaller summarization models. Experiments with BART, PEGASUS, and Flan-T5 indicate that our approach surpasses strong baselines that rely on complex data augmentation strategies. Our approach achieves better factual consistency while maintaining coherence, fluency, and relevance, as confirmed by various automatic evaluation metrics. We also provide access to the data and code to facilitate future research.
6/24/2024