Information Plane Analysis Visualization in Deep Learning via Transfer Entropy
2404.01364
0
0

Abstract
In a feedforward network, Transfer Entropy (TE) can be used to measure the influence that one layer has on another by quantifying the information transfer between them during training. According to the Information Bottleneck principle, a neural model's internal representation should compress the input data as much as possible while still retaining sufficient information about the output. Information Plane analysis is a visualization technique used to understand the trade-off between compression and information preservation in the context of the Information Bottleneck method by plotting the amount of information in the input data against the compressed representation. The claim that there is a causal link between information-theoretic compression and generalization, measured by mutual information, is plausible, but results from different studies are conflicting. In contrast to mutual information, TE can capture temporal relationships between variables. To explore such links, in our novel approach we use TE to quantify information transfer between neural layers and perform Information Plane analysis. We obtained encouraging experimental results, opening the possibility for further investigations.
Create account to get full access
Overview
- This paper introduces a method for visualizing the "information plane" of deep learning models, which provides insights into how information flows through the model during training.
- The key technique used is transfer entropy, a measure of information flow between variables.
- The authors apply this approach to analyze the information dynamics in various deep learning architectures and tasks.
Plain English Explanation
The authors of this paper have developed a new way to understand how deep learning models work under the hood. Deep learning models are complex algorithms that can learn to perform tasks like image recognition or language translation by analyzing large amounts of data. However, it's often difficult to see exactly how these models are processing information and making decisions.
The researchers' approach uses a concept called the "information plane" to visualize the flow of information through the different layers of a deep learning model. Imagine you have a deep learning model with many "hidden" layers between the input (e.g. an image) and the output (e.g. a classification). The information plane shows how much information is being preserved or transformed as it moves through these layers.
The key technique they use is called "transfer entropy," which measures how much information is being transferred between different parts of the model. By analyzing the transfer entropy, the researchers can create visual plots that reveal interesting patterns in how the model is learning and processing information.
This type of visualization can provide valuable insights for deep learning researchers and developers. It can help them better understand why a model is performing well or poorly, and guide them in designing more effective architectures and training procedures.
Technical Explanation
The paper presents a method for visualizing the "information plane" of deep learning models using transfer entropy. The information plane is a 2D plot that shows the mutual information (a measure of information content) between the model's input and each layer's activations.
To construct the information plane, the authors first compute the mutual information between the model input and each layer's activations. They then use a technique called transfer entropy to quantify the information flow between consecutive layers. Transfer entropy measures the reduction in uncertainty about a later variable (layer activations) given knowledge of an earlier variable (previous layer activations).
The authors apply this approach to analyze the information dynamics in various deep learning architectures, including fully connected networks, convolutional networks, and recurrent networks, across different tasks like image classification and language modeling. Their results reveal interesting patterns, such as the formation of an "information bottleneck" in the middle layers of deep networks.
Critical Analysis
The authors provide a compelling and well-executed approach for visualizing the information dynamics in deep learning models. The use of transfer entropy is a principled way to quantify information flow, and the resulting information plane visualizations offer valuable insights.
One potential limitation is that the method relies on estimating mutual information and transfer entropy from finite data, which can be challenging and subject to biases. The authors acknowledge this issue and discuss techniques they used to mitigate it, but further work may be needed to fully address the challenges of information-theoretic analysis of complex models.
Additionally, while the information plane visualizations are informative, it's not always clear how to directly translate these insights into practical improvements in model design or training. The authors discuss some potential applications, but more research may be needed to fully realize the potential of this approach.
Overall, this paper presents an interesting and important step forward in our understanding of deep learning models through the lens of information theory. The techniques developed here could inspire further research into interpretable and transparent deep learning systems.
Conclusion
This paper introduces a novel approach for visualizing the information dynamics in deep learning models using transfer entropy and the information plane. The authors demonstrate the application of this method to a variety of deep learning architectures and tasks, revealing insights about the flow of information through the different layers of these models.
The information plane visualizations provide a powerful tool for deep learning researchers and developers to better understand the inner workings of their models. This type of analysis can lead to the development of more interpretable and efficient deep learning systems, with potential impacts across many domains that rely on these powerful machine learning techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
0
0
Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
4/5/2024
🤿
Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
Ivan Butakov, Alexander Tolmachev, Sofia Malanchuk, Anna Neopryatnaya, Alexey Frolov, Kirill Andreev
0
0
The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target. According to the hypothesis put forth by Shwartz-Ziv & Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis was only partially verified for NNs of tiny sizes or specific types, such as quantized NNs. In this paper, we introduce a framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values and comparison with MINE (Belghazi et al., 2018). Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
5/10/2024
🏋️
End-to-End Training Induces Information Bottleneck through Layer-Role Differentiation: A Comparative Analysis with Layer-wise Training
Keitaro Sakamoto, Issei Sato
0
0
End-to-end (E2E) training, optimizing the entire model through error backpropagation, fundamentally supports the advancements of deep learning. Despite its high performance, E2E training faces the problems of memory consumption, parallel computing, and discrepancy with the functionalities of the actual brain. Various alternative methods have been proposed to overcome these difficulties; however, no one can yet match the performance of E2E training, thereby falling short in practicality. Furthermore, there is no deep understanding regarding differences in the trained model properties beyond the performance gap. In this paper, we reconsider why E2E training demonstrates a superior performance through a comparison with layer-wise training, a non-E2E method that locally sets errors. On the basis of the observation that E2E training has an advantage in propagating input information, we analyze the information plane dynamics of intermediate representations based on the Hilbert-Schmidt independence criterion (HSIC). The results of our normalized HSIC value analysis reveal the E2E training ability to exhibit different information dynamics across layers, in addition to efficient information propagation. Furthermore, we show that this layer-role differentiation leads to the final representation following the information bottleneck principle. It suggests the need to consider the cooperative interactions between layers, not just the final layer when analyzing the information bottleneck of deep learning.
6/3/2024
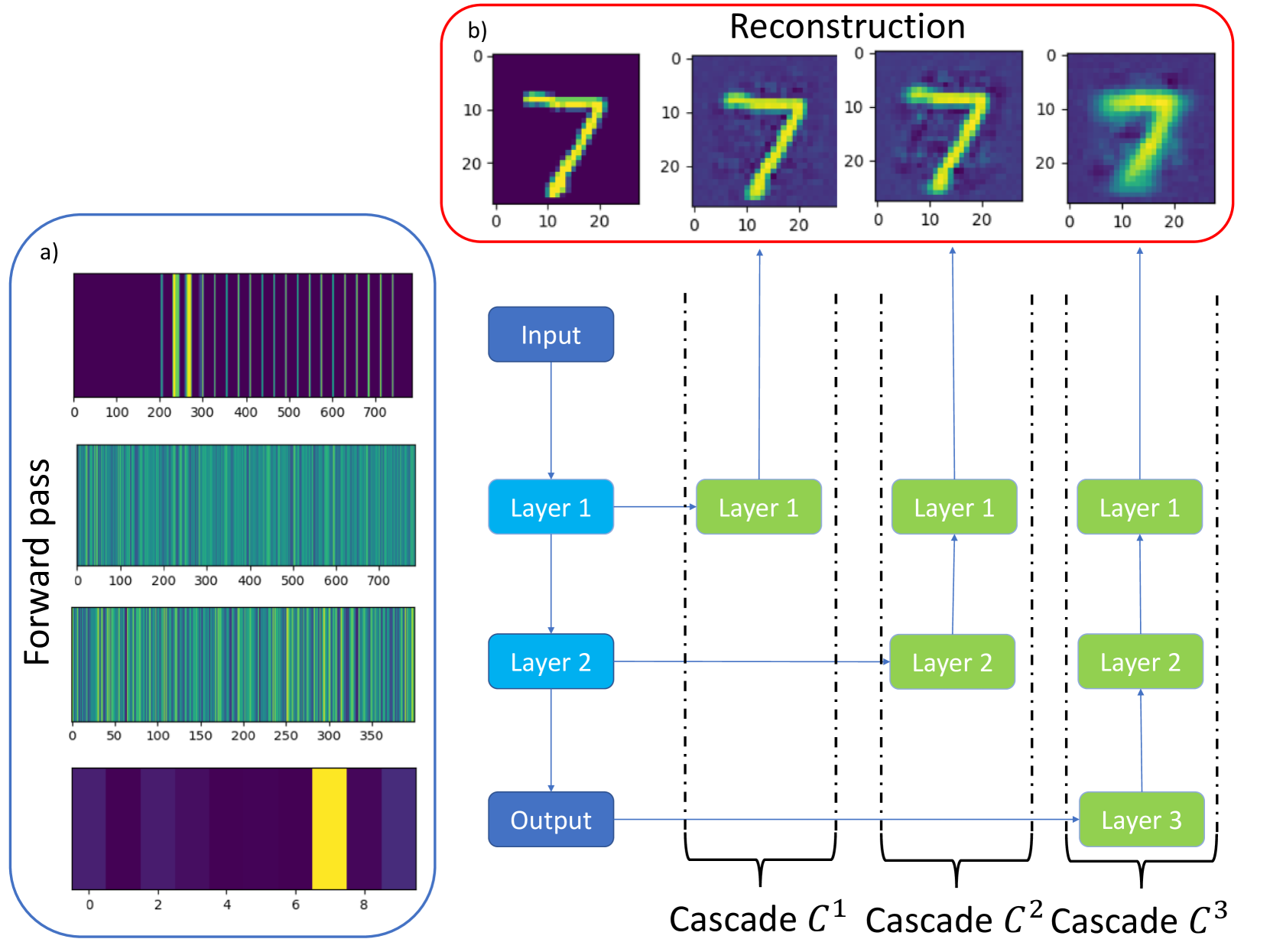
Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy
Yanick Thurn, Ro Jefferson, Johanna Erdmenger
0
0
An important challenge in machine learning is to predict the initial conditions under which a given neural network will be trainable. We present a method for predicting the trainable regime in parameter space for deep feedforward neural networks, based on reconstructing the input from subsequent activation layers via a cascade of single-layer auxiliary networks. For both MNIST and CIFAR10, we show that a single epoch of training of the shallow cascade networks is sufficient to predict the trainability of the deep feedforward network, thereby providing a significant reduction in overall training time. We achieve this by computing the relative entropy between reconstructed images and the original inputs, and show that this probe of information loss is sensitive to the phase behaviour of the network. Our results provide a concrete link between the flow of information and the trainability of deep neural networks, further elucidating the role of criticality in these systems.
6/21/2024