Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy

0
Sign in to get full access
Overview
- This paper explores a new method for predicting the trainability of deep neural networks using a metric called "reconstruction entropy".
- The researchers found that reconstruction entropy, which measures the amount of information lost when compressing the network's internal representations, can be used to predict how well a neural network will perform on a given task.
- This provides a way to "open the black box" of deep learning models and gain insights into their training dynamics and performance potential.
Plain English Explanation
The researchers in this paper investigated a new way to understand how well deep neural networks can be trained to perform a task. Deep neural networks are powerful machine learning models that can learn complex patterns in data, but they are often treated as "black boxes" - it's difficult to know exactly how they work or why they perform well or poorly on a given task.
To address this, the researchers looked at a concept called "reconstruction entropy". This measures how much information is lost when the internal representations (the patterns the network learns) are compressed. The key insight is that networks that can be compressed more efficiently - that is, they have lower reconstruction entropy - are likely to be easier to train and perform better on the task.
By calculating the reconstruction entropy of a network before training, the researchers found they could predict how well the network would end up performing. This provides a new tool for "opening the black box" of deep learning models and understanding their training dynamics and performance potential.
The researchers validated their approach by testing it on several common deep learning tasks and architectures, and found that reconstruction entropy was consistently a good predictor of trainability. This suggests reconstruction entropy could be a useful metric for designing and optimizing deep learning models in the future.
Technical Explanation
The core idea of the paper is to use a metric called "reconstruction entropy" to predict the trainability of deep neural networks. Reconstruction entropy measures the amount of information lost when compressing the internal representations (activations) of a network.
The researchers hypothesized that networks with lower reconstruction entropy would be easier to train and perform better, since they can be represented more efficiently. To test this, they trained a variety of common deep learning models, including convolutional and recurrent neural networks, on benchmark tasks.
Before training, they calculated the reconstruction entropy of each network by encoding the activations to a lower-dimensional space and then reconstructing them. They found that the reconstruction entropy correlated strongly with the final performance of the trained models, across different architectures and tasks.
The intuition is that networks with lower reconstruction entropy have learned more compressed, efficient representations of the input data. This makes them easier for the optimization process (e.g. gradient descent) to navigate, leading to better training performance and generalization.
The researchers also visualized the "information plane" of the networks - how the mutual information between the inputs and internal representations changes during training. They found that networks with lower reconstruction entropy tended to traverse the information plane more efficiently, further validating the connection between compression and trainability.
Critical Analysis
The key strength of this work is that it provides a principled, information-theoretic lens for understanding the trainability of deep neural networks. By quantifying the compressibility of a network's internal representations, the reconstruction entropy metric offers a new way to "open the black box" of deep learning.
That said, there are some limitations and caveats to consider:
- The paper focuses on standard supervised learning tasks and architectures. It's unclear how well the reconstruction entropy approach would generalize to more complex settings like reinforcement learning or unsupervised representation learning.
- The experiments are primarily conducted on relatively small-scale datasets and networks. Further testing on larger, more challenging benchmarks would help validate the broader applicability of the method.
- The reconstruction entropy calculation itself requires estimating mutual information, which can be challenging and computationally expensive, especially for large networks. More efficient approximation techniques may be needed for practical use.
Additionally, while the information plane visualizations provide intuitive insights, they don't necessarily reveal the full picture. There may be other geometric or topological properties of the learned representations that also play a role in trainability, which are not captured by reconstruction entropy alone.
Overall, this work represents an important step towards a deeper understanding of deep neural network optimization and performance. By connecting compressibility to trainability, it opens up new directions for network design, architecture search, and training algorithm development. Further research is needed to fully realize the potential of this approach.
Conclusion
This paper introduces a novel metric called "reconstruction entropy" that can be used to predict the trainability of deep neural networks. By quantifying the compressibility of a network's internal representations, reconstruction entropy provides a principled, information-theoretic way to "open the black box" of deep learning models.
The researchers demonstrated that reconstruction entropy correlates strongly with the final performance of trained models across a variety of architectures and tasks. This suggests reconstruction entropy could be a valuable tool for designing and optimizing deep learning systems, by helping to identify architectures and hyperparameters that are more amenable to efficient training and generalization.
While further research is needed to fully understand the broader implications and limitations of this approach, this work represents an important step towards a deeper, more transparent understanding of how deep neural networks learn. By connecting the compressibility of learned representations to trainability, it opens up new avenues for advancing the state of the art in deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Opening the Black Box: predicting the trainability of deep neural networks with reconstruction entropy
Yanick Thurn, Ro Jefferson, Johanna Erdmenger
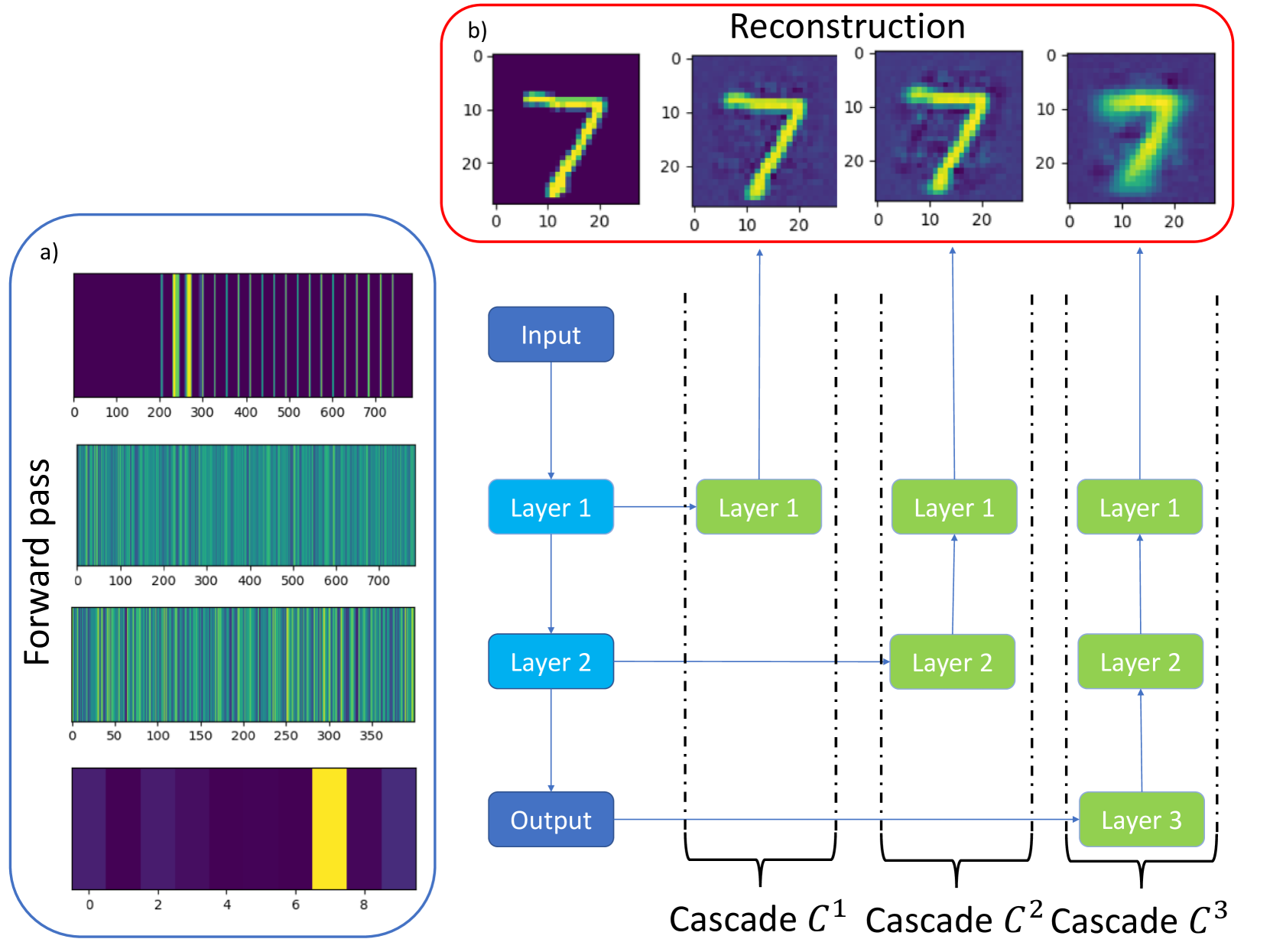
An important challenge in machine learning is to predict the initial conditions under which a given neural network will be trainable. We present a method for predicting the trainable regime in parameter space for deep feedforward neural networks, based on reconstructing the input from subsequent activation layers via a cascade of single-layer auxiliary networks. For both the MNIST and CIFAR10 datasets, we show that a single epoch of training of the shallow cascade networks is sufficient to predict the trainability of the deep feedforward network, thereby providing a significant reduction in overall training time. We achieve this by computing the relative entropy between reconstructed images and the original inputs, and show that this probe of information loss is sensitive to the phase behaviour of the network. Moreover, our approach illustrates the network's decision making process by displaying the changes performed on the input data at each layer. Our results provide a concrete link between the flow of information and the trainability of deep neural networks, further explaining the role of criticality in these systems.
Read more8/12/2024
🤿
0
Entropy-based Guidance of Deep Neural Networks for Accelerated Convergence and Improved Performance
Mackenzie J. Meni, Ryan T. White, Michael Mayo, Kevin Pilkiewicz
Neural networks have dramatically increased our capacity to learn from large, high-dimensional datasets across innumerable disciplines. However, their decisions are not easily interpretable, their computational costs are high, and building and training them are not straightforward processes. To add structure to these efforts, we derive new mathematical results to efficiently measure the changes in entropy as fully-connected and convolutional neural networks process data. By measuring the change in entropy as networks process data effectively, patterns critical to a well-performing network can be visualized and identified. Entropy-based loss terms are developed to improve dense and convolutional model accuracy and efficiency by promoting the ideal entropy patterns. Experiments in image compression, image classification, and image segmentation on benchmark datasets demonstrate these losses guide neural networks to learn rich latent data representations in fewer dimensions, converge in fewer training epochs, and achieve higher accuracy.
Read more7/8/2024

0
The Simpler The Better: An Entropy-Based Importance Metric To Reduce Neural Networks' Depth
Victor Qu'etu, Zhu Liao, Enzo Tartaglione
While deep neural networks are highly effective at solving complex tasks, large pre-trained models are commonly employed even to solve consistently simpler downstream tasks, which do not necessarily require a large model's complexity. Motivated by the awareness of the ever-growing AI environmental impact, we propose an efficiency strategy that leverages prior knowledge transferred by large models. Simple but effective, we propose a method relying on an Entropy-bASed Importance mEtRic (EASIER) to reduce the depth of over-parametrized deep neural networks, which alleviates their computational burden. We assess the effectiveness of our method on traditional image classification setups. Our code is available at https://github.com/VGCQ/EASIER.
Read more6/6/2024

0
Learning in Convolutional Neural Networks Accelerated by Transfer Entropy
Adrian Moldovan, Angel Cac{t}aron, Ru{a}zvan Andonie
Recently, there is a growing interest in applying Transfer Entropy (TE) in quantifying the effective connectivity between artificial neurons. In a feedforward network, the TE can be used to quantify the relationships between neuron output pairs located in different layers. Our focus is on how to include the TE in the learning mechanisms of a Convolutional Neural Network (CNN) architecture. We introduce a novel training mechanism for CNN architectures which integrates the TE feedback connections. Adding the TE feedback parameter accelerates the training process, as fewer epochs are needed. On the flip side, it adds computational overhead to each epoch. According to our experiments on CNN classifiers, to achieve a reasonable computational overhead--accuracy trade-off, it is efficient to consider only the inter-neural information transfer of a random subset of the neuron pairs from the last two fully connected layers. The TE acts as a smoothing factor, generating stability and becoming active only periodically, not after processing each input sample. Therefore, we can consider the TE is in our model a slowly changing meta-parameter.
Read more4/5/2024