Infusion: internal diffusion for inpainting of dynamic textures and complex motion

0
🗣️
Sign in to get full access
Overview
- Video inpainting is the task of filling in missing or corrupted regions in a video.
- It is very challenging due to the high dimensionality of the data and the need for temporal consistency.
- Diffusion models have shown impressive results in modeling complex data, but are computationally expensive.
- This paper proposes an internal learning approach to video inpainting using diffusion models.
Plain English Explanation
Video inpainting is the process of filling in missing or damaged parts of a video in a way that looks natural and convincing. This is a difficult task because videos contain a lot of information and the filled-in parts need to match the movement and timing of the rest of the video.
Diffusion models are a type of machine learning model that have been very successful at generating complex data like images and videos. However, these models are also very computationally intensive, making them impractical for working with real-world videos.
This paper shows that by focusing the training of the diffusion model on just the input video itself, rather than a large dataset, the model can be made much smaller and faster. This "internal learning" approach allows the diffusion model to effectively fill in missing parts of the video without requiring a lot of computing power.
The key insight is that videos often contain a lot of repetition and self-similarity, so the model only needs to learn the patterns present in the input video, rather than having to learn all possible patterns from a large dataset. This makes the model much more efficient.
The paper also introduces a new training and inference method for diffusion models that further improves their performance on video inpainting tasks, especially for videos with complex motions and textures.
Technical Explanation
Diffusion models have shown impressive results at modeling complex data distributions, including images and videos. However, these models are computationally expensive, both in terms of training and inference, limiting their applicability to video tasks.
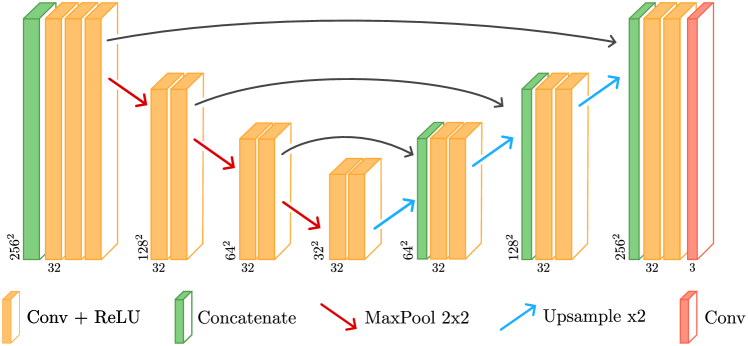
The key insight of this paper is that in the case of video inpainting, the highly auto-similar nature of videos means the training data can be restricted to the input video itself, while still producing very satisfying results. This leads the authors to adopt an internal learning approach, which allows them to greatly reduce the size of the neural network, by about three orders of magnitude compared to current diffusion models used for image inpainting.
The paper also introduces a new method for efficient training and inference of diffusion models in the context of internal learning. This involves splitting the diffusion process into different learning intervals corresponding to different noise levels, further improving performance.
To the best of the authors' knowledge, this is the first video inpainting method based purely on diffusion, without requiring additional components such as optical flow estimation, which can limit performance on dynamic textures and complex motions.
Critical Analysis
The internal learning approach taken in this paper is a clever way to make diffusion models more practical for video inpainting tasks. By focusing the training on just the input video, the model complexity and computational requirements are greatly reduced.
However, it's worth considering whether this approach would generalize well to a wider range of video content. The authors note that videos often exhibit a high degree of self-similarity, which enables the internal learning approach to work effectively. But it's unclear how well the method would perform on more diverse or less repetitive video data.
Additionally, the paper does not provide a detailed analysis of failure cases or limitations of the proposed method. It would be helpful to understand the types of videos or inpainting challenges where the approach may struggle, and how it compares to other video inpainting techniques in these scenarios.
Overall, the paper presents an innovative and promising direction for making diffusion models more practical for video-related tasks. Further research exploring the broader applicability and limitations of this internal learning approach would be valuable.
Conclusion
This paper introduces a novel video inpainting method based on diffusion models that leverages the self-similar nature of videos to greatly reduce the computational cost and complexity of the model. By restricting the training data to the input video itself, the authors are able to create a much smaller and more efficient diffusion model that can still produce high-quality results.
The key contribution is the internal learning approach, which allows the diffusion model to effectively learn the patterns present in the input video without needing to model the full complexity of all possible video content. This, combined with a new training and inference method, enables the proposed technique to outperform state-of-the-art video inpainting approaches, particularly on dynamic textures and complex motions.
While the paper does not address all potential limitations or failure cases, it presents a promising direction for making diffusion models more practical and accessible for real-world video processing tasks. Further research exploring the broader applicability and robustness of this internal learning approach could lead to significant advances in the field of video inpainting and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Infusion: internal diffusion for inpainting of dynamic textures and complex motion
Nicolas Cherel, Andr'es Almansa, Yann Gousseau, Alasdair Newson
Video inpainting is the task of filling a region in a video in a visually convincing manner. It is very challenging due to the high dimensionality of the data and the temporal consistency required for obtaining convincing results. Recently, diffusion models have shown impressive results in modeling complex data distributions, including images and videos. Such models remain nonetheless very expensive to train and to perform inference with, which strongly reduce their applicability to videos, and yields unreasonable computational loads. We show that in the case of video inpainting, thanks to the highly auto-similar nature of videos, the training data of a diffusion model can be restricted to the input video and still produce very satisfying results. This leads us to adopt an internal learning approach, which also allows us to greatly reduce the neural network size by about three orders of magnitude less than current diffusion models used for image inpainting. We also introduce a new method for efficient training and inference of diffusion models in the context of internal learning, by splitting the diffusion process into different learning intervals corresponding to different noise levels of the diffusion process. To the best of our knowledge, this is the first video inpainting method based purely on diffusion. Other methods require additional components such as optical flow estimation, which limits their performance in the case of dynamic textures and complex motions. We show qualitative and quantitative results, demonstrating that our method reaches state of the art performance in the case of dynamic textures and complex dynamic backgrounds.
Read more8/29/2024
0
Diffusion-based image inpainting with internal learning
Nicolas Cherel, Andr'es Almansa, Yann Gousseau, Alasdair Newson
Diffusion models are now the undisputed state-of-the-art for image generation and image restoration. However, they require large amounts of computational power for training and inference. In this paper, we propose lightweight diffusion models for image inpainting that can be trained on a single image, or a few images. We show that our approach competes with large state-of-the-art models in specific cases. We also show that training a model on a single image is particularly relevant for image acquisition modality that differ from the RGB images of standard learning databases. We show results in three different contexts: texture images, line drawing images, and materials BRDF, for which we achieve state-of-the-art results in terms of realism, with a computational load that is greatly reduced compared to concurrent methods.
Read more6/7/2024
📶
0
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Dylan Green, William Harvey, Saeid Naderiparizi, Matthew Niedoba, Yunpeng Liu, Xiaoxuan Liang, Jonathan Lavington, Ke Zhang, Vasileios Lioutas, Setareh Dabiri, Adam Scibior, Berend Zwartsenberg, Frank Wood
Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Read more5/2/2024

0
Video Diffusion Models are Strong Video Inpainter
Minhyeok Lee, Suhwan Cho, Chajin Shin, Jungho Lee, Sunghun Yang, Sangyoun Lee
Propagation-based video inpainting using optical flow at the pixel or feature level has recently garnered significant attention. However, it has limitations such as the inaccuracy of optical flow prediction and the propagation of noise over time. These issues result in non-uniform noise and time consistency problems throughout the video, which are particularly pronounced when the removed area is large and involves substantial movement. To address these issues, we propose a novel First Frame Filling Video Diffusion Inpainting model (FFF-VDI). We design FFF-VDI inspired by the capabilities of pre-trained image-to-video diffusion models that can transform the first frame image into a highly natural video. To apply this to the video inpainting task, we propagate the noise latent information of future frames to fill the masked areas of the first frame's noise latent code. Next, we fine-tune the pre-trained image-to-video diffusion model to generate the inpainted video. The proposed model addresses the limitations of existing methods that rely on optical flow quality, producing much more natural and temporally consistent videos. This proposed approach is the first to effectively integrate image-to-video diffusion models into video inpainting tasks. Through various comparative experiments, we demonstrate that the proposed model can robustly handle diverse inpainting types with high quality.
Read more9/4/2024