Delayed Bottlenecking: Alleviating Forgetting in Pre-trained Graph Neural Networks

0
Sign in to get full access
Overview
- This paper proposes a new approach called "Delayed Bottlenecking" to alleviate the issue of forgetting in pre-trained graph neural networks (GNNs).
- The authors argue that existing pre-training methods for GNNs can lead to a phenomenon called "forgetting", where the model loses important information from the pre-training task when fine-tuned on a downstream task.
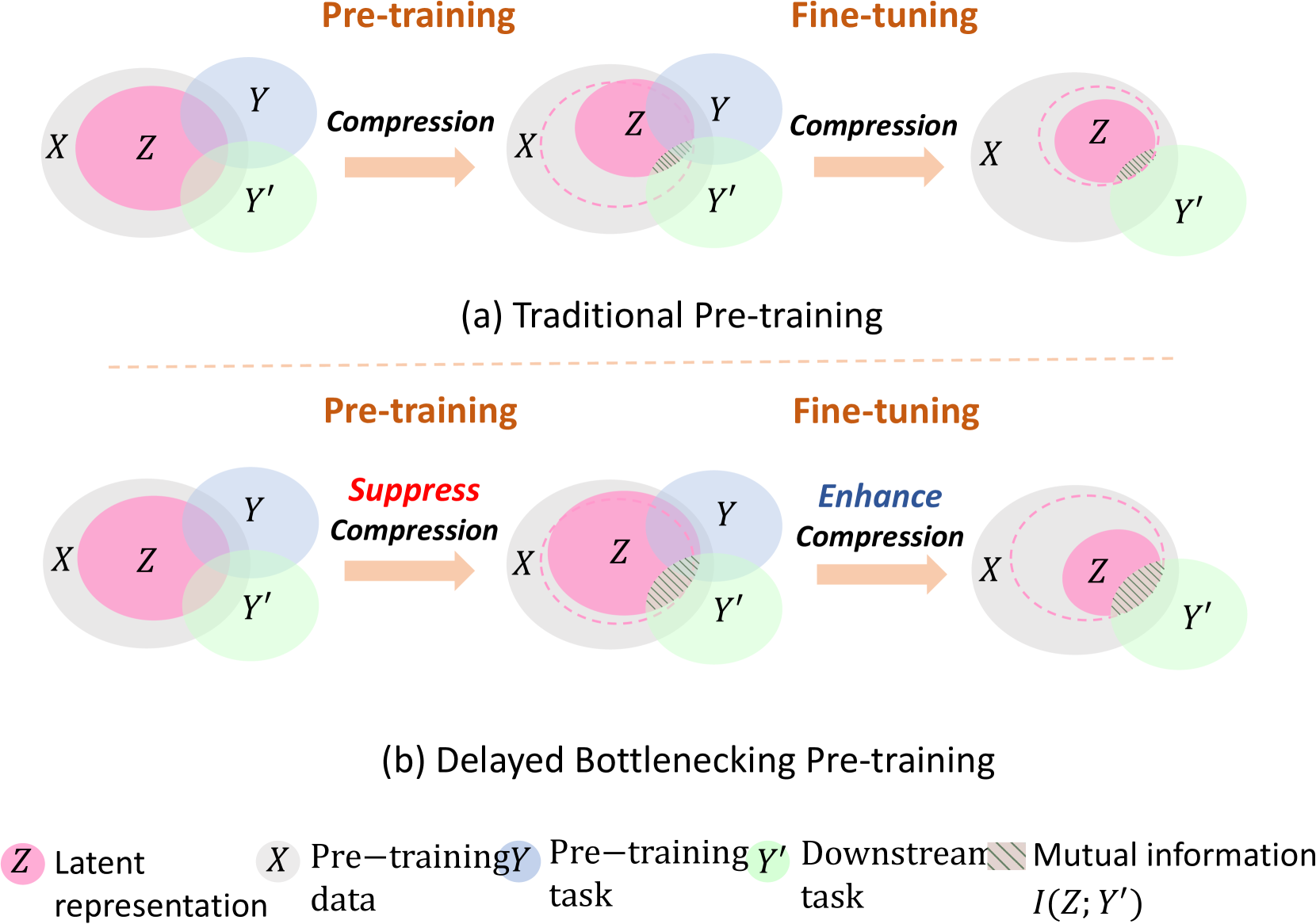
- The Delayed Bottlenecking approach aims to address this problem by introducing a novel information bottleneck mechanism that is gradually applied during fine-tuning, rather than being applied from the start.
Plain English Explanation
The paper focuses on a problem that can occur when using pre-trained graph neural networks. Pre-training is a technique where a model is first trained on a large, general dataset before being fine-tuned on a more specific task. This can be helpful, as the pre-training gives the model a good starting point and allows it to learn general patterns.
However, the authors of this paper found that with some pre-trained graph neural networks, the model can "forget" important information from the pre-training task when it is fine-tuned on a new task. This forgetting can hurt the model's performance on the new task.
To address this, the researchers developed a new approach called "Delayed Bottlenecking". The key idea is to gradually introduce an "information bottleneck" during the fine-tuning process, rather than applying it right away. This allows the model to retain more of the useful information it learned during pre-training, while still being able to adapt to the new task.
Technical Explanation
The paper introduces a novel approach called "Delayed Bottlenecking" to address the problem of forgetting in pre-trained graph neural networks. Existing pre-training methods for GNNs often rely on an information bottleneck, which compresses the model's representations to prevent overfitting. However, the authors argue that this bottleneck can also lead to the model forgetting important information from the pre-training task when fine-tuned on a new downstream task.
To mitigate this issue, the Delayed Bottlenecking approach gradually introduces the information bottleneck during the fine-tuning process, rather than applying it from the start. This allows the model to retain more of the useful knowledge acquired during pre-training, while still being able to adapt to the new task. The authors demonstrate the effectiveness of their approach through experiments on various graph classification benchmarks, showing that Delayed Bottlenecking can outperform standard fine-tuning and other baselines.
The paper also provides insights into the role of the information bottleneck in pre-training and fine-tuning of GNNs. The authors suggest that a gradual application of the bottleneck can help strike a better balance between preserving pre-trained knowledge and learning new task-specific features, leading to improved performance on downstream tasks.
Critical Analysis
The Delayed Bottlenecking approach proposed in this paper represents an interesting and valuable contribution to the field of graph neural network pre-training and fine-tuning. The authors have identified an important problem, namely the issue of forgetting in pre-trained GNNs, and have developed a novel solution to address it.
One potential limitation of the study is that it focuses primarily on graph classification tasks, and it would be interesting to see how the Delayed Bottlenecking approach performs on other types of graph-based problems, such as node classification or link prediction. Additionally, the paper does not provide a detailed theoretical analysis of the information bottleneck mechanism and its role in the forgetting phenomenon, which could be a valuable area for future research.
Furthermore, the authors could have considered additional baselines or comparisons to other techniques for alleviating forgetting in pre-trained models, such as continual learning or meta-learning approaches. These comparisons could help to further contextualize the contributions of the Delayed Bottlenecking method.
Overall, the paper presents a promising solution to an important problem in the field of graph neural networks, and the authors have demonstrated the effectiveness of their approach through empirical evaluations. Further research exploring the theoretical underpinnings and broader applicability of Delayed Bottlenecking could help to solidify its impact and inform the development of even more robust pre-training and fine-tuning techniques for GNNs.
Conclusion
This paper introduces a novel approach called "Delayed Bottlenecking" to address the issue of forgetting in pre-trained graph neural networks. The key innovation is the gradual application of an information bottleneck during the fine-tuning process, which helps the model retain more of the useful knowledge acquired during pre-training while still being able to adapt to a new downstream task.
The authors demonstrate the effectiveness of their approach through extensive experiments on various graph classification benchmarks, showing that Delayed Bottlenecking can outperform standard fine-tuning and other baselines. This work represents an important contribution to the field of graph neural networks, as it provides a practical solution to a common problem and offers insights into the role of the information bottleneck in pre-training and fine-tuning.
By alleviating the forgetting issue, the Delayed Bottlenecking method has the potential to unlock new applications and improve the performance of pre-trained GNNs across a wide range of domains. As the field of graph machine learning continues to evolve, this research serves as a valuable stepping stone towards more robust and adaptable model architectures and training techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Delayed Bottlenecking: Alleviating Forgetting in Pre-trained Graph Neural Networks
Zhe Zhao, Pengkun Wang, Xu Wang, Haibin Wen, Xiaolong Xie, Zhengyang Zhou, Qingfu Zhang, Yang Wang
Pre-training GNNs to extract transferable knowledge and apply it to downstream tasks has become the de facto standard of graph representation learning. Recent works focused on designing self-supervised pre-training tasks to extract useful and universal transferable knowledge from large-scale unlabeled data. However, they have to face an inevitable question: traditional pre-training strategies that aim at extracting useful information about pre-training tasks, may not extract all useful information about the downstream task. In this paper, we reexamine the pre-training process within traditional pre-training and fine-tuning frameworks from the perspective of Information Bottleneck (IB) and confirm that the forgetting phenomenon in pre-training phase may cause detrimental effects on downstream tasks. Therefore, we propose a novel underline{D}elayed underline{B}ottlenecking underline{P}re-training (DBP) framework which maintains as much as possible mutual information between latent representations and training data during pre-training phase by suppressing the compression operation and delays the compression operation to fine-tuning phase to make sure the compression can be guided with labeled fine-tuning data and downstream tasks. To achieve this, we design two information control objectives that can be directly optimized and further integrate them into the actual model design. Extensive experiments on both chemistry and biology domains demonstrate the effectiveness of DBP.
Read more4/24/2024
🌀
0
Unlearning Information Bottleneck: Machine Unlearning of Systematic Patterns and Biases
Ling Han, Hao Huang, Dustin Scheinost, Mary-Anne Hartley, Mar'ia Rodr'iguez Mart'inez
Effective adaptation to distribution shifts in training data is pivotal for sustaining robustness in neural networks, especially when removing specific biases or outdated information, a process known as machine unlearning. Traditional approaches typically assume that data variations are random, which makes it difficult to adjust the model parameters accurately to remove patterns and characteristics from unlearned data. In this work, we present Unlearning Information Bottleneck (UIB), a novel information-theoretic framework designed to enhance the process of machine unlearning that effectively leverages the influence of systematic patterns and biases for parameter adjustment. By proposing a variational upper bound, we recalibrate the model parameters through a dynamic prior that integrates changes in data distribution with an affordable computational cost, allowing efficient and accurate removal of outdated or unwanted data patterns and biases. Our experiments across various datasets, models, and unlearning methods demonstrate that our approach effectively removes systematic patterns and biases while maintaining the performance of models post-unlearning.
Read more5/24/2024
🤿
0
Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
Ivan Butakov, Alexander Tolmachev, Sofia Malanchuk, Anna Neopryatnaya, Alexey Frolov, Kirill Andreev
The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: between the hidden layer output and the DNN input/target. According to the hypothesis put forth by Shwartz-Ziv & Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis was only partially verified for NNs of tiny sizes or specific types, such as quantized NNs. In this paper, we introduce a framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values and comparison with MINE (Belghazi et al., 2018). Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
Read more5/10/2024

0
GINTRIP: Interpretable Temporal Graph Regression using Information bottleneck and Prototype-based method
Ali Royat, Seyed Mohamad Moghadas, Lesley De Cruz, Adrian Munteanu
Deep neural networks (DNNs) have demonstrated remarkable performance across various domains, yet their application to temporal graph regression tasks faces significant challenges regarding interpretability. This critical issue, rooted in the inherent complexity of both DNNs and underlying spatio-temporal patterns in the graph, calls for innovative solutions. While interpretability concerns in Graph Neural Networks (GNNs) mirror those of DNNs, to the best of our knowledge, no notable work has addressed the interpretability of temporal GNNs using a combination of Information Bottleneck (IB) principles and prototype-based methods. Our research introduces a novel approach that uniquely integrates these techniques to enhance the interpretability of temporal graph regression models. The key contributions of our work are threefold: We introduce the underline{G}raph underline{IN}terpretability in underline{T}emporal underline{R}egression task using underline{I}nformation bottleneck and underline{P}rototype (GINTRIP) framework, the first combined application of IB and prototype-based methods for interpretable temporal graph tasks. We derive a novel theoretical bound on mutual information (MI), extending the applicability of IB principles to graph regression tasks. We incorporate an unsupervised auxiliary classification head, fostering multi-task learning and diverse concept representation, which enhances the model bottleneck's interpretability. Our model is evaluated on real-world traffic datasets, outperforming existing methods in both forecasting accuracy and interpretability-related metrics.
Read more9/18/2024